 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Multi-sequence Pretraining for Generalizable MRI Analysis in Versatile Clinical Applications
Aug 10, 2025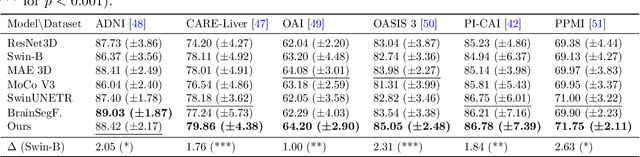
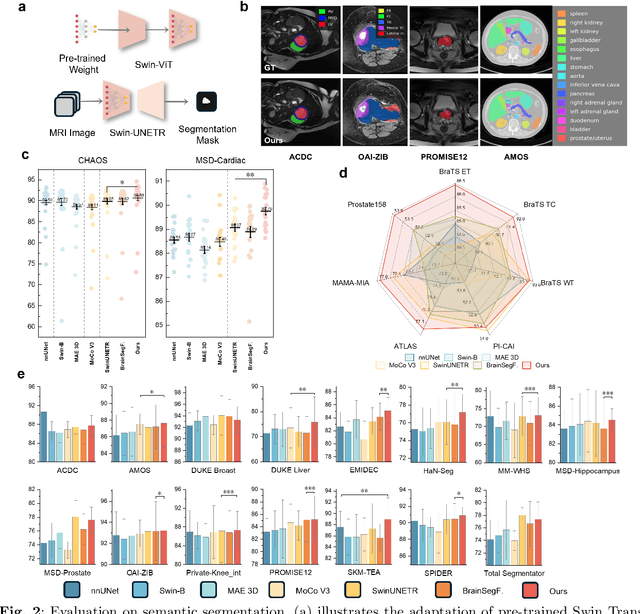
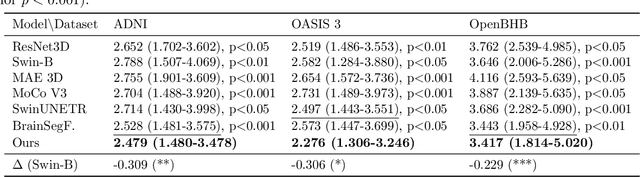
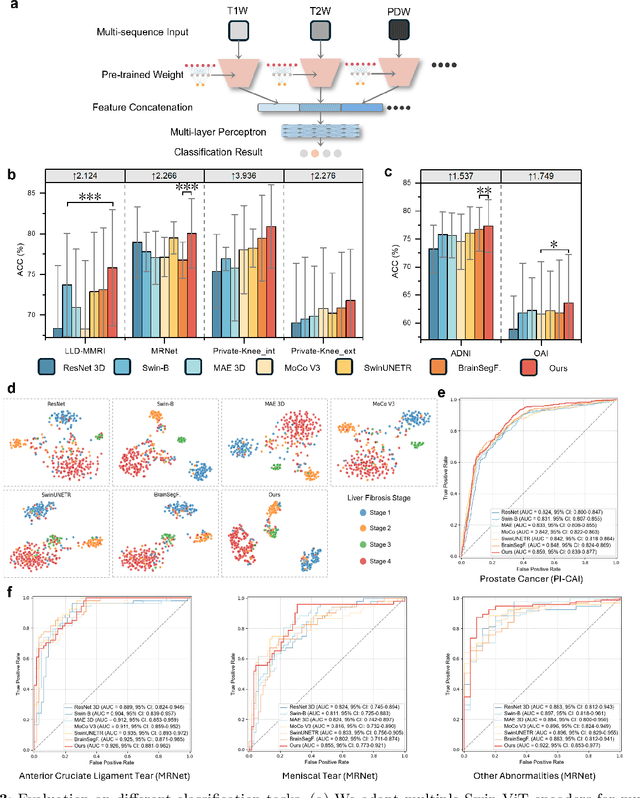
Multi-sequence Magnetic Resonance Imaging (MRI) offers remarkable versatility, enabling the distinct visualization of different tissue types. Nevertheless, the inherent heterogeneity among MRI sequences poses significant challenges to the generalization capability of deep learning models. These challenges undermine model performance when faced with varying acquisition parameters, thereby severely restricting their clinical utility. In this study, we present PRISM, a foundation model PRe-trained with large-scale multI-Sequence MRI. We collected a total of 64 datasets from both public and private sources, encompassing a wide range of whole-body anatomical structures, with scans spanning diverse MRI sequences. Among them, 336,476 volumetric MRI scans from 34 datasets (8 public and 26 private) were curated to construct the largest multi-organ multi-sequence MRI pretraining corpus to date. We propose a novel pretraining paradigm that disentangles anatomically invariant features from sequence-specific variations in MRI, while preserving high-level semantic representations. We established a benchmark comprising 44 downstream tasks, including disease diagnosis, image segmentation, registration, progression prediction, and report generation. These tasks were evaluated on 32 public datasets and 5 private cohorts. PRISM consistently outperformed both non-pretrained models and existing foundation models, achieving first-rank results in 39 out of 44 downstream benchmarks with statistical significance improvements. These results underscore its ability to learn robust and generalizable representations across unseen data acquired under diverse MRI protocols. PRISM provides a scalable framework for multi-sequence MRI analysis, thereby enhancing the translational potential of AI in radiology. It delivers consistent performance across diverse imaging protocols, reinforcing its clinical applicability.
FreeTumor: Large-Scale Generative Tumor Synthesis in Computed Tomography Images for Improving Tumor Recognition
Feb 23, 2025Tumor is a leading cause of death worldwide, with an estimated 10 million deaths attributed to tumor-related diseases every year. AI-driven tumor recognition unlocks new possibilities for more precise and intelligent tumor screening and diagnosis. However, the progress is heavily hampered by the scarcity of annotated datasets, which demands extensive annotation efforts by radiologists. To tackle this challenge, we introduce FreeTumor, an innovative Generative AI (GAI) framework to enable large-scale tumor synthesis for mitigating data scarcity. Specifically, FreeTumor effectively leverages a combination of limited labeled data and large-scale unlabeled data for tumor synthesis training. Unleashing the power of large-scale data, FreeTumor is capable of synthesizing a large number of realistic tumors on images for augmenting training datasets. To this end, we create the largest training dataset for tumor synthesis and recognition by curating 161,310 publicly available Computed Tomography (CT) volumes from 33 sources, with only 2.3% containing annotated tumors. To validate the fidelity of synthetic tumors, we engaged 13 board-certified radiologists in a Visual Turing Test to discern between synthetic and real tumors. Rigorous clinician evaluation validates the high quality of our synthetic tumors, as they achieved only 51.1% sensitivity and 60.8% accuracy in distinguishing our synthetic tumors from real ones. Through high-quality tumor synthesis, FreeTumor scales up the recognition training datasets by over 40 times, showcasing a notable superiority over state-of-the-art AI methods including various synthesis methods and foundation models. These findings indicate promising prospects of FreeTumor in clinical applications, potentially advancing tumor treatments and improving the survival rates of patients.
MG-3D: Multi-Grained Knowledge-Enhanced 3D Medical Vision-Language Pre-training
Dec 08, 2024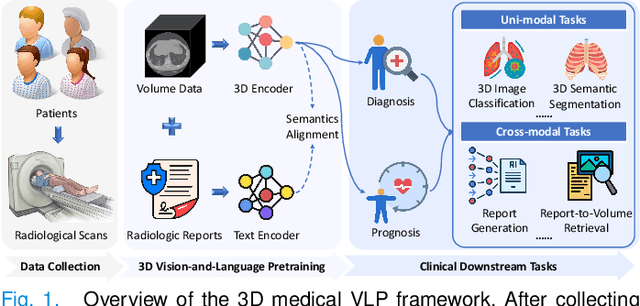

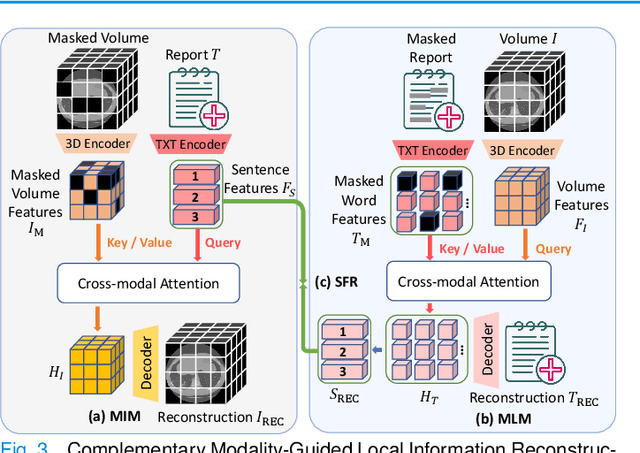

3D medical image analysis is pivotal in numerous clinical applications. However, the scarcity of labeled data and limited generalization capabilities hinder the advancement of AI-empowered models. Radiology reports are easily accessible and can serve as weakly-supervised signals. However, large-scale vision-language pre-training (VLP) remains underexplored in 3D medical image analysis. Specifically, the insufficient investigation into multi-grained radiology semantics and their correlations across patients leads to underutilization of large-scale volume-report data. Considering intra-patient cross-modal semantic consistency and inter-patient semantic correlations, we propose a multi-task VLP method, MG-3D, pre-trained on large-scale data (47.1K), addressing the challenges by the following two aspects: 1) Establishing the correspondence between volume semantics and multi-grained medical knowledge of each patient with cross-modal global alignment and complementary modality-guided local reconstruction, ensuring intra-patient features of different modalities cohesively represent the same semantic content; 2) Correlating inter-patient visual semantics based on fine-grained report correlations across patients, and keeping sensitivity to global individual differences via contrastive learning, enhancing the discriminative feature representation. Furthermore, we delve into the scaling law to explore potential performance improvements. Comprehensive evaluations across nine uni- and cross-modal clinical tasks are carried out to assess model efficacy. Extensive experiments on both internal and external datasets demonstrate the superior transferability, scalability, and generalization of MG-3D, showcasing its potential in advancing feature representation for 3D medical image analysis. Code will be available: https://github.com/Xuefeng-Ni/MG-3D.
MiM: Mask in Mask Self-Supervised Pre-Training for 3D Medical Image Analysis
Apr 24, 2024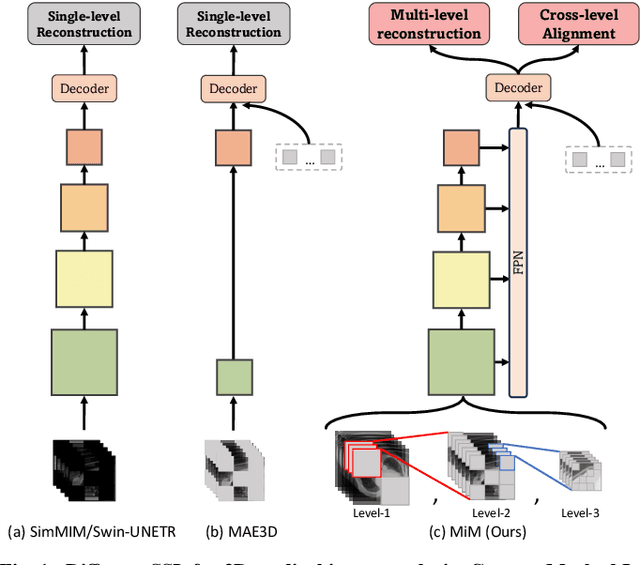
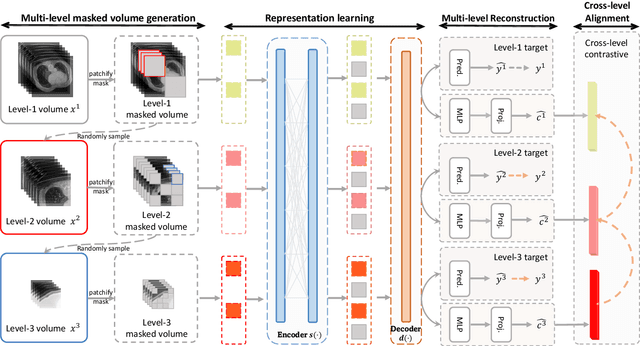
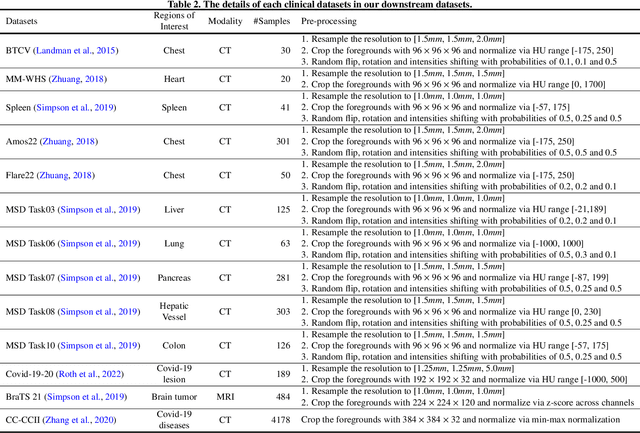
The Vision Transformer (ViT) has demonstrated remarkable performance in Self-Supervised Learning (SSL) for 3D medical image analysis. Mask AutoEncoder (MAE) for feature pre-training can further unleash the potential of ViT on various medical vision tasks. However, due to large spatial sizes with much higher dimensions of 3D medical images, the lack of hierarchical design for MAE may hinder the performance of downstream tasks. In this paper, we propose a novel \textit{Mask in Mask (MiM)} pre-training framework for 3D medical images, which aims to advance MAE by learning discriminative representation from hierarchical visual tokens across varying scales. We introduce multiple levels of granularity for masked inputs from the volume, which are then reconstructed simultaneously ranging at both fine and coarse levels. Additionally, a cross-level alignment mechanism is applied to adjacent level volumes to enforce anatomical similarity hierarchically. Furthermore, we adopt a hybrid backbone to enhance the hierarchical representation learning efficiently during the pre-training. MiM was pre-trained on a large scale of available 3D volumetric images, \textit{i.e.,} Computed Tomography (CT) images containing various body parts. Extensive experiments on thirteen public datasets demonstrate the superiority of MiM over other SSL methods in organ/lesion/tumor segmentation and disease classification. We further scale up the MiM to large pre-training datasets with more than 10k volumes, showing that large-scale pre-training can further enhance the performance of downstream tasks. The improvement also concluded that the research community should pay more attention to the scale of the pre-training dataset towards the healthcare foundation model for 3D medical images.
AdaMedGraph: Adaboosting Graph Neural Networks for Personalized Medicine
Nov 24, 2023Precision medicine tailored to individual patients has gained significant attention in recent times. Machine learning techniques are now employed to process personalized data from various sources, including images, genetics, and assessments. These techniques have demonstrated good outcomes in many clinical prediction tasks. Notably, the approach of constructing graphs by linking similar patients and then applying graph neural networks (GNNs) stands out, because related information from analogous patients are aggregated and considered for prediction. However, selecting the appropriate edge feature to define patient similarity and construct the graph is challenging, given that each patient is depicted by high-dimensional features from diverse sources. Previous studies rely on human expertise to select the edge feature, which is neither scalable nor efficient in pinpointing crucial edge features for complex diseases. In this paper, we propose a novel algorithm named \ours, which can automatically select important features to construct multiple patient similarity graphs, and train GNNs based on these graphs as weak learners in adaptive boosting. \ours{} is evaluated on two real-world medical scenarios and shows superiors performance.
Deep Learning in Breast Cancer Imaging: A Decade of Progress and Future Directions
Apr 27, 2023



Breast cancer has reached the highest incidence rate worldwide among all malignancies since 2020. Breast imaging plays a significant role in early diagnosis and intervention to improve the outcome of breast cancer patients. In the past decade, deep learning has shown remarkable progress in breast cancer imaging analysis, holding great promise in interpreting the rich information and complex context of breast imaging modalities. Considering the rapid improvement in the deep learning technology and the increasing severity of breast cancer, it is critical to summarize past progress and identify future challenges to be addressed. In this paper, we provide an extensive survey of deep learning-based breast cancer imaging research, covering studies on mammogram, ultrasound, magnetic resonance imaging, and digital pathology images over the past decade. The major deep learning methods, publicly available datasets, and applications on imaging-based screening, diagnosis, treatment response prediction, and prognosis are described in detail. Drawn from the findings of this survey, we present a comprehensive discussion of the challenges and potential avenues for future research in deep learning-based breast cancer imaging.
Beta-Rank: A Robust Convolutional Filter Pruning Method For Imbalanced Medical Image Analysis
Apr 15, 2023
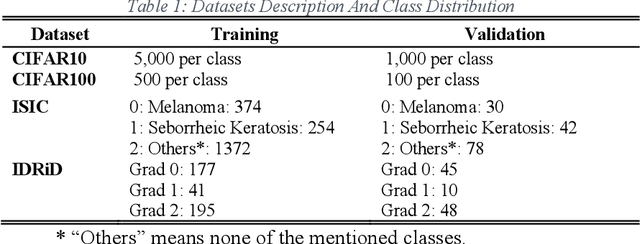
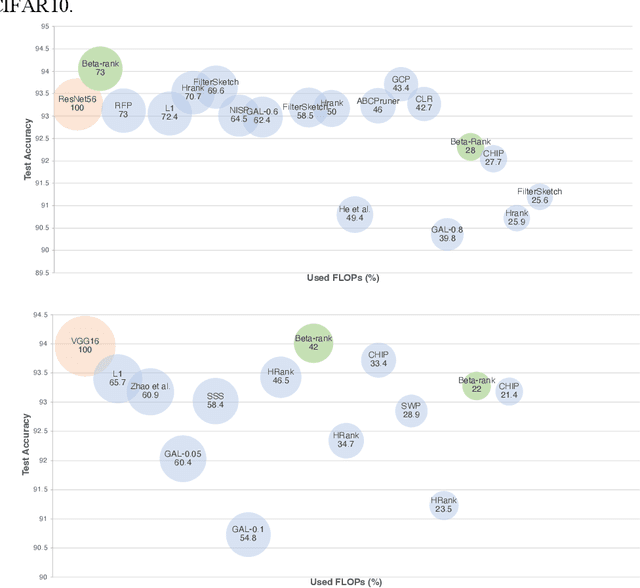
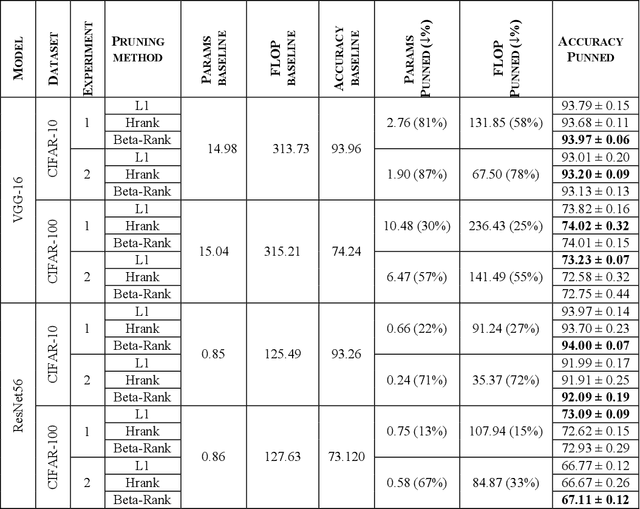
As deep neural networks include a high number of parameters and operations, it can be a challenge to implement these models on devices with limited computational resources. Despite the development of novel pruning methods toward resource-efficient models, it has become evident that these models are not capable of handling "imbalanced" and "limited number of data points". With input and output information, along with the values of the filters, a novel filter pruning method is proposed. Our pruning method considers the fact that all information about the importance of a filter may not be reflected in the value of the filter. Instead, it is reflected in the changes made to the data after the filter is applied to it. In this work, three methods are compared with the same training conditions except for the ranking of each method. We demonstrated that our model performed significantly better than other methods for medical datasets which are inherently imbalanced. When we removed up to 58% of FLOPs for the IDRID dataset and up to 45% for the ISIC dataset, our model was able to yield an equivalent (or even superior) result to the baseline model while other models were unable to achieve similar results. To evaluate FLOP and parameter reduction using our model in real-world settings, we built a smartphone app, where we demonstrated a reduction of up to 79% in memory usage and 72% in prediction time. All codes and parameters for training different models are available at https://github.com/mohofar/Beta-Rank
Multi-Granularity Cross-modal Alignment for Generalized Medical Visual Representation Learning
Oct 12, 2022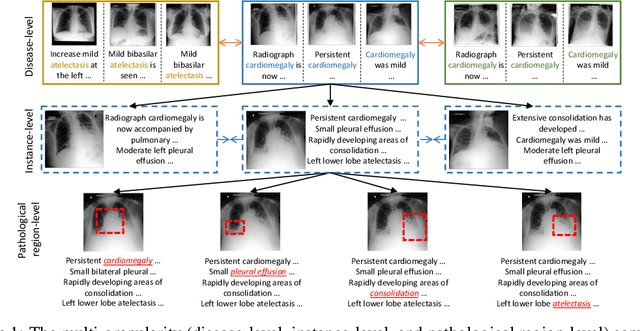
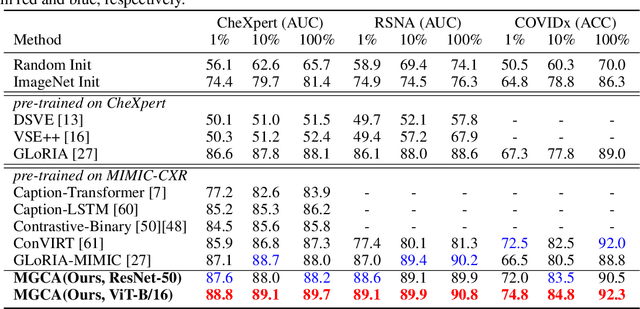

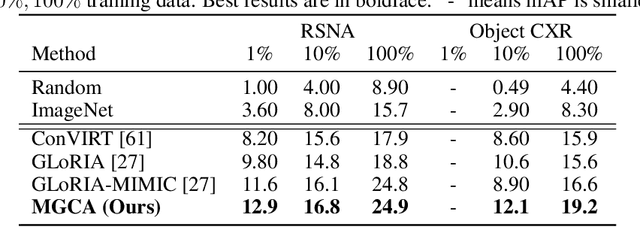
Learning medical visual representations directly from paired radiology reports has become an emerging topic in representation learning. However, existing medical image-text joint learning methods are limited by instance or local supervision analysis, ignoring disease-level semantic correspondences. In this paper, we present a novel Multi-Granularity Cross-modal Alignment (MGCA) framework for generalized medical visual representation learning by harnessing the naturally exhibited semantic correspondences between medical image and radiology reports at three different levels, i.e., pathological region-level, instance-level, and disease-level. Specifically, we first incorporate the instance-wise alignment module by maximizing the agreement between image-report pairs. Further, for token-wise alignment, we introduce a bidirectional cross-attention strategy to explicitly learn the matching between fine-grained visual tokens and text tokens, followed by contrastive learning to align them. More important, to leverage the high-level inter-subject relationship semantic (e.g., disease) correspondences, we design a novel cross-modal disease-level alignment paradigm to enforce the cross-modal cluster assignment consistency. Extensive experimental results on seven downstream medical image datasets covering image classification, object detection, and semantic segmentation tasks demonstrate the stable and superior performance of our framework.
Rethinking annotation granularity for overcoming deep shortcut learning: A retrospective study on chest radiographs
Apr 21, 2021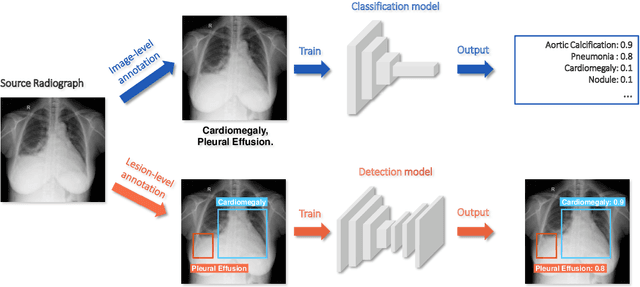
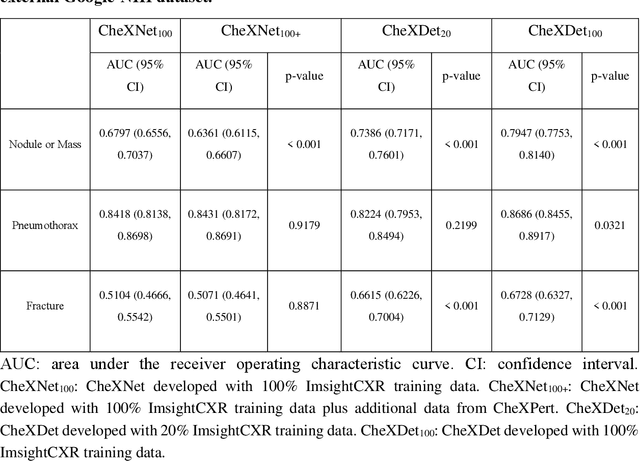
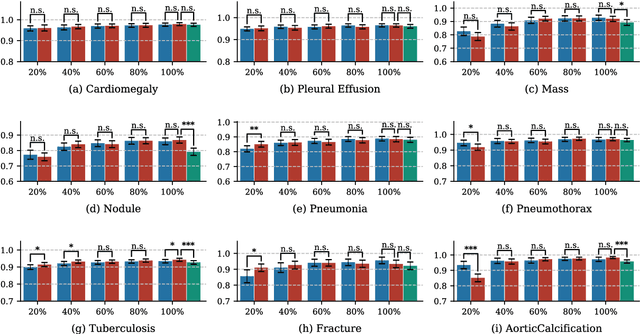
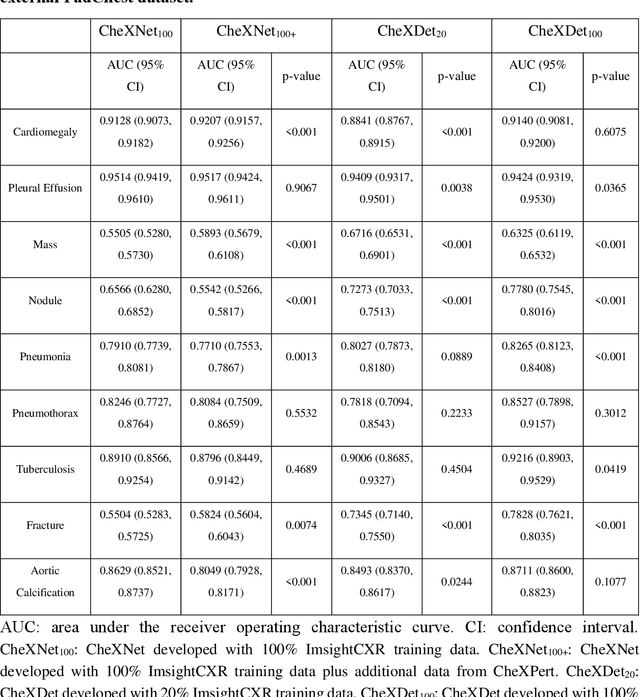
Deep learning has demonstrated radiograph screening performances that are comparable or superior to radiologists. However, recent studies show that deep models for thoracic disease classification usually show degraded performance when applied to external data. Such phenomena can be categorized into shortcut learning, where the deep models learn unintended decision rules that can fit the identically distributed training and test set but fail to generalize to other distributions. A natural way to alleviate this defect is explicitly indicating the lesions and focusing the model on learning the intended features. In this paper, we conduct extensive retrospective experiments to compare a popular thoracic disease classification model, CheXNet, and a thoracic lesion detection model, CheXDet. We first showed that the two models achieved similar image-level classification performance on the internal test set with no significant differences under many scenarios. Meanwhile, we found incorporating external training data even led to performance degradation for CheXNet. Then, we compared the models' internal performance on the lesion localization task and showed that CheXDet achieved significantly better performance than CheXNet even when given 80% less training data. By further visualizing the models' decision-making regions, we revealed that CheXNet learned patterns other than the target lesions, demonstrating its shortcut learning defect. Moreover, CheXDet achieved significantly better external performance than CheXNet on both the image-level classification task and the lesion localization task. Our findings suggest improving annotation granularity for training deep learning systems as a promising way to elevate future deep learning-based diagnosis systems for clinical usage.