 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlance and Focus Reinforcement for Pan-cancer Screening
Jan 27, 2026Pan-cancer screening in large-scale CT scans remains challenging for existing AI methods, primarily due to the difficulty of localizing diverse types of tiny lesions in large CT volumes. The extreme foreground-background imbalance significantly hinders models from focusing on diseased regions, while redundant focus on healthy regions not only decreases the efficiency but also increases false positives. Inspired by radiologists' glance and focus diagnostic strategy, we introduce GF-Screen, a Glance and Focus reinforcement learning framework for pan-cancer screening. GF-Screen employs a Glance model to localize the diseased regions and a Focus model to precisely segment the lesions, where segmentation results of the Focus model are leveraged to reward the Glance model via Reinforcement Learning (RL). Specifically, the Glance model crops a group of sub-volumes from the entire CT volume and learns to select the sub-volumes with lesions for the Focus model to segment. Given that the selecting operation is non-differentiable for segmentation training, we propose to employ the segmentation results to reward the Glance model. To optimize the Glance model, we introduce a novel group relative learning paradigm, which employs group relative comparison to prioritize high-advantage predictions and discard low-advantage predictions within sub-volume groups, not only improving efficiency but also reducing false positives. In this way, for the first time, we effectively extend cutting-edge RL techniques to tackle the specific challenges in pan-cancer screening. Extensive experiments on 16 internal and 7 external datasets across 9 lesion types demonstrated the effectiveness of GF-Screen. Notably, GF-Screen leads the public validation leaderboard of MICCAI FLARE25 pan-cancer challenge, surpassing the FLARE24 champion solution by a large margin (+25.6% DSC and +28.2% NSD).
Generative AI for Misalignment-Resistant Virtual Staining to Accelerate Histopathology Workflows
Sep 17, 2025Accurate histopathological diagnosis often requires multiple differently stained tissue sections, a process that is time-consuming, labor-intensive, and environmentally taxing due to the use of multiple chemical stains. Recently, virtual staining has emerged as a promising alternative that is faster, tissue-conserving, and environmentally friendly. However, existing virtual staining methods face significant challenges in clinical applications, primarily due to their reliance on well-aligned paired data. Obtaining such data is inherently difficult because chemical staining processes can distort tissue structures, and a single tissue section cannot undergo multiple staining procedures without damage or loss of information. As a result, most available virtual staining datasets are either unpaired or roughly paired, making it difficult for existing methods to achieve accurate pixel-level supervision. To address this challenge, we propose a robust virtual staining framework featuring cascaded registration mechanisms to resolve spatial mismatches between generated outputs and their corresponding ground truth. Experimental results demonstrate that our method significantly outperforms state-of-the-art models across five datasets, achieving an average improvement of 3.2% on internal datasets and 10.1% on external datasets. Moreover, in datasets with substantial misalignment, our approach achieves a remarkable 23.8% improvement in peak signal-to-noise ratio compared to baseline models. The exceptional robustness of the proposed method across diverse datasets simplifies the data acquisition process for virtual staining and offers new insights for advancing its development.
UniBiomed: A Universal Foundation Model for Grounded Biomedical Image Interpretation
Apr 30, 2025Multi-modal interpretation of biomedical images opens up novel opportunities in biomedical image analysis. Conventional AI approaches typically rely on disjointed training, i.e., Large Language Models (LLMs) for clinical text generation and segmentation models for target extraction, which results in inflexible real-world deployment and a failure to leverage holistic biomedical information. To this end, we introduce UniBiomed, the first universal foundation model for grounded biomedical image interpretation. UniBiomed is based on a novel integration of Multi-modal Large Language Model (MLLM) and Segment Anything Model (SAM), which effectively unifies the generation of clinical texts and the segmentation of corresponding biomedical objects for grounded interpretation. In this way, UniBiomed is capable of tackling a wide range of biomedical tasks across ten diverse biomedical imaging modalities. To develop UniBiomed, we curate a large-scale dataset comprising over 27 million triplets of images, annotations, and text descriptions across ten imaging modalities. Extensive validation on 84 internal and external datasets demonstrated that UniBiomed achieves state-of-the-art performance in segmentation, disease recognition, region-aware diagnosis, visual question answering, and report generation. Moreover, unlike previous models that rely on clinical experts to pre-diagnose images and manually craft precise textual or visual prompts, UniBiomed can provide automated and end-to-end grounded interpretation for biomedical image analysis. This represents a novel paradigm shift in clinical workflows, which will significantly improve diagnostic efficiency. In summary, UniBiomed represents a novel breakthrough in biomedical AI, unlocking powerful grounded interpretation capabilities for more accurate and efficient biomedical image analysis.
FreeTumor: Large-Scale Generative Tumor Synthesis in Computed Tomography Images for Improving Tumor Recognition
Feb 23, 2025Tumor is a leading cause of death worldwide, with an estimated 10 million deaths attributed to tumor-related diseases every year. AI-driven tumor recognition unlocks new possibilities for more precise and intelligent tumor screening and diagnosis. However, the progress is heavily hampered by the scarcity of annotated datasets, which demands extensive annotation efforts by radiologists. To tackle this challenge, we introduce FreeTumor, an innovative Generative AI (GAI) framework to enable large-scale tumor synthesis for mitigating data scarcity. Specifically, FreeTumor effectively leverages a combination of limited labeled data and large-scale unlabeled data for tumor synthesis training. Unleashing the power of large-scale data, FreeTumor is capable of synthesizing a large number of realistic tumors on images for augmenting training datasets. To this end, we create the largest training dataset for tumor synthesis and recognition by curating 161,310 publicly available Computed Tomography (CT) volumes from 33 sources, with only 2.3% containing annotated tumors. To validate the fidelity of synthetic tumors, we engaged 13 board-certified radiologists in a Visual Turing Test to discern between synthetic and real tumors. Rigorous clinician evaluation validates the high quality of our synthetic tumors, as they achieved only 51.1% sensitivity and 60.8% accuracy in distinguishing our synthetic tumors from real ones. Through high-quality tumor synthesis, FreeTumor scales up the recognition training datasets by over 40 times, showcasing a notable superiority over state-of-the-art AI methods including various synthesis methods and foundation models. These findings indicate promising prospects of FreeTumor in clinical applications, potentially advancing tumor treatments and improving the survival rates of patients.
MG-3D: Multi-Grained Knowledge-Enhanced 3D Medical Vision-Language Pre-training
Dec 08, 2024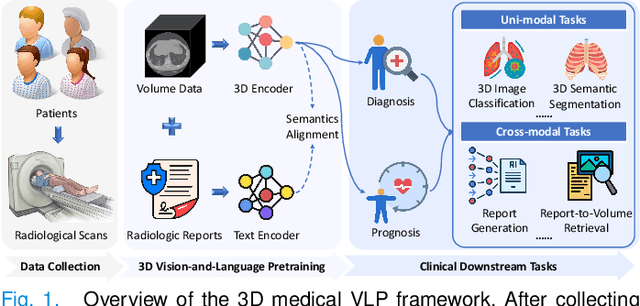

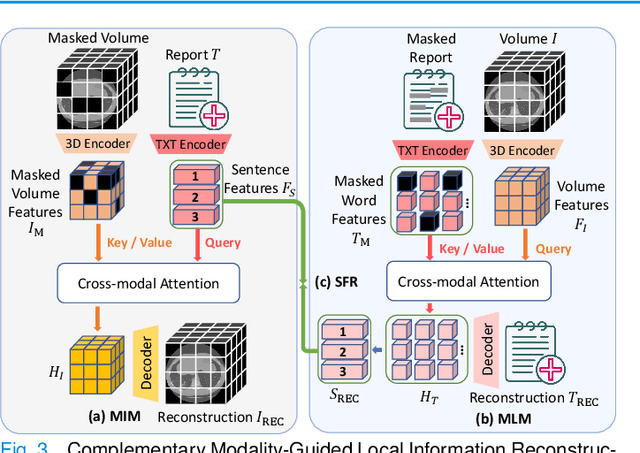

3D medical image analysis is pivotal in numerous clinical applications. However, the scarcity of labeled data and limited generalization capabilities hinder the advancement of AI-empowered models. Radiology reports are easily accessible and can serve as weakly-supervised signals. However, large-scale vision-language pre-training (VLP) remains underexplored in 3D medical image analysis. Specifically, the insufficient investigation into multi-grained radiology semantics and their correlations across patients leads to underutilization of large-scale volume-report data. Considering intra-patient cross-modal semantic consistency and inter-patient semantic correlations, we propose a multi-task VLP method, MG-3D, pre-trained on large-scale data (47.1K), addressing the challenges by the following two aspects: 1) Establishing the correspondence between volume semantics and multi-grained medical knowledge of each patient with cross-modal global alignment and complementary modality-guided local reconstruction, ensuring intra-patient features of different modalities cohesively represent the same semantic content; 2) Correlating inter-patient visual semantics based on fine-grained report correlations across patients, and keeping sensitivity to global individual differences via contrastive learning, enhancing the discriminative feature representation. Furthermore, we delve into the scaling law to explore potential performance improvements. Comprehensive evaluations across nine uni- and cross-modal clinical tasks are carried out to assess model efficacy. Extensive experiments on both internal and external datasets demonstrate the superior transferability, scalability, and generalization of MG-3D, showcasing its potential in advancing feature representation for 3D medical image analysis. Code will be available: https://github.com/Xuefeng-Ni/MG-3D.
Touchstone Benchmark: Are We on the Right Way for Evaluating AI Algorithms for Medical Segmentation?
Nov 06, 2024



How can we test AI performance? This question seems trivial, but it isn't. Standard benchmarks often have problems such as in-distribution and small-size test sets, oversimplified metrics, unfair comparisons, and short-term outcome pressure. As a consequence, good performance on standard benchmarks does not guarantee success in real-world scenarios. To address these problems, we present Touchstone, a large-scale collaborative segmentation benchmark of 9 types of abdominal organs. This benchmark is based on 5,195 training CT scans from 76 hospitals around the world and 5,903 testing CT scans from 11 additional hospitals. This diverse test set enhances the statistical significance of benchmark results and rigorously evaluates AI algorithms across various out-of-distribution scenarios. We invited 14 inventors of 19 AI algorithms to train their algorithms, while our team, as a third party, independently evaluated these algorithms on three test sets. In addition, we also evaluated pre-existing AI frameworks--which, differing from algorithms, are more flexible and can support different algorithms--including MONAI from NVIDIA, nnU-Net from DKFZ, and numerous other open-source frameworks. We are committed to expanding this benchmark to encourage more innovation of AI algorithms for the medical domain.
Large-Scale 3D Medical Image Pre-training with Geometric Context Priors
Oct 13, 2024The scarcity of annotations poses a significant challenge in medical image analysis. Large-scale pre-training has emerged as a promising label-efficient solution, owing to the utilization of large-scale data, large models, and advanced pre-training techniques. However, its development in medical images remains underexplored. The primary challenge lies in harnessing large-scale unlabeled data and learning high-level semantics without annotations. We observe that 3D medical images exhibit consistent geometric context, i.e., consistent geometric relations between different organs, which leads to a promising way for learning consistent representations. Motivated by this, we introduce a simple-yet-effective Volume Contrast (VoCo) framework to leverage geometric context priors for self-supervision. Given an input volume, we extract base crops from different regions to construct positive and negative pairs for contrastive learning. Then we predict the contextual position of a random crop by contrasting its similarity to the base crops. In this way, VoCo encodes the inherent geometric context into model representations, facilitating high-level semantic learning without annotations. Specifically, we (1) introduce the largest medical pre-training dataset PreCT-160K; (2) investigate scaling laws and propose guidelines for tailoring different model sizes to various medical tasks; (3) build a benchmark encompassing 48 medical tasks. Extensive experiments highlight the superiority of VoCo. Codes at https://github.com/Luffy03/Large-Scale-Medical.
FreeTumor: Advance Tumor Segmentation via Large-Scale Tumor Synthesis
Jun 03, 2024



AI-driven tumor analysis has garnered increasing attention in healthcare. However, its progress is significantly hindered by the lack of annotated tumor cases, which requires radiologists to invest a lot of effort in collecting and annotation. In this paper, we introduce a highly practical solution for robust tumor synthesis and segmentation, termed FreeTumor, which refers to annotation-free synthetic tumors and our desire to free patients that suffering from tumors. Instead of pursuing sophisticated technical synthesis modules, we aim to design a simple yet effective tumor synthesis paradigm to unleash the power of large-scale data. Specifically, FreeTumor advances existing methods mainly from three aspects: (1) Existing methods only leverage small-scale labeled data for synthesis training, which limits their ability to generalize well on unseen data from different sources. To this end, we introduce the adversarial training strategy to leverage large-scale and diversified unlabeled data in synthesis training, significantly improving tumor synthesis. (2) Existing methods largely ignored the negative impact of low-quality synthetic tumors in segmentation training. Thus, we employ an adversarial-based discriminator to automatically filter out the low-quality synthetic tumors, which effectively alleviates their negative impact. (3) Existing methods only used hundreds of cases in tumor segmentation. In FreeTumor, we investigate the data scaling law in tumor segmentation by scaling up the dataset to 11k cases. Extensive experiments demonstrate the superiority of FreeTumor, e.g., on three tumor segmentation benchmarks, average $+8.9\%$ DSC over the baseline that only using real tumors and $+6.6\%$ DSC over the state-of-the-art tumor synthesis method. Code will be available.
MiM: Mask in Mask Self-Supervised Pre-Training for 3D Medical Image Analysis
Apr 24, 2024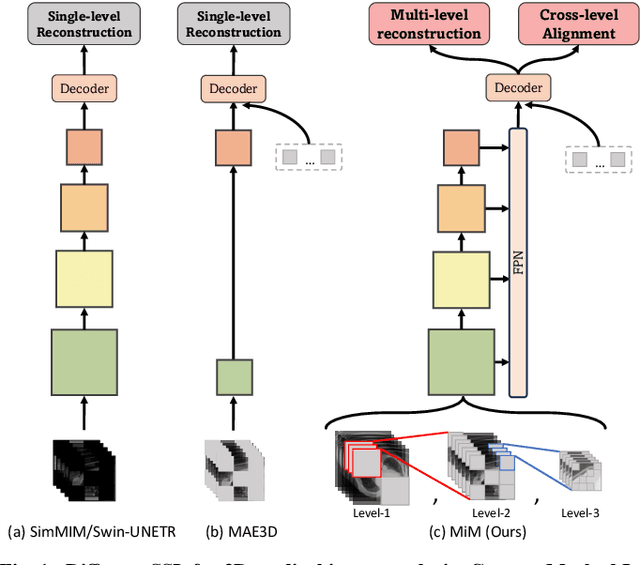
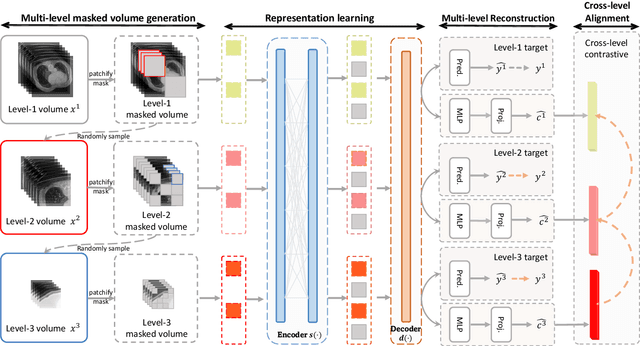
The Vision Transformer (ViT) has demonstrated remarkable performance in Self-Supervised Learning (SSL) for 3D medical image analysis. Mask AutoEncoder (MAE) for feature pre-training can further unleash the potential of ViT on various medical vision tasks. However, due to large spatial sizes with much higher dimensions of 3D medical images, the lack of hierarchical design for MAE may hinder the performance of downstream tasks. In this paper, we propose a novel \textit{Mask in Mask (MiM)} pre-training framework for 3D medical images, which aims to advance MAE by learning discriminative representation from hierarchical visual tokens across varying scales. We introduce multiple levels of granularity for masked inputs from the volume, which are then reconstructed simultaneously ranging at both fine and coarse levels. Additionally, a cross-level alignment mechanism is applied to adjacent level volumes to enforce anatomical similarity hierarchically. Furthermore, we adopt a hybrid backbone to enhance the hierarchical representation learning efficiently during the pre-training. MiM was pre-trained on a large scale of available 3D volumetric images, \textit{i.e.,} Computed Tomography (CT) images containing various body parts. Extensive experiments on thirteen public datasets demonstrate the superiority of MiM over other SSL methods in organ/lesion/tumor segmentation and disease classification. We further scale up the MiM to large pre-training datasets with more than 10k volumes, showing that large-scale pre-training can further enhance the performance of downstream tasks. The improvement also concluded that the research community should pay more attention to the scale of the pre-training dataset towards the healthcare foundation model for 3D medical images.
Modeling the Label Distributions for Weakly-Supervised Semantic Segmentation
Mar 20, 2024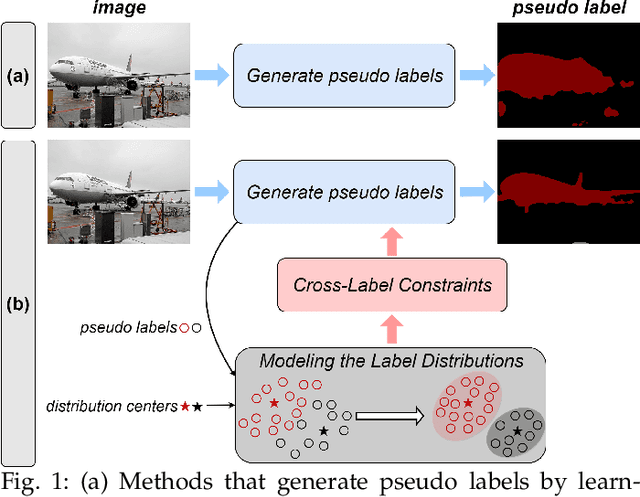



Weakly-Supervised Semantic Segmentation (WSSS) aims to train segmentation models by weak labels, which is receiving significant attention due to its low annotation cost. Existing approaches focus on generating pseudo labels for supervision while largely ignoring to leverage the inherent semantic correlation among different pseudo labels. We observe that pseudo-labeled pixels that are close to each other in the feature space are more likely to share the same class, and those closer to the distribution centers tend to have higher confidence. Motivated by this, we propose to model the underlying label distributions and employ cross-label constraints to generate more accurate pseudo labels. In this paper, we develop a unified WSSS framework named Adaptive Gaussian Mixtures Model, which leverages a GMM to model the label distributions. Specifically, we calculate the feature distribution centers of pseudo-labeled pixels and build the GMM by measuring the distance between the centers and each pseudo-labeled pixel. Then, we introduce an Online Expectation-Maximization (OEM) algorithm and a novel maximization loss to optimize the GMM adaptively, aiming to learn more discriminative decision boundaries between different class-wise Gaussian mixtures. Based on the label distributions, we leverage the GMM to generate high-quality pseudo labels for more reliable supervision. Our framework is capable of solving different forms of weak labels: image-level labels, points, scribbles, blocks, and bounding-boxes. Extensive experiments on PASCAL, COCO, Cityscapes, and ADE20K datasets demonstrate that our framework can effectively provide more reliable supervision and outperform the state-of-the-art methods under all settings. Code will be available at https://github.com/Luffy03/AGMM-SASS.