 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentions Under the Microscope: A Comparative Study of Resource Utilization for Variants of Self-Attention
Jul 09, 2025As large language models (LLMs) and visual language models (VLMs) grow in scale and application, attention mechanisms have become a central computational bottleneck due to their high memory and time complexity. While many efficient attention variants have been proposed, there remains a lack of rigorous evaluation on their actual energy usage and hardware resource demands during training. In this work, we benchmark eight attention mechanisms in training GPT-2 architecture, measuring key metrics including training time, GPU memory usage, FLOPS, CPU usage, and power consumption. Our results reveal that attention mechanisms with optimized kernel implementations, including Flash Attention, Locality-Sensitive Hashing (LSH) Attention, and Multi-Head Latent Attention (MLA), achieve the best energy efficiency. We further show that lower GPU power alone does not guarantee reduced energy use, as training time plays an equally important role. Our study highlights the importance of energy-aware benchmarking in attention design and provides a practical insight for selecting resource-efficient mechanisms. All our codes are available at GitHub.
Analyzing the Resource Utilization of Lambda Functions on Mobile Devices: Case Studies on Kotlin and Swift
Feb 07, 2025With billions of smartphones in use globally, the daily time spent on these devices contributes significantly to overall electricity consumption. Given this scale, even minor reductions in smartphone power use could result in substantial energy savings. This study explores the impact of Lambda functions on resource consumption in mobile programming. While Lambda functions are known for enhancing code readability and conciseness, their use does not add to the functional capabilities of a programming language. Our research investigates the implications of using Lambda functions in terms of battery utilization, memory usage, and execution time compared to equivalent code structures without Lambda functions. Our findings reveal that Lambda functions impose a considerable resource overhead on mobile devices without offering additional functionalities.
The Impact of Quantization and Pruning on Deep Reinforcement Learning Models
Jul 05, 2024



Deep reinforcement learning (DRL) has achieved remarkable success across various domains, such as video games, robotics, and, recently, large language models. However, the computational costs and memory requirements of DRL models often limit their deployment in resource-constrained environments. The challenge underscores the urgent need to explore neural network compression methods to make RDL models more practical and broadly applicable. Our study investigates the impact of two prominent compression methods, quantization and pruning on DRL models. We examine how these techniques influence four performance factors: average return, memory, inference time, and battery utilization across various DRL algorithms and environments. Despite the decrease in model size, we identify that these compression techniques generally do not improve the energy efficiency of DRL models, but the model size decreases. We provide insights into the trade-offs between model compression and DRL performance, offering guidelines for deploying efficient DRL models in resource-constrained settings.
Can LLMs substitute SQL? Comparing Resource Utilization of Querying LLMs versus Traditional Relational Databases
Apr 12, 2024
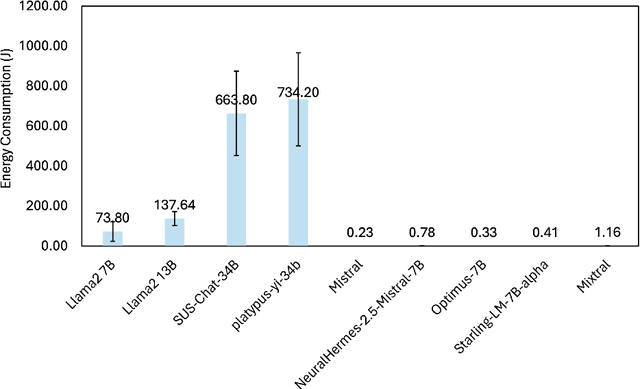


Large Language Models (LLMs) can automate or substitute different types of tasks in the software engineering process. This study evaluates the resource utilization and accuracy of LLM in interpreting and executing natural language queries against traditional SQL within relational database management systems. We empirically examine the resource utilization and accuracy of nine LLMs varying from 7 to 34 Billion parameters, including Llama2 7B, Llama2 13B, Mistral, Mixtral, Optimus-7B, SUS-chat-34B, platypus-yi-34b, NeuralHermes-2.5-Mistral-7B and Starling-LM-7B-alpha, using a small transaction dataset. Our findings indicate that using LLMs for database queries incurs significant energy overhead (even small and quantized models), making it an environmentally unfriendly approach. Therefore, we advise against replacing relational databases with LLMs due to their substantial resource utilization.
Augmenting Vision-Based Human Pose Estimation with Rotation Matrix
Oct 09, 2023



Fitness applications are commonly used to monitor activities within the gym, but they often fail to automatically track indoor activities inside the gym. This study proposes a model that utilizes pose estimation combined with a novel data augmentation method, i.e., rotation matrix. We aim to enhance the classification accuracy of activity recognition based on pose estimation data. Through our experiments, we experiment with different classification algorithms along with image augmentation approaches. Our findings demonstrate that the SVM with SGD optimization, using data augmentation with the Rotation Matrix, yields the most accurate results, achieving a 96% accuracy rate in classifying five physical activities. Conversely, without implementing the data augmentation techniques, the baseline accuracy remains at a modest 64%.
A Survey of AI Music Generation Tools and Models
Aug 24, 2023In this work, we provide a comprehensive survey of AI music generation tools, including both research projects and commercialized applications. To conduct our analysis, we classified music generation approaches into three categories: parameter-based, text-based, and visual-based classes. Our survey highlights the diverse possibilities and functional features of these tools, which cater to a wide range of users, from regular listeners to professional musicians. We observed that each tool has its own set of advantages and limitations. As a result, we have compiled a comprehensive list of these factors that should be considered during the tool selection process. Moreover, our survey offers critical insights into the underlying mechanisms and challenges of AI music generation.
Beta-Rank: A Robust Convolutional Filter Pruning Method For Imbalanced Medical Image Analysis
Apr 15, 2023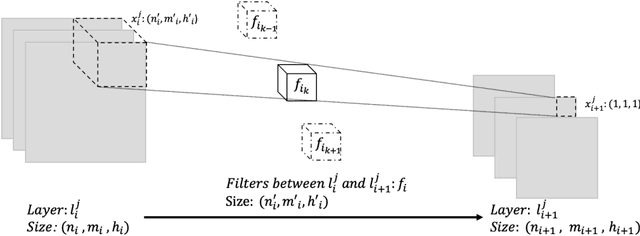
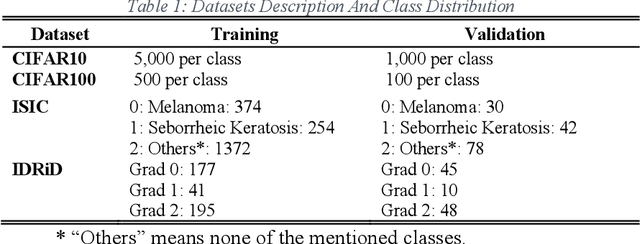
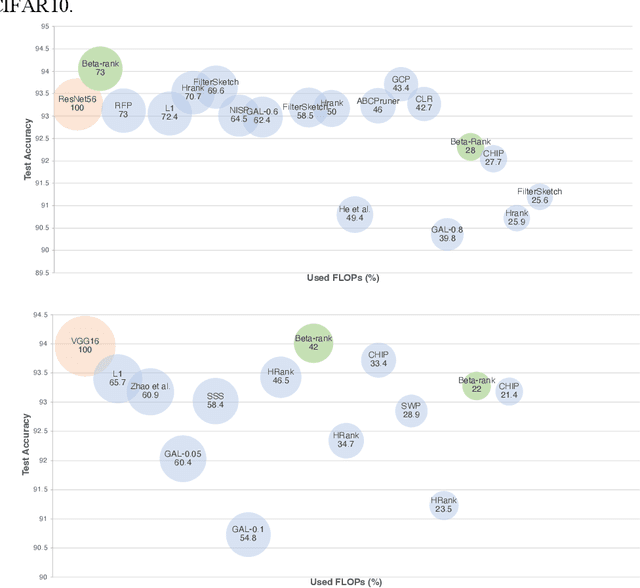
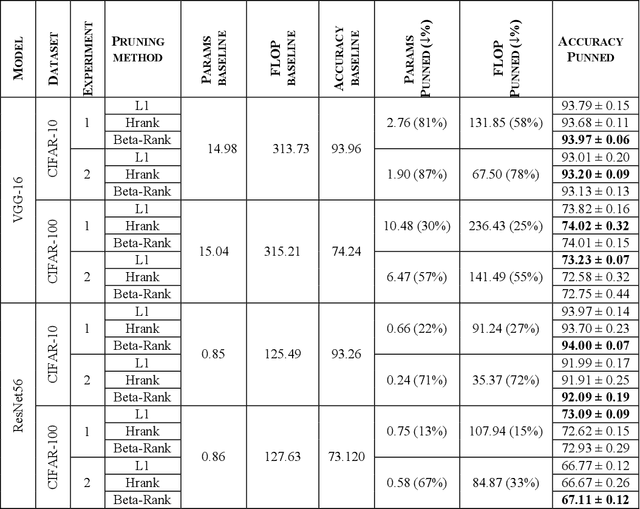
As deep neural networks include a high number of parameters and operations, it can be a challenge to implement these models on devices with limited computational resources. Despite the development of novel pruning methods toward resource-efficient models, it has become evident that these models are not capable of handling "imbalanced" and "limited number of data points". With input and output information, along with the values of the filters, a novel filter pruning method is proposed. Our pruning method considers the fact that all information about the importance of a filter may not be reflected in the value of the filter. Instead, it is reflected in the changes made to the data after the filter is applied to it. In this work, three methods are compared with the same training conditions except for the ranking of each method. We demonstrated that our model performed significantly better than other methods for medical datasets which are inherently imbalanced. When we removed up to 58% of FLOPs for the IDRID dataset and up to 45% for the ISIC dataset, our model was able to yield an equivalent (or even superior) result to the baseline model while other models were unable to achieve similar results. To evaluate FLOP and parameter reduction using our model in real-world settings, we built a smartphone app, where we demonstrated a reduction of up to 79% in memory usage and 72% in prediction time. All codes and parameters for training different models are available at https://github.com/mohofar/Beta-Rank
LightDepth: A Resource Efficient Depth Estimation Approach for Dealing with Ground Truth Sparsity via Curriculum Learning
Nov 19, 2022



Advances in neural networks enable tackling complex computer vision tasks such as depth estimation of outdoor scenes at unprecedented accuracy. Promising research has been done on depth estimation. However, current efforts are computationally resource-intensive and do not consider the resource constraints of autonomous devices, such as robots and drones. In this work, we present a fast and battery-efficient approach for depth estimation. Our approach devises model-agnostic curriculum-based learning for depth estimation. Our experiments show that the accuracy of our model performs on par with the state-of-the-art models, while its response time outperforms other models by 71%. All codes are available online at https://github.com/fatemehkarimii/LightDepth.
Speeding Up Question Answering Task of Language Models via Inverted Index
Oct 24, 2022



Natural language processing applications, such as conversational agents and their question-answering capabilities, are widely used in the real world. Despite the wide popularity of large language models (LLMs), few real-world conversational agents take advantage of LLMs. Extensive resources consumed by LLMs disable developers from integrating them into end-user applications. In this study, we leverage an inverted indexing mechanism combined with LLMs to improve the efficiency of question-answering models for closed-domain questions. Our experiments show that using the index improves the average response time by 97.44%. In addition, due to the reduced search scope, the average BLEU score improved by 0.23 while using the inverted index.
ODSearch: A Fast and Resource Efficient On-device Information Retrieval for Mobile and Wearable Devices
Jan 31, 2022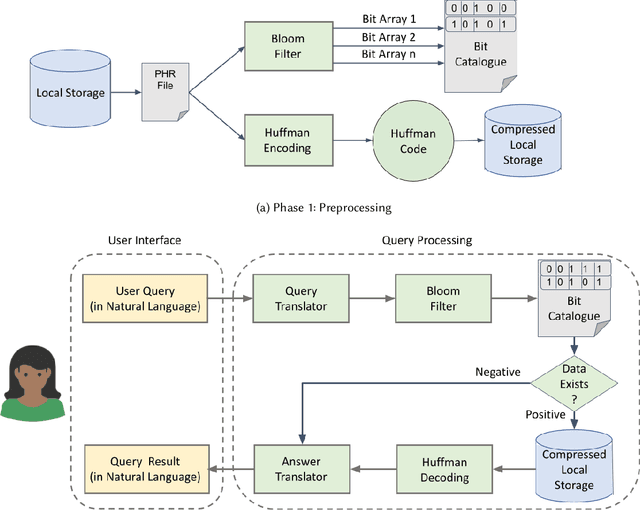
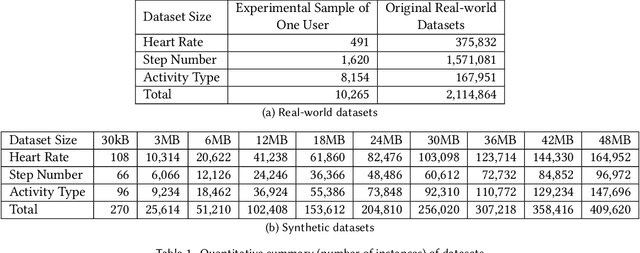
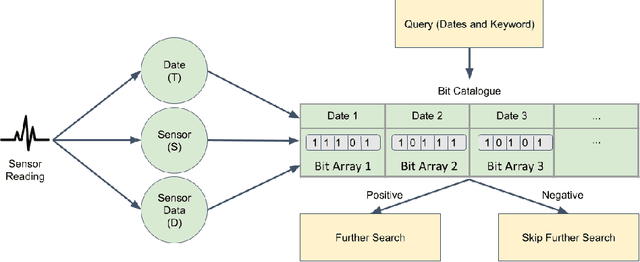

Mobile and wearable technologies have promised significant changes to the healthcare industry. Although cutting-edge communication and cloud-based technologies have allowed for these upgrades, their implementation and popularization in low-income countries have been challenging. We propose ODSearch, an On-device Search framework equipped with a natural language interface for mobile and wearable devices. To implement search, ODSearch employs compression and Bloom filter, it provides near real-time search query responses without network dependency. Our experiments were conducted on a mobile phone and smartwatch. We compared ODSearch with current state-of-the-art search mechanisms, and it outperformed them on average by 55 times in execution time, 26 times in energy usage, and 2.3% in memory utilization.