 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINCEPTNET: Precise And Early Disease Detection Application For Medical Images Analyses
Sep 05, 2023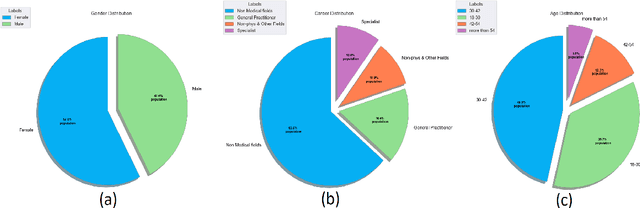



In view of the recent paradigm shift in deep AI based image processing methods, medical image processing has advanced considerably. In this study, we propose a novel deep neural network (DNN), entitled InceptNet, in the scope of medical image processing, for early disease detection and segmentation of medical images in order to enhance precision and performance. We also investigate the interaction of users with the InceptNet application to present a comprehensive application including the background processes, and foreground interactions with users. Fast InceptNet is shaped by the prominent Unet architecture, and it seizes the power of an Inception module to be fast and cost effective while aiming to approximate an optimal local sparse structure. Adding Inception modules with various parallel kernel sizes can improve the network's ability to capture the variations in the scaled regions of interest. To experiment, the model is tested on four benchmark datasets, including retina blood vessel segmentation, lung nodule segmentation, skin lesion segmentation, and breast cancer cell detection. The improvement was more significant on images with small scale structures. The proposed method improved the accuracy from 0.9531, 0.8900, 0.9872, and 0.9881 to 0.9555, 0.9510, 0.9945, and 0.9945 on the mentioned datasets, respectively, which show outperforming of the proposed method over the previous works. Furthermore, by exploring the procedure from start to end, individuals who have utilized a trial edition of InceptNet, in the form of a complete application, are presented with thirteen multiple choice questions in order to assess the proposed method. The outcomes are evaluated through the means of Human Computer Interaction.
FEDZIP: A Compression Framework for Communication-Efficient Federated Learning
Feb 02, 2021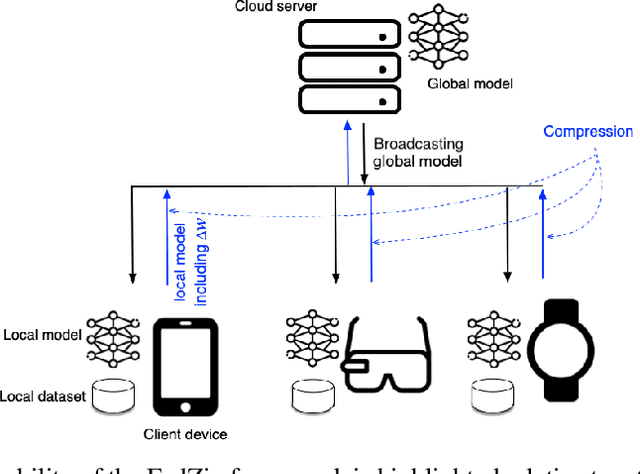
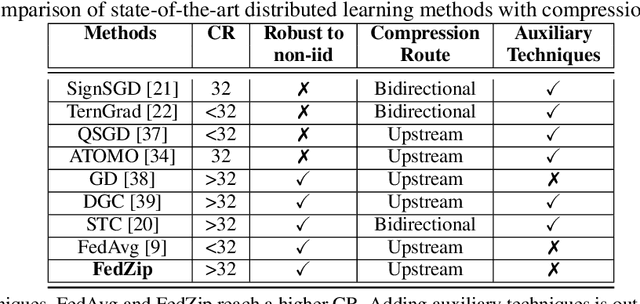
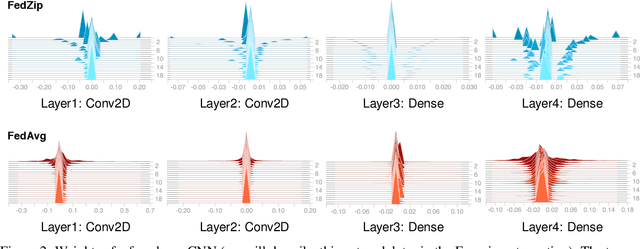
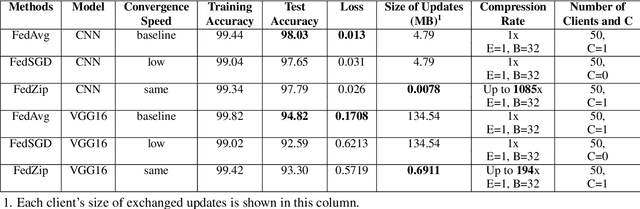
Federated Learning marks a turning point in the implementation of decentralized machine learning (especially deep learning) for wireless devices by protecting users' privacy and safeguarding raw data from third-party access. It assigns the learning process independently to each client. First, clients locally train a machine learning model based on local data. Next, clients transfer local updates of model weights and biases (training data) to a server. Then, the server aggregates updates (received from clients) to create a global learning model. However, the continuous transfer between clients and the server increases communication costs and is inefficient from a resource utilization perspective due to the large number of parameters (weights and biases) used by deep learning models. The cost of communication becomes a greater concern when the number of contributing clients and communication rounds increases. In this work, we propose a novel framework, FedZip, that significantly decreases the size of updates while transferring weights from the deep learning model between clients and their servers. FedZip implements Top-z sparsification, uses quantization with clustering, and implements compression with three different encoding methods. FedZip outperforms state-of-the-art compression frameworks and reaches compression rates up to 1085x, and preserves up to 99% of bandwidth and 99% of energy for clients during communication.