 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepResearchGym: A Free, Transparent, and Reproducible Evaluation Sandbox for Deep Research
May 25, 2025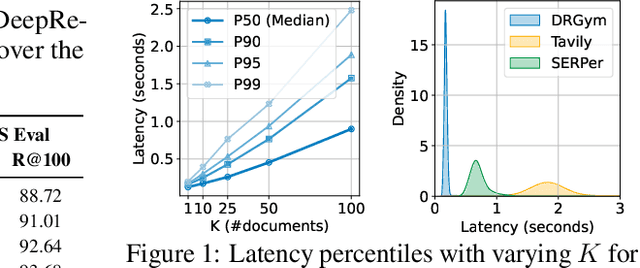
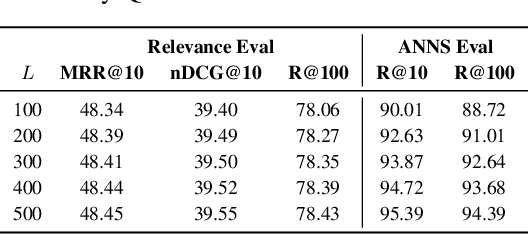
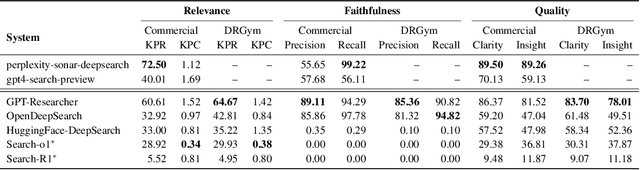
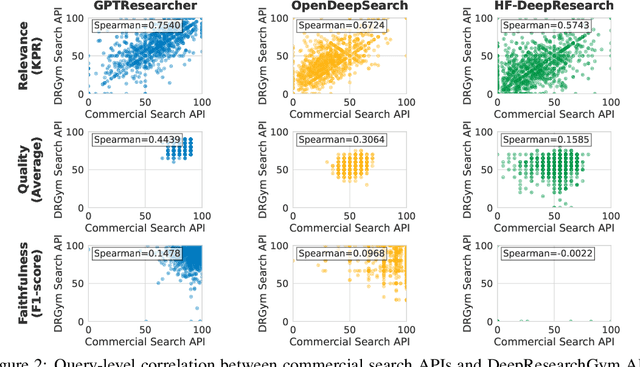
Deep research systems represent an emerging class of agentic information retrieval methods that generate comprehensive and well-supported reports to complex queries. However, most existing frameworks rely on dynamic commercial search APIs, which pose reproducibility and transparency challenges in addition to their cost. To address these limitations, we introduce DeepResearchGym, an open-source sandbox that combines a reproducible search API with a rigorous evaluation protocol for benchmarking deep research systems. The API indexes large-scale public web corpora, namely ClueWeb22 and FineWeb, using a state-of-the-art dense retriever and approximate nearest neighbor search via DiskANN. It achieves lower latency than popular commercial APIs while ensuring stable document rankings across runs, and is freely available for research use. To evaluate deep research systems' outputs, we extend the Researchy Questions benchmark with automatic metrics through LLM-as-a-judge assessments to measure alignment with users' information needs, retrieval faithfulness, and report quality. Experimental results show that systems integrated with DeepResearchGym achieve performance comparable to those using commercial APIs, with performance rankings remaining consistent across evaluation metrics. A human evaluation study further confirms that our automatic protocol aligns with human preferences, validating the framework's ability to help support controlled assessment of deep research systems. Our code and API documentation are available at https://www.deepresearchgym.ai.
Efficient Agent Training for Computer Use
May 20, 2025



Scaling up high-quality trajectory data has long been a critical bottleneck for developing human-like computer use agents. We introduce PC Agent-E, an efficient agent training framework that significantly reduces reliance on large-scale human demonstrations. Starting with just 312 human-annotated computer use trajectories, we further improved data quality by synthesizing diverse action decisions with Claude 3.7 Sonnet. Trained on these enriched trajectories, our PC Agent-E model achieved a remarkable 141% relative improvement, surpassing the strong Claude 3.7 Sonnet with extended thinking on WindowsAgentArena-V2, an improved benchmark we also released. Furthermore, PC Agent-E demonstrates strong generalizability to different operating systems on OSWorld. Our findings suggest that strong computer use capabilities can be stimulated from a small amount of high-quality trajectory data.
Generative AI Act II: Test Time Scaling Drives Cognition Engineering
Apr 21, 2025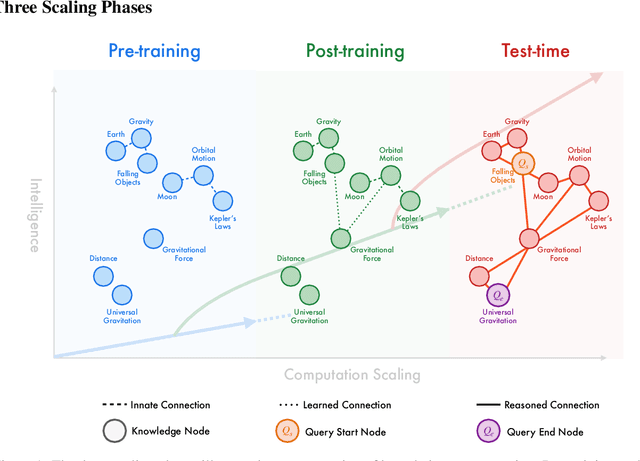
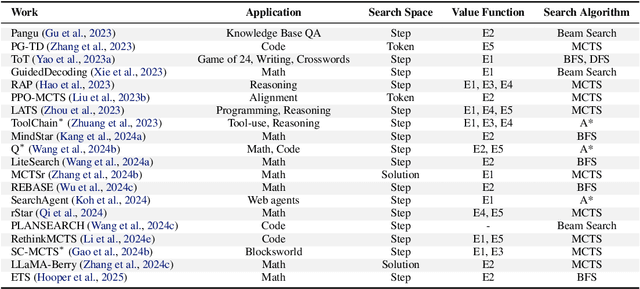
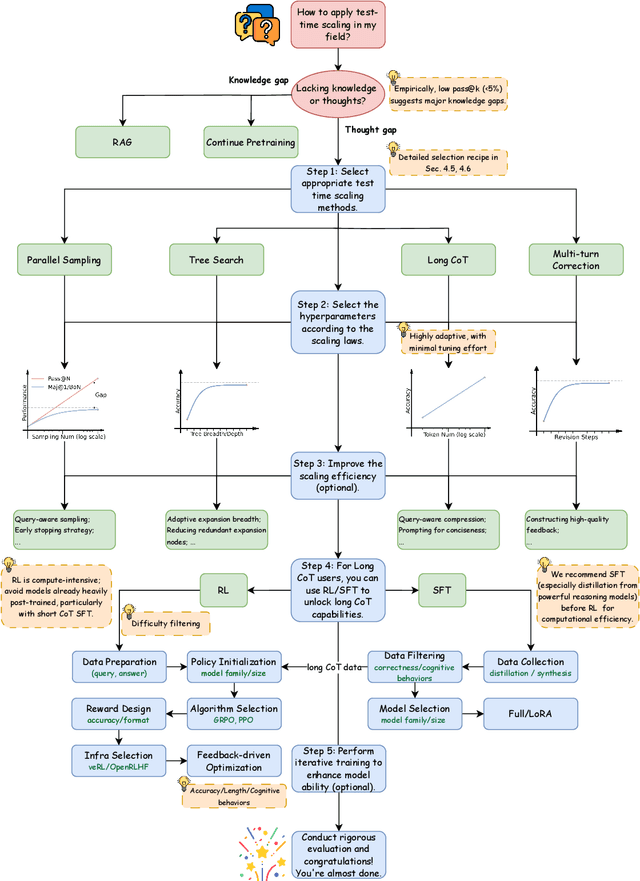
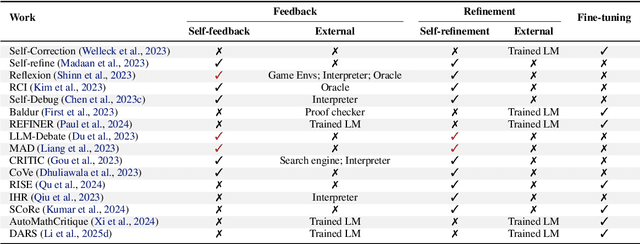
The first generation of Large Language Models - what might be called "Act I" of generative AI (2020-2023) - achieved remarkable success through massive parameter and data scaling, yet exhibited fundamental limitations such as knowledge latency, shallow reasoning, and constrained cognitive processes. During this era, prompt engineering emerged as our primary interface with AI, enabling dialogue-level communication through natural language. We now witness the emergence of "Act II" (2024-present), where models are transitioning from knowledge-retrieval systems (in latent space) to thought-construction engines through test-time scaling techniques. This new paradigm establishes a mind-level connection with AI through language-based thoughts. In this paper, we clarify the conceptual foundations of cognition engineering and explain why this moment is critical for its development. We systematically break down these advanced approaches through comprehensive tutorials and optimized implementations, democratizing access to cognition engineering and enabling every practitioner to participate in AI's second act. We provide a regularly updated collection of papers on test-time scaling in the GitHub Repository: https://github.com/GAIR-NLP/cognition-engineering
Revisiting 3D LLM Benchmarks: Are We Really Testing 3D Capabilities?
Feb 12, 2025



In this work, we identify the "2D-Cheating" problem in 3D LLM evaluation, where these tasks might be easily solved by VLMs with rendered images of point clouds, exposing ineffective evaluation of 3D LLMs' unique 3D capabilities. We test VLM performance across multiple 3D LLM benchmarks and, using this as a reference, propose principles for better assessing genuine 3D understanding. We also advocate explicitly separating 3D abilities from 1D or 2D aspects when evaluating 3D LLMs.
PC Agent: While You Sleep, AI Works -- A Cognitive Journey into Digital World
Dec 23, 2024



Imagine a world where AI can handle your work while you sleep - organizing your research materials, drafting a report, or creating a presentation you need for tomorrow. However, while current digital agents can perform simple tasks, they are far from capable of handling the complex real-world work that humans routinely perform. We present PC Agent, an AI system that demonstrates a crucial step toward this vision through human cognition transfer. Our key insight is that the path from executing simple "tasks" to handling complex "work" lies in efficiently capturing and learning from human cognitive processes during computer use. To validate this hypothesis, we introduce three key innovations: (1) PC Tracker, a lightweight infrastructure that efficiently collects high-quality human-computer interaction trajectories with complete cognitive context; (2) a two-stage cognition completion pipeline that transforms raw interaction data into rich cognitive trajectories by completing action semantics and thought processes; and (3) a multi-agent system combining a planning agent for decision-making with a grounding agent for robust visual grounding. Our preliminary experiments in PowerPoint presentation creation reveal that complex digital work capabilities can be achieved with a small amount of high-quality cognitive data - PC Agent, trained on just 133 cognitive trajectories, can handle sophisticated work scenarios involving up to 50 steps across multiple applications. This demonstrates the data efficiency of our approach, highlighting that the key to training capable digital agents lies in collecting human cognitive data. By open-sourcing our complete framework, including the data collection infrastructure and cognition completion methods, we aim to lower the barriers for the research community to develop truly capable digital agents.
BeHonest: Benchmarking Honesty of Large Language Models
Jun 19, 2024Previous works on Large Language Models (LLMs) have mainly focused on evaluating their helpfulness or harmlessness. However, honesty, another crucial alignment criterion, has received relatively less attention. Dishonest behaviors in LLMs, such as spreading misinformation and defrauding users, eroding user trust, and causing real-world harm, present severe risks that intensify as these models approach superintelligence levels. Enhancing honesty in LLMs addresses critical deficiencies and helps uncover latent capabilities that are not readily expressed. This underscores the urgent need for reliable methods and benchmarks to effectively ensure and evaluate the honesty of LLMs. In this paper, we introduce BeHonest, a pioneering benchmark specifically designed to assess honesty in LLMs comprehensively. BeHonest evaluates three essential aspects of honesty: awareness of knowledge boundaries, avoidance of deceit, and consistency in responses. Building on this foundation, we designed 10 scenarios to evaluate and analyze 9 popular LLMs on the market, including both closed-source and open-source models from different model families with varied model sizes. Our findings indicate that there is still significant room for improvement in the honesty of LLMs. We also encourage the AI community to prioritize honesty alignment in LLMs. Our benchmark and code can be found at: \url{https://github.com/GAIR-NLP/BeHonest}.