 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeTumor: Large-Scale Generative Tumor Synthesis in Computed Tomography Images for Improving Tumor Recognition
Feb 23, 2025Tumor is a leading cause of death worldwide, with an estimated 10 million deaths attributed to tumor-related diseases every year. AI-driven tumor recognition unlocks new possibilities for more precise and intelligent tumor screening and diagnosis. However, the progress is heavily hampered by the scarcity of annotated datasets, which demands extensive annotation efforts by radiologists. To tackle this challenge, we introduce FreeTumor, an innovative Generative AI (GAI) framework to enable large-scale tumor synthesis for mitigating data scarcity. Specifically, FreeTumor effectively leverages a combination of limited labeled data and large-scale unlabeled data for tumor synthesis training. Unleashing the power of large-scale data, FreeTumor is capable of synthesizing a large number of realistic tumors on images for augmenting training datasets. To this end, we create the largest training dataset for tumor synthesis and recognition by curating 161,310 publicly available Computed Tomography (CT) volumes from 33 sources, with only 2.3% containing annotated tumors. To validate the fidelity of synthetic tumors, we engaged 13 board-certified radiologists in a Visual Turing Test to discern between synthetic and real tumors. Rigorous clinician evaluation validates the high quality of our synthetic tumors, as they achieved only 51.1% sensitivity and 60.8% accuracy in distinguishing our synthetic tumors from real ones. Through high-quality tumor synthesis, FreeTumor scales up the recognition training datasets by over 40 times, showcasing a notable superiority over state-of-the-art AI methods including various synthesis methods and foundation models. These findings indicate promising prospects of FreeTumor in clinical applications, potentially advancing tumor treatments and improving the survival rates of patients.
Hi-ResNet: A High-Resolution Remote Sensing Network for Semantic Segmentation
May 23, 2023
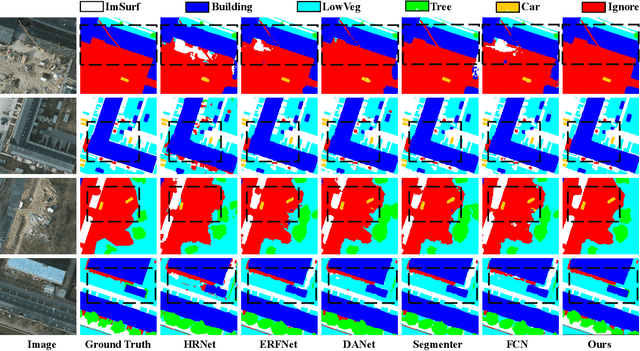
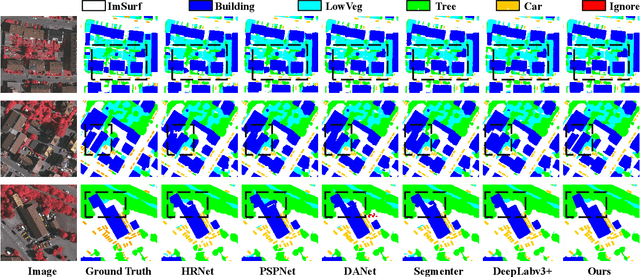
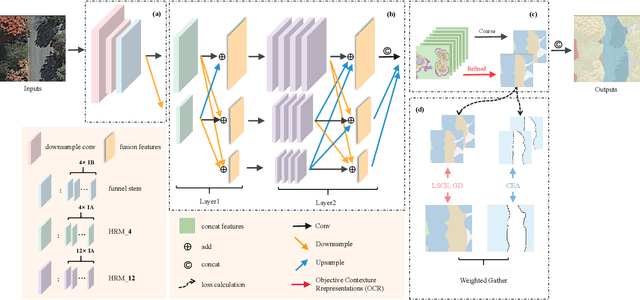
High-resolution remote sensing (HRS) semantic segmentation extracts key objects from high-resolution coverage areas. However, objects of the same category within HRS images generally show significant differences in scale and shape across diverse geographical environments, making it difficult to fit the data distribution. Additionally, a complex background environment causes similar appearances of objects of different categories, which precipitates a substantial number of objects into misclassification as background. These issues make existing learning algorithms sub-optimal. In this work, we solve the above-mentioned problems by proposing a High-resolution remote sensing network (Hi-ResNet) with efficient network structure designs, which consists of a funnel module, a multi-branch module with stacks of information aggregation (IA) blocks, and a feature refinement module, sequentially, and Class-agnostic Edge Aware (CEA) loss. Specifically, we propose a funnel module to downsample, which reduces the computational cost, and extract high-resolution semantic information from the initial input image. Secondly, we downsample the processed feature images into multi-resolution branches incrementally to capture image features at different scales and apply IA blocks, which capture key latent information by leveraging attention mechanisms, for effective feature aggregation, distinguishing image features of the same class with variant scales and shapes. Finally, our feature refinement module integrate the CEA loss function, which disambiguates inter-class objects with similar shapes and increases the data distribution distance for correct predictions. With effective pre-training strategies, we demonstrated the superiority of Hi-ResNet over state-of-the-art methods on three HRS segmentation benchmarks.