 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEDZIP: A Compression Framework for Communication-Efficient Federated Learning
Feb 02, 2021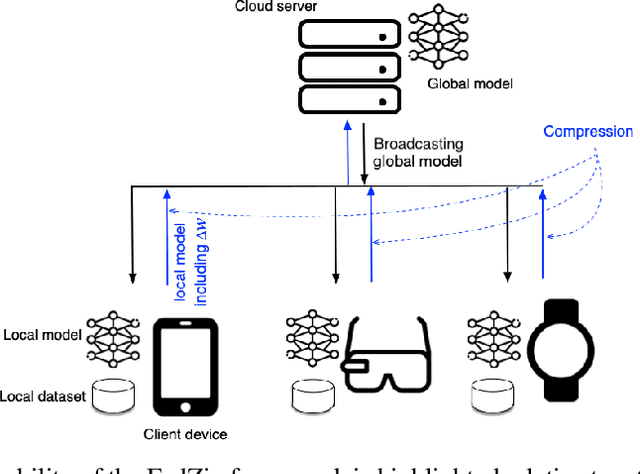
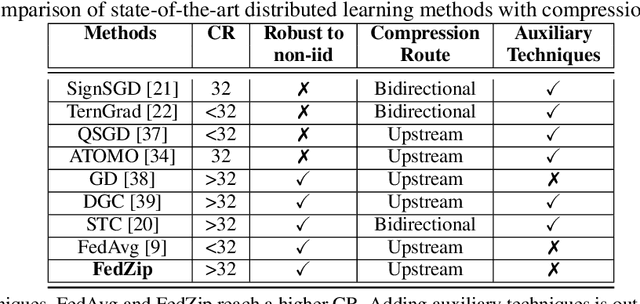
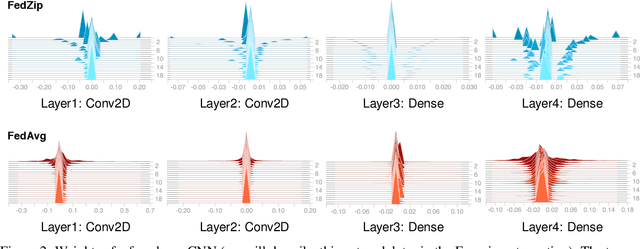
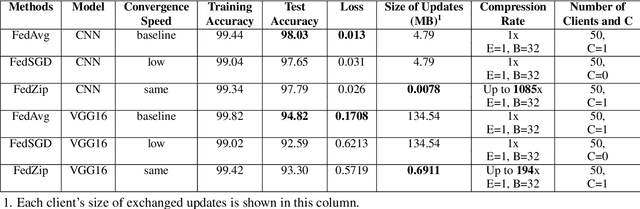
Federated Learning marks a turning point in the implementation of decentralized machine learning (especially deep learning) for wireless devices by protecting users' privacy and safeguarding raw data from third-party access. It assigns the learning process independently to each client. First, clients locally train a machine learning model based on local data. Next, clients transfer local updates of model weights and biases (training data) to a server. Then, the server aggregates updates (received from clients) to create a global learning model. However, the continuous transfer between clients and the server increases communication costs and is inefficient from a resource utilization perspective due to the large number of parameters (weights and biases) used by deep learning models. The cost of communication becomes a greater concern when the number of contributing clients and communication rounds increases. In this work, we propose a novel framework, FedZip, that significantly decreases the size of updates while transferring weights from the deep learning model between clients and their servers. FedZip implements Top-z sparsification, uses quantization with clustering, and implements compression with three different encoding methods. FedZip outperforms state-of-the-art compression frameworks and reaches compression rates up to 1085x, and preserves up to 99% of bandwidth and 99% of energy for clients during communication.