 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Random Masking: A Dual-Stream Approach for Rotation-Invariant Point Cloud Masked Autoencoders
Sep 18, 2025Existing rotation-invariant point cloud masked autoencoders (MAE) rely on random masking strategies that overlook geometric structure and semantic coherence. Random masking treats patches independently, failing to capture spatial relationships consistent across orientations and overlooking semantic object parts that maintain identity regardless of rotation. We propose a dual-stream masking approach combining 3D Spatial Grid Masking and Progressive Semantic Masking to address these fundamental limitations. Grid masking creates structured patterns through coordinate sorting to capture geometric relationships that persist across different orientations, while semantic masking uses attention-driven clustering to discover semantically meaningful parts and maintain their coherence during masking. These complementary streams are orchestrated via curriculum learning with dynamic weighting, progressing from geometric understanding to semantic discovery. Designed as plug-and-play components, our strategies integrate into existing rotation-invariant frameworks without architectural changes, ensuring broad compatibility across different approaches. Comprehensive experiments on ModelNet40, ScanObjectNN, and OmniObject3D demonstrate consistent improvements across various rotation scenarios, showing substantial performance gains over the baseline rotation-invariant methods.
GRASPTrack: Geometry-Reasoned Association via Segmentation and Projection for Multi-Object Tracking
Aug 11, 2025Multi-object tracking (MOT) in monocular videos is fundamentally challenged by occlusions and depth ambiguity, issues that conventional tracking-by-detection (TBD) methods struggle to resolve owing to a lack of geometric awareness. To address these limitations, we introduce GRASPTrack, a novel depth-aware MOT framework that integrates monocular depth estimation and instance segmentation into a standard TBD pipeline to generate high-fidelity 3D point clouds from 2D detections, thereby enabling explicit 3D geometric reasoning. These 3D point clouds are then voxelized to enable a precise and robust Voxel-Based 3D Intersection-over-Union (IoU) for spatial association. To further enhance tracking robustness, our approach incorporates Depth-aware Adaptive Noise Compensation, which dynamically adjusts the Kalman filter process noise based on occlusion severity for more reliable state estimation. Additionally, we propose a Depth-enhanced Observation-Centric Momentum, which extends the motion direction consistency from the image plane into 3D space to improve motion-based association cues, particularly for objects with complex trajectories. Extensive experiments on the MOT17, MOT20, and DanceTrack benchmarks demonstrate that our method achieves competitive performance, significantly improving tracking robustness in complex scenes with frequent occlusions and intricate motion patterns.
HFBRI-MAE: Handcrafted Feature Based Rotation-Invariant Masked Autoencoder for 3D Point Cloud Analysis
Apr 19, 2025Self-supervised learning (SSL) has demonstrated remarkable success in 3D point cloud analysis, particularly through masked autoencoders (MAEs). However, existing MAE-based methods lack rotation invariance, leading to significant performance degradation when processing arbitrarily rotated point clouds in real-world scenarios. To address this limitation, we introduce Handcrafted Feature-Based Rotation-Invariant Masked Autoencoder (HFBRI-MAE), a novel framework that refines the MAE design with rotation-invariant handcrafted features to ensure stable feature learning across different orientations. By leveraging both rotation-invariant local and global features for token embedding and position embedding, HFBRI-MAE effectively eliminates rotational dependencies while preserving rich geometric structures. Additionally, we redefine the reconstruction target to a canonically aligned version of the input, mitigating rotational ambiguities. Extensive experiments on ModelNet40, ScanObjectNN, and ShapeNetPart demonstrate that HFBRI-MAE consistently outperforms existing methods in object classification, segmentation, and few-shot learning, highlighting its robustness and strong generalization ability in real-world 3D applications.
Multi-Programming Language Ensemble for Code Generation in Large Language Model
Sep 06, 2024Large language models (LLMs) have significantly improved code generation, particularly in one-pass code generation. However, most existing approaches focus solely on generating code in a single programming language, overlooking the potential of leveraging the multi-language capabilities of LLMs. LLMs have varying patterns of errors across different languages, suggesting that a more robust approach could be developed by leveraging these multi-language outputs. In this study, we propose Multi-Programming Language Ensemble (MPLE), a novel ensemble-based method that utilizes code generation across multiple programming languages to enhance overall performance. By treating each language-specific code generation process as an individual "weak expert" and effectively integrating their outputs, our method mitigates language-specific errors and biases. This multi-language ensemble strategy leverages the complementary strengths of different programming languages, enabling the model to produce more accurate and robust code. Our approach can be seamlessly integrated with commonly used techniques such as the reflection algorithm and Monte Carlo tree search to improve code generation quality further. Experimental results show that our framework consistently enhances baseline performance by up to 17.92% on existing benchmarks (HumanEval and HumanEval-plus), with a standout result of 96.25% accuracy on the HumanEval benchmark, achieving new state-of-the-art results across various LLM models. The code will be released at https://github.com/NinjaTech-AI/MPLE
Enhancing Robustness to Noise Corruption for Point Cloud Model via Spatial Sorting and Set-Mixing Aggregation Module
Jul 15, 2024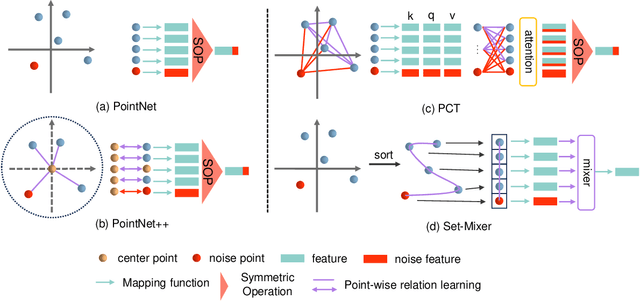
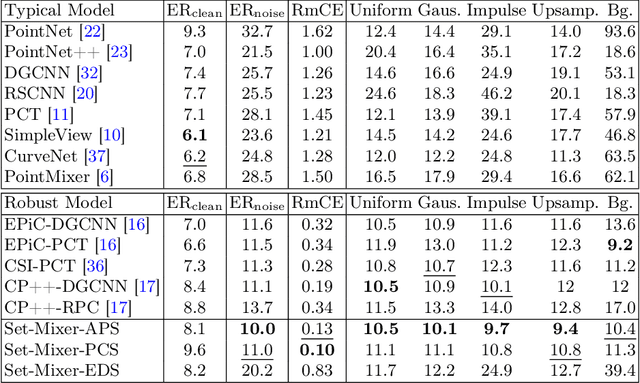
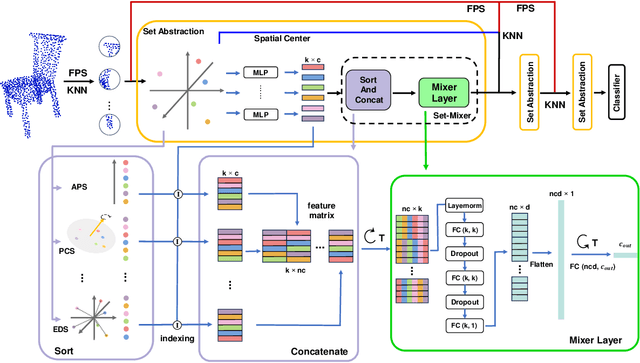
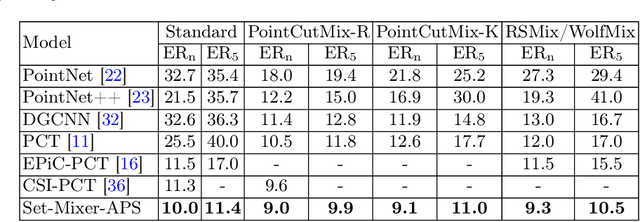
Current models for point cloud recognition demonstrate promising performance on synthetic datasets. However, real-world point cloud data inevitably contains noise, impacting model robustness. While recent efforts focus on enhancing robustness through various strategies, there still remains a gap in comprehensive analyzes from the standpoint of network architecture design. Unlike traditional methods that rely on generic techniques, our approach optimizes model robustness to noise corruption through network architecture design. Inspired by the token-mixing technique applied in 2D images, we propose Set-Mixer, a noise-robust aggregation module which facilitates communication among all points to extract geometric shape information and mitigating the influence of individual noise points. A sorting strategy is designed to enable our module to be invariant to point permutation, which also tackles the unordered structure of point cloud and introduces consistent relative spatial information. Experiments conducted on ModelNet40-C indicate that Set-Mixer significantly enhances the model performance on noisy point clouds, underscoring its potential to advance real-world applicability in 3D recognition and perception tasks.
PaintHuman: Towards High-fidelity Text-to-3D Human Texturing via Denoised Score Distillation
Oct 14, 2023



Recent advances in zero-shot text-to-3D human generation, which employ the human model prior (eg, SMPL) or Score Distillation Sampling (SDS) with pre-trained text-to-image diffusion models, have been groundbreaking. However, SDS may provide inaccurate gradient directions under the weak diffusion guidance, as it tends to produce over-smoothed results and generate body textures that are inconsistent with the detailed mesh geometry. Therefore, directly leverage existing strategies for high-fidelity text-to-3D human texturing is challenging. In this work, we propose a model called PaintHuman to addresses the challenges from two aspects. We first propose a novel score function, Denoised Score Distillation (DSD), which directly modifies the SDS by introducing negative gradient components to iteratively correct the gradient direction and generate high-quality textures. In addition, we use the depth map as a geometric guidance to ensure the texture is semantically aligned to human mesh surfaces. To guarantee the quality of rendered results, we employ geometry-aware networks to predict surface materials and render realistic human textures. Extensive experiments, benchmarked against state-of-the-art methods, validate the efficacy of our approach.
Hi-ResNet: A High-Resolution Remote Sensing Network for Semantic Segmentation
May 23, 2023
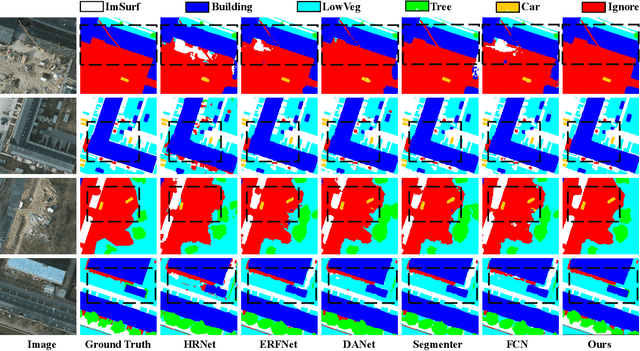
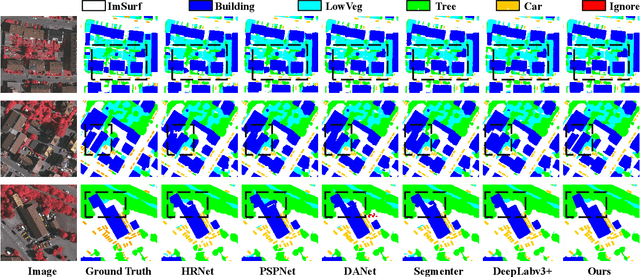
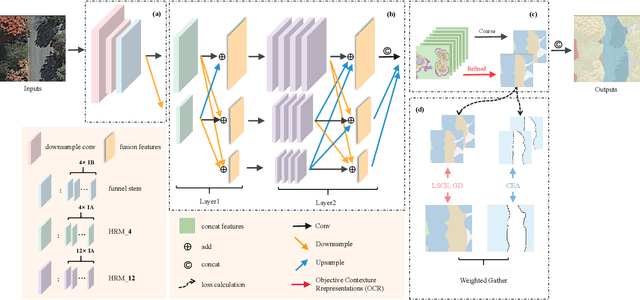
High-resolution remote sensing (HRS) semantic segmentation extracts key objects from high-resolution coverage areas. However, objects of the same category within HRS images generally show significant differences in scale and shape across diverse geographical environments, making it difficult to fit the data distribution. Additionally, a complex background environment causes similar appearances of objects of different categories, which precipitates a substantial number of objects into misclassification as background. These issues make existing learning algorithms sub-optimal. In this work, we solve the above-mentioned problems by proposing a High-resolution remote sensing network (Hi-ResNet) with efficient network structure designs, which consists of a funnel module, a multi-branch module with stacks of information aggregation (IA) blocks, and a feature refinement module, sequentially, and Class-agnostic Edge Aware (CEA) loss. Specifically, we propose a funnel module to downsample, which reduces the computational cost, and extract high-resolution semantic information from the initial input image. Secondly, we downsample the processed feature images into multi-resolution branches incrementally to capture image features at different scales and apply IA blocks, which capture key latent information by leveraging attention mechanisms, for effective feature aggregation, distinguishing image features of the same class with variant scales and shapes. Finally, our feature refinement module integrate the CEA loss function, which disambiguates inter-class objects with similar shapes and increases the data distribution distance for correct predictions. With effective pre-training strategies, we demonstrated the superiority of Hi-ResNet over state-of-the-art methods on three HRS segmentation benchmarks.
CelebV-Text: A Large-Scale Facial Text-Video Dataset
Mar 26, 2023Text-driven generation models are flourishing in video generation and editing. However, face-centric text-to-video generation remains a challenge due to the lack of a suitable dataset containing high-quality videos and highly relevant texts. This paper presents CelebV-Text, a large-scale, diverse, and high-quality dataset of facial text-video pairs, to facilitate research on facial text-to-video generation tasks. CelebV-Text comprises 70,000 in-the-wild face video clips with diverse visual content, each paired with 20 texts generated using the proposed semi-automatic text generation strategy. The provided texts are of high quality, describing both static and dynamic attributes precisely. The superiority of CelebV-Text over other datasets is demonstrated via comprehensive statistical analysis of the videos, texts, and text-video relevance. The effectiveness and potential of CelebV-Text are further shown through extensive self-evaluation. A benchmark is constructed with representative methods to standardize the evaluation of the facial text-to-video generation task. All data and models are publicly available.
PaRot: Patch-Wise Rotation-Invariant Network via Feature Disentanglement and Pose Restoration
Feb 06, 2023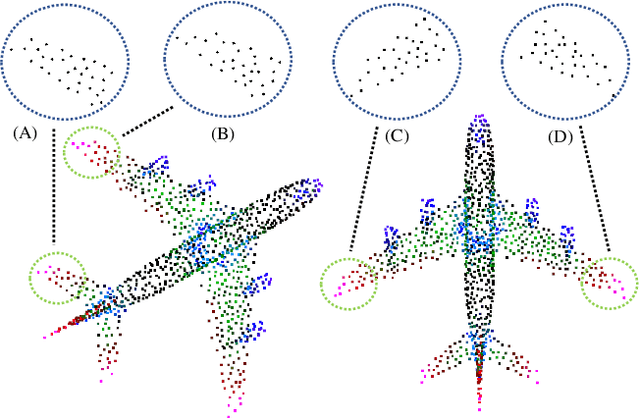
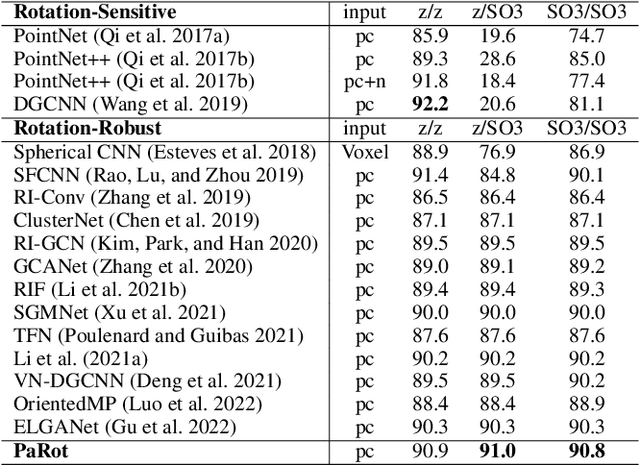
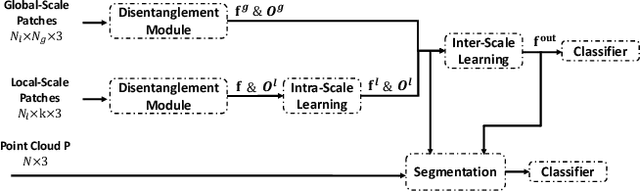
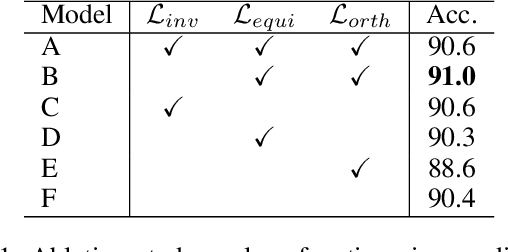
Recent interest in point cloud analysis has led rapid progress in designing deep learning methods for 3D models. However, state-of-the-art models are not robust to rotations, which remains an unknown prior to real applications and harms the model performance. In this work, we introduce a novel Patch-wise Rotation-invariant network (PaRot), which achieves rotation invariance via feature disentanglement and produces consistent predictions for samples with arbitrary rotations. Specifically, we design a siamese training module which disentangles rotation invariance and equivariance from patches defined over different scales, e.g., the local geometry and global shape, via a pair of rotations. However, our disentangled invariant feature loses the intrinsic pose information of each patch. To solve this problem, we propose a rotation-invariant geometric relation to restore the relative pose with equivariant information for patches defined over different scales. Utilising the pose information, we propose a hierarchical module which implements intra-scale and inter-scale feature aggregation for 3D shape learning. Moreover, we introduce a pose-aware feature propagation process with the rotation-invariant relative pose information embedded. Experiments show that our disentanglement module extracts high-quality rotation-robust features and the proposed lightweight model achieves competitive results in rotated 3D object classification and part segmentation tasks. Our project page is released at: https://patchrot.github.io/.
Rethinking Rotation Invariance with Point Cloud Registration
Dec 31, 2022Recent investigations on rotation invariance for 3D point clouds have been devoted to devising rotation-invariant feature descriptors or learning canonical spaces where objects are semantically aligned. Examinations of learning frameworks for invariance have seldom been looked into. In this work, we review rotation invariance in terms of point cloud registration and propose an effective framework for rotation invariance learning via three sequential stages, namely rotation-invariant shape encoding, aligned feature integration, and deep feature registration. We first encode shape descriptors constructed with respect to reference frames defined over different scales, e.g., local patches and global topology, to generate rotation-invariant latent shape codes. Within the integration stage, we propose Aligned Integration Transformer to produce a discriminative feature representation by integrating point-wise self- and cross-relations established within the shape codes. Meanwhile, we adopt rigid transformations between reference frames to align the shape codes for feature consistency across different scales. Finally, the deep integrated feature is registered to both rotation-invariant shape codes to maximize feature similarities, such that rotation invariance of the integrated feature is preserved and shared semantic information is implicitly extracted from shape codes. Experimental results on 3D shape classification, part segmentation, and retrieval tasks prove the feasibility of our work. Our project page is released at: https://rotation3d.github.io/.