 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeauty in the Eye of AI: Aligning LLMs and Vision Models with Human Aesthetics in Network Visualization
Apr 03, 2026Network visualization has traditionally relied on heuristic metrics, such as stress, under the assumption that optimizing them leads to aesthetic and informative layouts. However, no single metric consistently produces the most effective results. A data-driven alternative is to learn from human preferences, where annotators select their favored visualization among multiple layouts of the same graphs. These human-preference labels can then be used to train a generative model that approximates human aesthetic preferences. However, obtaining human labels at scale is costly and time-consuming. As a result, this generative approach has so far been tested only with machine-labeled data. In this paper, we explore the use of large language models (LLMs) and vision models (VMs) as proxies for human judgment. Through a carefully designed user study involving 27 participants, we curated a large set of human preference labels. We used this data both to better understand human preferences and to bootstrap LLM/VM labelers. We show that prompt engineering that combines few-shot examples and diverse input formats, such as image embeddings, significantly improves LLM-human alignment, and additional filtering by the confidence score of the LLM pushes the alignment to human-human levels. Furthermore, we demonstrate that carefully trained VMs can achieve VM-human alignment at a level comparable to that between human annotators. Our results suggest that AI can feasibly serve as a scalable proxy for human labelers.
Prediction of Major Solar Flares Using Interpretable Class-dependent Reward Framework with Active Region Magnetograms and Domain Knowledge
Feb 18, 2026In this work, we develop, for the first time, a supervised classification framework with class-dependent rewards (CDR) to predict $\geq$MM flares within 24 hr. We construct multiple datasets, covering knowledge-informed features and line-of sight (LOS) magnetograms. We also apply three deep learning models (CNN, CNN-BiLSTM, and Transformer) and three CDR counterparts (CDR-CNN, CDR-CNN-BiLSTM, and CDR-Transformer). First, we analyze the importance of LOS magnetic field parameters with the Transformer, then compare its performance using LOS-only, vector-only, and combined magnetic field parameters. Second, we compare flare prediction performance based on CDR models versus deep learning counterparts. Third, we perform sensitivity analysis on reward engineering for CDR models. Fourth, we use the SHAP method for model interpretability. Finally, we conduct performance comparison between our models and NASA/CCMC. The main findings are: (1)Among LOS feature combinations, R_VALUE and AREA_ACR consistently yield the best results. (2)Transformer achieves better performance with combined LOS and vector magnetic field data than with either alone. (3)Models using knowledge-informed features outperform those using magnetograms. (4)While CNN and CNN-BiLSTM outperform their CDR counterparts on magnetograms, CDR-Transformer is slightly superior to its deep learning counterpart when using knowledge-informed features. Among all models, CDR-Transformer achieves the best performance. (5)The predictive performance of the CDR models is not overly sensitive to the reward choices.(6)Through SHAP analysis, the CDR model tends to regard TOTUSJH as more important, while the Transformer tends to prioritize R_VALUE more.(7)Under identical prediction time and active region (AR) number, the CDR-Transformer shows superior predictive capabilities compared to NASA/CCMC.
daVinci-Agency: Unlocking Long-Horizon Agency Data-Efficiently
Feb 02, 2026While Large Language Models (LLMs) excel at short-term tasks, scaling them to long-horizon agentic workflows remains challenging. The core bottleneck lies in the scarcity of training data that captures authentic long-dependency structures and cross-stage evolutionary dynamics--existing synthesis methods either confine to single-feature scenarios constrained by model distribution, or incur prohibitive human annotation costs, failing to provide scalable, high-quality supervision. We address this by reconceptualizing data synthesis through the lens of real-world software evolution. Our key insight: Pull Request (PR) sequences naturally embody the supervision signals for long-horizon learning. They decompose complex objectives into verifiable submission units, maintain functional coherence across iterations, and encode authentic refinement patterns through bug-fix histories. Building on this, we propose daVinci-Agency, which systematically mines structured supervision from chain-of-PRs through three interlocking mechanisms: (1) progressive task decomposition via continuous commits, (2) long-term consistency enforcement through unified functional objectives, and (3) verifiable refinement from authentic bug-fix trajectories. Unlike synthetic trajectories that treat each step independently, daVinci-Agency's PR-grounded structure inherently preserves the causal dependencies and iterative refinements essential for teaching persistent goal-directed behavior and enables natural alignment with project-level, full-cycle task modeling. The resulting trajectories are substantial--averaging 85k tokens and 116 tool calls--yet remarkably data-efficient: fine-tuning GLM-4.6 on 239 daVinci-Agency samples yields broad improvements across benchmarks, notably achieving a 47% relative gain on Toolathlon. Beyond benchmark performance, our analysis confirms...
daVinci-Dev: Agent-native Mid-training for Software Engineering
Jan 27, 2026Recently, the frontier of Large Language Model (LLM) capabilities has shifted from single-turn code generation to agentic software engineering-a paradigm where models autonomously navigate, edit, and test complex repositories. While post-training methods have become the de facto approach for code agents, **agentic mid-training**-mid-training (MT) on large-scale data that mirrors authentic agentic workflows-remains critically underexplored due to substantial resource requirements, despite offering a more scalable path to instilling foundational agentic behaviors than relying solely on expensive reinforcement learning. A central challenge in realizing effective agentic mid-training is the distribution mismatch between static training data and the dynamic, feedback-rich environment of real development. To address this, we present a systematic study of agentic mid-training, establishing both the data synthesis principles and training methodology for effective agent development at scale. Central to our approach is **agent-native data**-supervision comprising two complementary types of trajectories: **contextually-native trajectories** that preserve the complete information flow an agent experiences, offering broad coverage and diversity; and **environmentally-native trajectories** collected from executable repositories where observations stem from actual tool invocations and test executions, providing depth and interaction authenticity. We verify the model's agentic capabilities on `SWE-Bench Verified`. We demonstrate our superiority over the previous open software engineering mid-training recipe `Kimi-Dev` under two post-training settings with an aligned base model and agentic scaffold, while using less than half mid-training tokens (73.1B). Besides relative advantage, our best performing 32B and 72B models achieve **56.1%** and **58.5%** resolution rates, respectively, which are ...
One Sample to Rule Them All: Extreme Data Efficiency in RL Scaling
Jan 06, 2026The reasoning ability of large language models (LLMs) can be unleashed with reinforcement learning (RL) (OpenAI, 2024; DeepSeek-AI et al., 2025a; Zeng et al., 2025). The success of existing RL attempts in LLMs usually relies on high-quality samples of thousands or beyond. In this paper, we challenge fundamental assumptions about data requirements in RL for LLMs by demonstrating the remarkable effectiveness of one-shot learning. Specifically, we introduce polymath learning, a framework for designing one training sample that elicits multidisciplinary impact. We present three key findings: (1) A single, strategically selected math reasoning sample can produce significant performance improvements across multiple domains, including physics, chemistry, and biology with RL; (2) The math skills salient to reasoning suggest the characteristics of the optimal polymath sample; and (3) An engineered synthetic sample that integrates multidiscipline elements outperforms training with individual samples that naturally occur. Our approach achieves superior performance to training with larger datasets across various reasoning benchmarks, demonstrating that sample quality and design, rather than quantity, may be the key to unlock enhanced reasoning capabilities in language models. Our results suggest a shift, dubbed as sample engineering, toward precision engineering of training samples rather than simply increasing data volume.
ThinkDial: An Open Recipe for Controlling Reasoning Effort in Large Language Models
Aug 26, 2025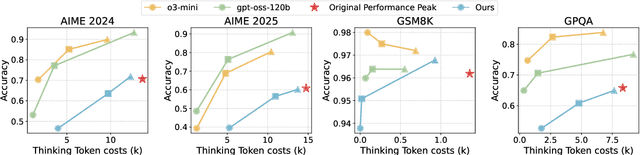
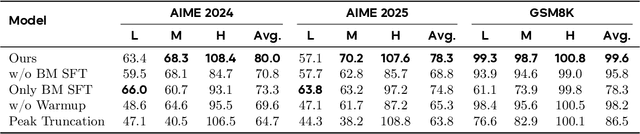
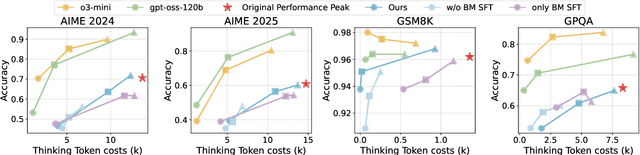

Large language models (LLMs) with chain-of-thought reasoning have demonstrated remarkable problem-solving capabilities, but controlling their computational effort remains a significant challenge for practical deployment. Recent proprietary systems like OpenAI's gpt-oss series have introduced discrete operational modes for intuitive reasoning control, but the open-source community has largely failed to achieve such capabilities. In this paper, we introduce ThinkDial, the first open-recipe end-to-end framework that successfully implements gpt-oss-style controllable reasoning through discrete operational modes. Our system enables seamless switching between three distinct reasoning regimes: High mode (full reasoning capability), Medium mode (50 percent token reduction with <10 percent performance degradation), and Low mode (75 percent token reduction with <15 percent performance degradation). We achieve this through an end-to-end training paradigm that integrates budget-mode control throughout the entire pipeline: budget-mode supervised fine-tuning that embeds controllable reasoning capabilities directly into the learning process, and two-phase budget-aware reinforcement learning with adaptive reward shaping. Extensive experiments demonstrate that ThinkDial achieves target compression-performance trade-offs with clear response length reductions while maintaining performance thresholds. The framework also exhibits strong generalization capabilities on out-of-distribution tasks.
Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles
May 26, 2025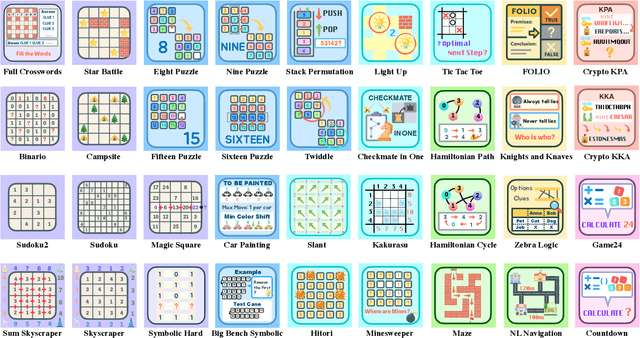

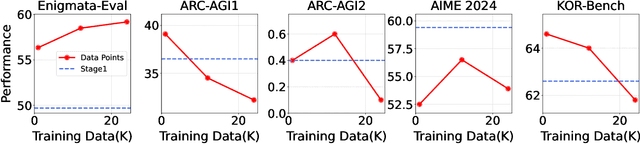
Large Language Models (LLMs), such as OpenAI's o1 and DeepSeek's R1, excel at advanced reasoning tasks like math and coding via Reinforcement Learning with Verifiable Rewards (RLVR), but still struggle with puzzles solvable by humans without domain knowledge. We introduce Enigmata, the first comprehensive suite tailored for improving LLMs with puzzle reasoning skills. It includes 36 tasks across seven categories, each with 1) a generator that produces unlimited examples with controllable difficulty and 2) a rule-based verifier for automatic evaluation. This generator-verifier design supports scalable, multi-task RL training, fine-grained analysis, and seamless RLVR integration. We further propose Enigmata-Eval, a rigorous benchmark, and develop optimized multi-task RLVR strategies. Our trained model, Qwen2.5-32B-Enigmata, consistently surpasses o3-mini-high and o1 on the puzzle reasoning benchmarks like Enigmata-Eval, ARC-AGI (32.8%), and ARC-AGI 2 (0.6%). It also generalizes well to out-of-domain puzzle benchmarks and mathematical reasoning, with little multi-tasking trade-off. When trained on larger models like Seed1.5-Thinking (20B activated parameters and 200B total parameters), puzzle data from Enigmata further boosts SoTA performance on advanced math and STEM reasoning tasks such as AIME (2024-2025), BeyondAIME and GPQA (Diamond), showing nice generalization benefits of Enigmata. This work offers a unified, controllable framework for advancing logical reasoning in LLMs. Resources of this work can be found at https://seed-enigmata.github.io.
Generative AI Act II: Test Time Scaling Drives Cognition Engineering
Apr 21, 2025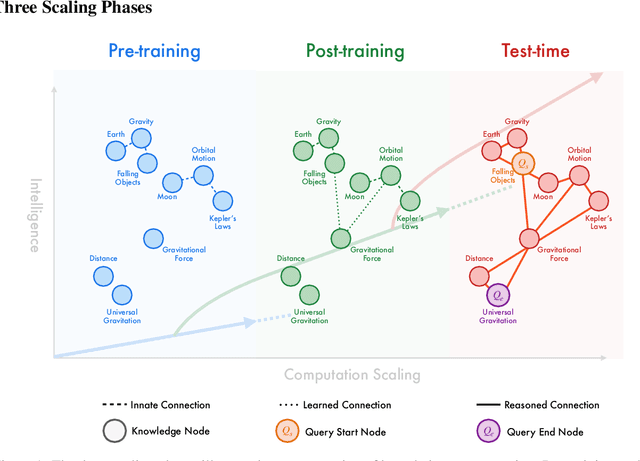
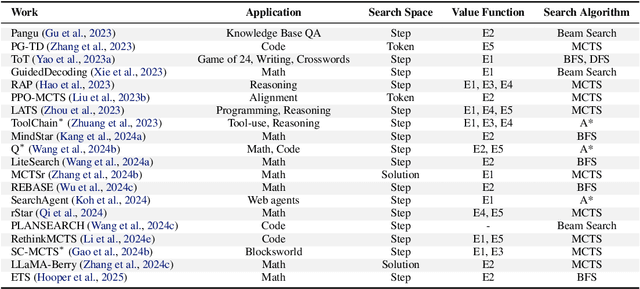
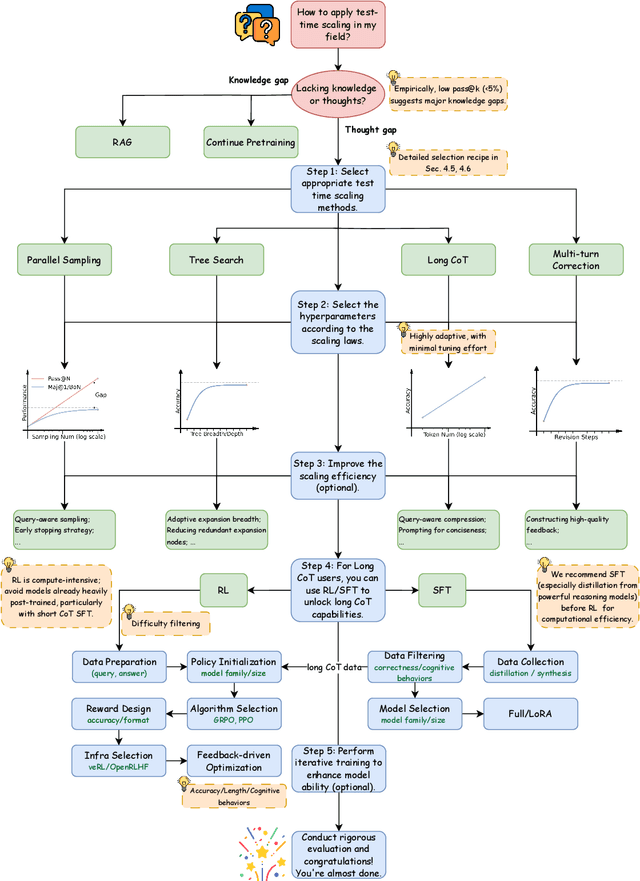
The first generation of Large Language Models - what might be called "Act I" of generative AI (2020-2023) - achieved remarkable success through massive parameter and data scaling, yet exhibited fundamental limitations such as knowledge latency, shallow reasoning, and constrained cognitive processes. During this era, prompt engineering emerged as our primary interface with AI, enabling dialogue-level communication through natural language. We now witness the emergence of "Act II" (2024-present), where models are transitioning from knowledge-retrieval systems (in latent space) to thought-construction engines through test-time scaling techniques. This new paradigm establishes a mind-level connection with AI through language-based thoughts. In this paper, we clarify the conceptual foundations of cognition engineering and explain why this moment is critical for its development. We systematically break down these advanced approaches through comprehensive tutorials and optimized implementations, democratizing access to cognition engineering and enabling every practitioner to participate in AI's second act. We provide a regularly updated collection of papers on test-time scaling in the GitHub Repository: https://github.com/GAIR-NLP/cognition-engineering
ToRL: Scaling Tool-Integrated RL
Mar 30, 2025We introduce ToRL (Tool-Integrated Reinforcement Learning), a framework for training large language models (LLMs) to autonomously use computational tools via reinforcement learning. Unlike supervised fine-tuning, ToRL allows models to explore and discover optimal strategies for tool use. Experiments with Qwen2.5-Math models show significant improvements: ToRL-7B reaches 43.3\% accuracy on AIME~24, surpassing reinforcement learning without tool integration by 14\% and the best existing Tool-Integrated Reasoning (TIR) model by 17\%. Further analysis reveals emergent behaviors such as strategic tool invocation, self-regulation of ineffective code, and dynamic adaptation between computational and analytical reasoning, all arising purely through reward-driven learning.
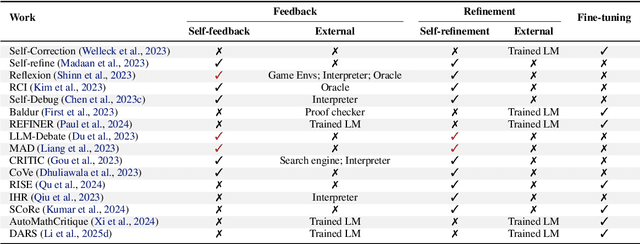
Multi-modal expressive personality recognition in data non-ideal audiovisual based on multi-scale feature enhancement and modal augment
Mar 08, 2025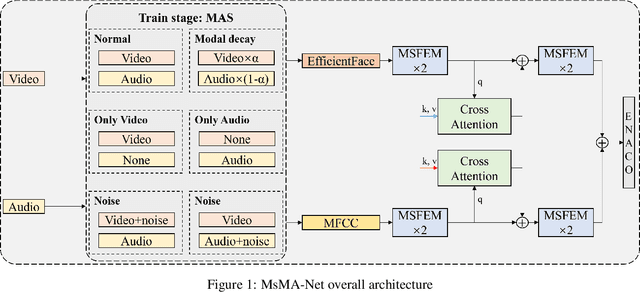

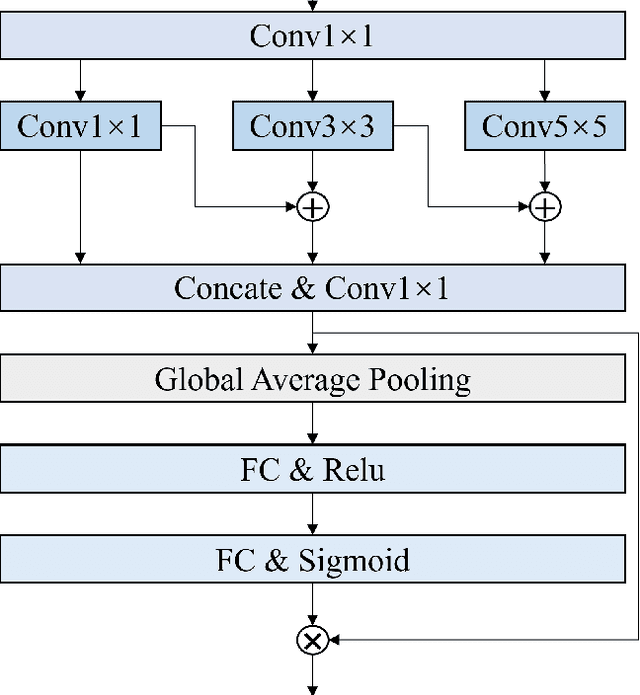

Automatic personality recognition is a research hotspot in the intersection of computer science and psychology, and in human-computer interaction, personalised has a wide range of applications services and other scenarios. In this paper, an end-to-end multimodal performance personality is established for both visual and auditory modal datarecognition network , and the through feature-level fusion , which effectively of the two modalities is carried out the cross-attention mechanismfuses the features of the two modal data; and a is proposed multiscale feature enhancement modalitiesmodule , which enhances for visual and auditory boththe expression of the information of effective the features and suppresses the interference of the redundant information. In addition, during the training process, this paper proposes a modal enhancement training strategy to simulate non-ideal such as modal loss and noise interferencedata situations , which enhances the adaptability ofand the model to non-ideal data scenarios improves the robustness of the model. Experimental results show that the method proposed in this paper is able to achieve an average Big Five personality accuracy of , which outperforms existing 0.916 on the personality analysis dataset ChaLearn First Impressionother methods based on audiovisual and audio-visual both modalities. The ablation experiments also validate our proposed , respectivelythe contribution of module and modality enhancement strategy to the model performance. Finally, we simulate in the inference phase multi-scale feature enhancement six non-ideal data scenarios to verify the modal enhancement strategy's improvement in model robustness.