 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualEdit: Dual Editing for Knowledge Updating in Vision-Language Models
Jun 16, 2025Model editing aims to efficiently update a pre-trained model's knowledge without the need for time-consuming full retraining. While existing pioneering editing methods achieve promising results, they primarily focus on editing single-modal language models (LLMs). However, for vision-language models (VLMs), which involve multiple modalities, the role and impact of each modality on editing performance remain largely unexplored. To address this gap, we explore the impact of textual and visual modalities on model editing and find that: (1) textual and visual representations reach peak sensitivity at different layers, reflecting their varying importance; and (2) editing both modalities can efficiently update knowledge, but this comes at the cost of compromising the model's original capabilities. Based on our findings, we propose DualEdit, an editor that modifies both textual and visual modalities at their respective key layers. Additionally, we introduce a gating module within the more sensitive textual modality, allowing DualEdit to efficiently update new knowledge while preserving the model's original information. We evaluate DualEdit across multiple VLM backbones and benchmark datasets, demonstrating its superiority over state-of-the-art VLM editing baselines as well as adapted LLM editing methods on different evaluation metrics.
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Aug 15, 2024



Despite Retrieval-Augmented Generation (RAG) has shown promising capability in leveraging external knowledge, a comprehensive evaluation of RAG systems is still challenging due to the modular nature of RAG, evaluation of long-form responses and reliability of measurements. In this paper, we propose a fine-grained evaluation framework, RAGChecker, that incorporates a suite of diagnostic metrics for both the retrieval and generation modules. Meta evaluation verifies that RAGChecker has significantly better correlations with human judgments than other evaluation metrics. Using RAGChecker, we evaluate 8 RAG systems and conduct an in-depth analysis of their performance, revealing insightful patterns and trade-offs in the design choices of RAG architectures. The metrics of RAGChecker can guide researchers and practitioners in developing more effective RAG systems.
OpenResearcher: Unleashing AI for Accelerated Scientific Research
Aug 13, 2024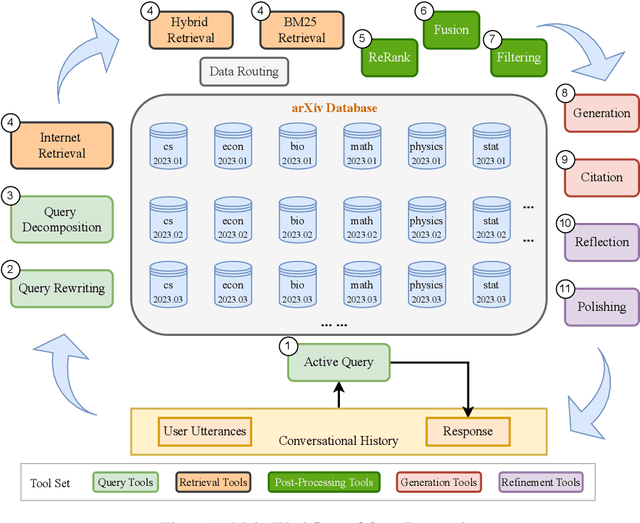
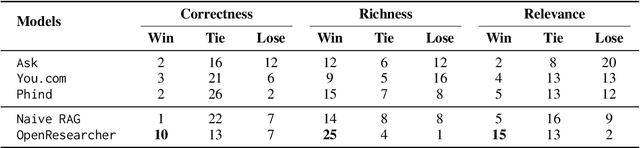
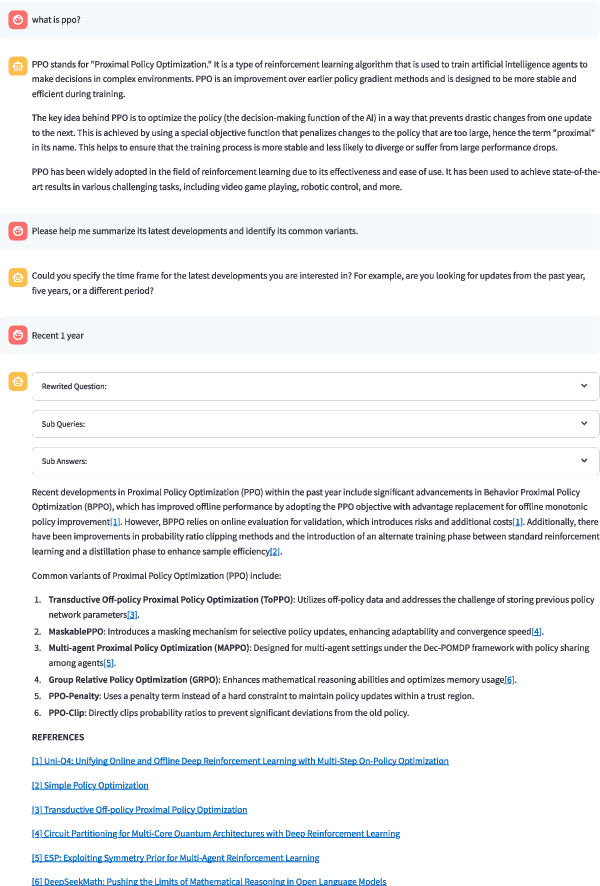
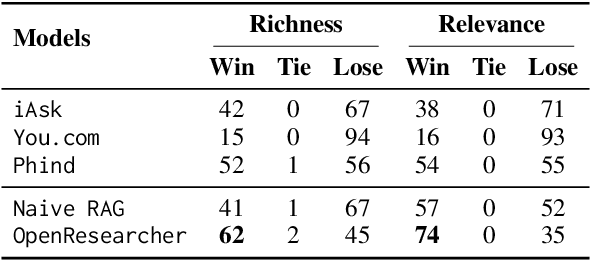
The rapid growth of scientific literature imposes significant challenges for researchers endeavoring to stay updated with the latest advancements in their fields and delve into new areas. We introduce OpenResearcher, an innovative platform that leverages Artificial Intelligence (AI) techniques to accelerate the research process by answering diverse questions from researchers. OpenResearcher is built based on Retrieval-Augmented Generation (RAG) to integrate Large Language Models (LLMs) with up-to-date, domain-specific knowledge. Moreover, we develop various tools for OpenResearcher to understand researchers' queries, search from the scientific literature, filter retrieved information, provide accurate and comprehensive answers, and self-refine these answers. OpenResearcher can flexibly use these tools to balance efficiency and effectiveness. As a result, OpenResearcher enables researchers to save time and increase their potential to discover new insights and drive scientific breakthroughs. Demo, video, and code are available at: https://github.com/GAIR-NLP/OpenResearcher.
Halu-J: Critique-Based Hallucination Judge
Jul 17, 2024Large language models (LLMs) frequently generate non-factual content, known as hallucinations. Existing retrieval-augmented-based hallucination detection approaches typically address this by framing it as a classification task, evaluating hallucinations based on their consistency with retrieved evidence. However, this approach usually lacks detailed explanations for these evaluations and does not assess the reliability of these explanations. Furthermore, deficiencies in retrieval systems can lead to irrelevant or partially relevant evidence retrieval, impairing the detection process. Moreover, while real-world hallucination detection requires analyzing multiple pieces of evidence, current systems usually treat all evidence uniformly without considering its relevance to the content. To address these challenges, we introduce Halu-J, a critique-based hallucination judge with 7 billion parameters. Halu-J enhances hallucination detection by selecting pertinent evidence and providing detailed critiques. Our experiments indicate that Halu-J outperforms GPT-4o in multiple-evidence hallucination detection and matches its capability in critique generation and evidence selection. We also introduce ME-FEVER, a new dataset designed for multiple-evidence hallucination detection. Our code and dataset can be found in https://github.com/GAIR-NLP/factool .
BeHonest: Benchmarking Honesty of Large Language Models
Jun 19, 2024Previous works on Large Language Models (LLMs) have mainly focused on evaluating their helpfulness or harmlessness. However, honesty, another crucial alignment criterion, has received relatively less attention. Dishonest behaviors in LLMs, such as spreading misinformation and defrauding users, eroding user trust, and causing real-world harm, present severe risks that intensify as these models approach superintelligence levels. Enhancing honesty in LLMs addresses critical deficiencies and helps uncover latent capabilities that are not readily expressed. This underscores the urgent need for reliable methods and benchmarks to effectively ensure and evaluate the honesty of LLMs. In this paper, we introduce BeHonest, a pioneering benchmark specifically designed to assess honesty in LLMs comprehensively. BeHonest evaluates three essential aspects of honesty: awareness of knowledge boundaries, avoidance of deceit, and consistency in responses. Building on this foundation, we designed 10 scenarios to evaluate and analyze 9 popular LLMs on the market, including both closed-source and open-source models from different model families with varied model sizes. Our findings indicate that there is still significant room for improvement in the honesty of LLMs. We also encourage the AI community to prioritize honesty alignment in LLMs. Our benchmark and code can be found at: \url{https://github.com/GAIR-NLP/BeHonest}.
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024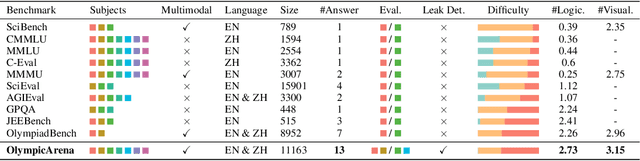
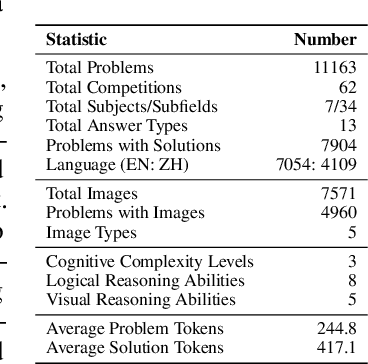
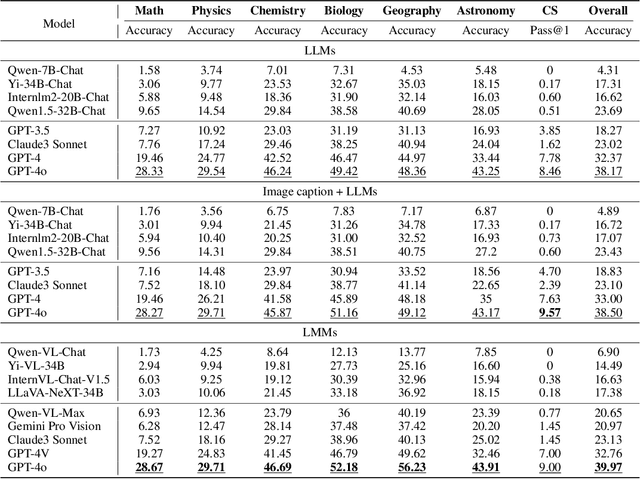
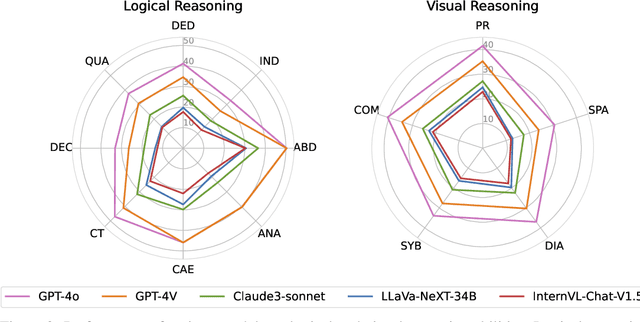
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.