 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Speech Synthesis with Context-Aware Memory
Aug 20, 2025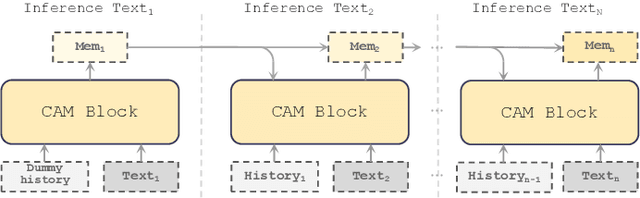
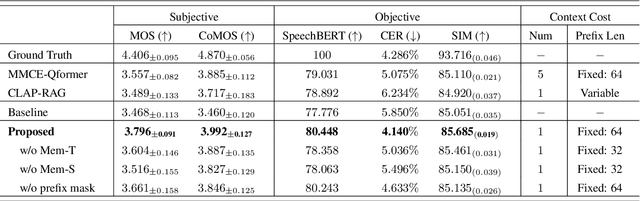
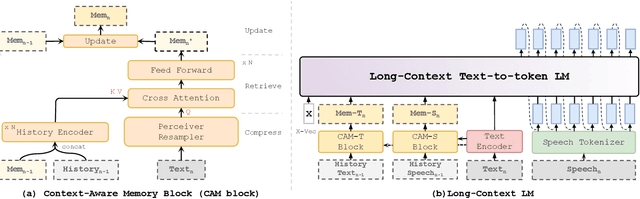
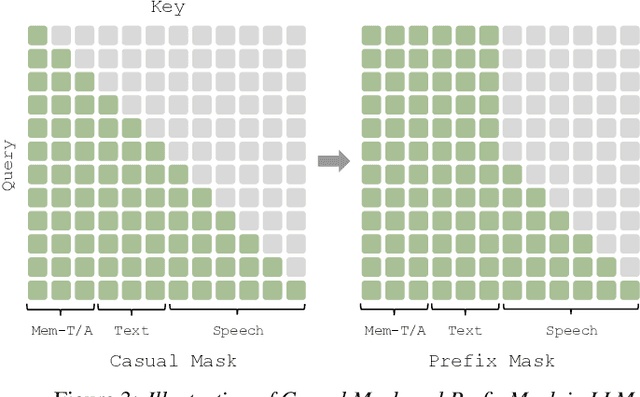
In long-text speech synthesis, current approaches typically convert text to speech at the sentence-level and concatenate the results to form pseudo-paragraph-level speech. These methods overlook the contextual coherence of paragraphs, leading to reduced naturalness and inconsistencies in style and timbre across the long-form speech. To address these issues, we propose a Context-Aware Memory (CAM)-based long-context Text-to-Speech (TTS) model. The CAM block integrates and retrieves both long-term memory and local context details, enabling dynamic memory updates and transfers within long paragraphs to guide sentence-level speech synthesis. Furthermore, the prefix mask enhances the in-context learning ability by enabling bidirectional attention on prefix tokens while maintaining unidirectional generation. Experimental results demonstrate that the proposed method outperforms baseline and state-of-the-art long-context methods in terms of prosody expressiveness, coherence and context inference cost across paragraph-level speech.
Towards Efficient Speech-Text Jointly Decoding within One Speech Language Model
Jun 04, 2025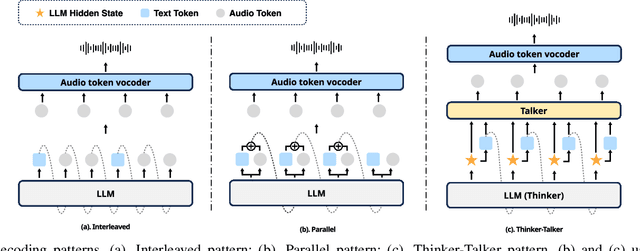
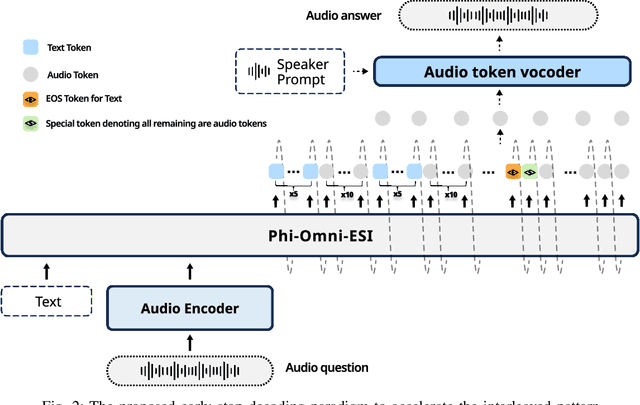


Speech language models (Speech LMs) enable end-to-end speech-text modelling within a single model, offering a promising direction for spoken dialogue systems. The choice of speech-text jointly decoding paradigm plays a critical role in performance, efficiency, and alignment quality. In this work, we systematically compare representative joint speech-text decoding strategies-including the interleaved, and parallel generation paradigms-under a controlled experimental setup using the same base language model, speech tokenizer and training data. Our results show that the interleaved approach achieves the best alignment. However it suffers from slow inference due to long token sequence length. To address this, we propose a novel early-stop interleaved (ESI) pattern that not only significantly accelerates decoding but also yields slightly better performance. Additionally, we curate high-quality question answering (QA) datasets to further improve speech QA performance.
Phi-Omni-ST: A multimodal language model for direct speech-to-speech translation
Jun 04, 2025Speech-aware language models (LMs) have demonstrated capabilities in understanding spoken language while generating text-based responses. However, enabling them to produce speech output efficiently and effectively remains a challenge. In this paper, we present Phi-Omni-ST, a multimodal LM for direct speech-to-speech translation (ST), built on the open-source Phi-4 MM model. Phi-Omni-ST extends its predecessor by generating translated speech using an audio transformer head that predicts audio tokens with a delay relative to text tokens, followed by a streaming vocoder for waveform synthesis. Our experimental results on the CVSS-C dataset demonstrate Phi-Omni-ST's superior performance, significantly surpassing existing baseline models trained on the same dataset. Furthermore, when we scale up the training data and the model size, Phi-Omni-ST reaches on-par performance with the current SOTA model.
Unispeaker: A Unified Approach for Multimodality-driven Speaker Generation
Jan 11, 2025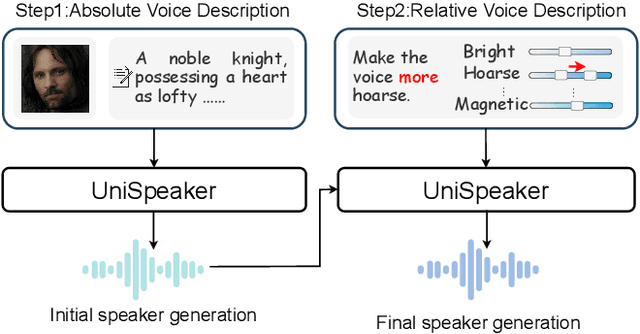
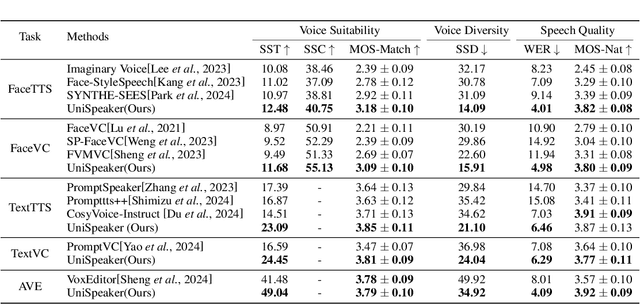
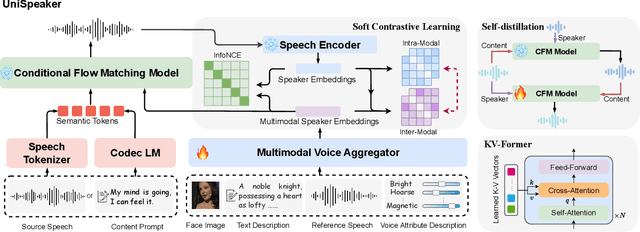
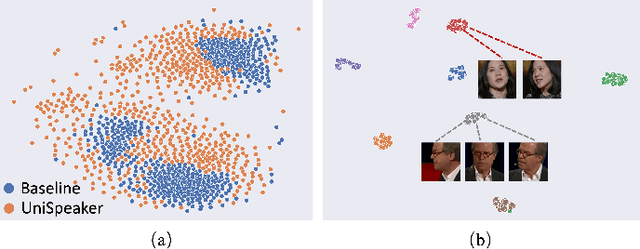
Recent advancements in personalized speech generation have brought synthetic speech increasingly close to the realism of target speakers' recordings, yet multimodal speaker generation remains on the rise. This paper introduces UniSpeaker, a unified approach for multimodality-driven speaker generation. Specifically, we propose a unified voice aggregator based on KV-Former, applying soft contrastive loss to map diverse voice description modalities into a shared voice space, ensuring that the generated voice aligns more closely with the input descriptions. To evaluate multimodality-driven voice control, we build the first multimodality-based voice control (MVC) benchmark, focusing on voice suitability, voice diversity, and speech quality. UniSpeaker is evaluated across five tasks using the MVC benchmark, and the experimental results demonstrate that UniSpeaker outperforms previous modality-specific models. Speech samples are available at \url{https://UniSpeaker.github.io}.
FlashAudio: Rectified Flows for Fast and High-Fidelity Text-to-Audio Generation
Oct 16, 2024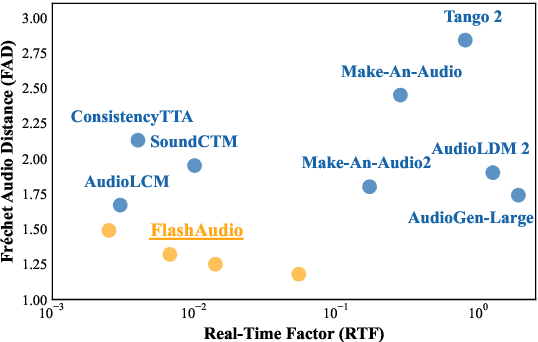

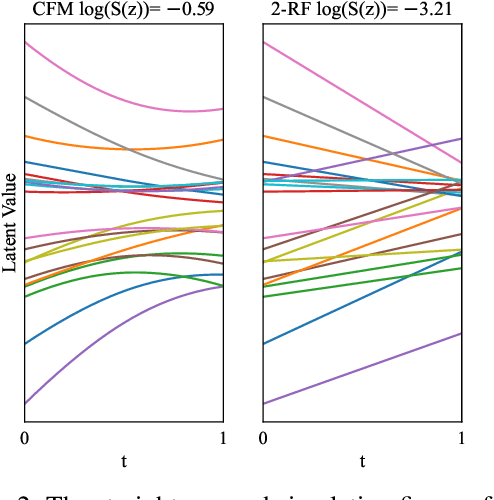

Recent advancements in latent diffusion models (LDMs) have markedly enhanced text-to-audio generation, yet their iterative sampling processes impose substantial computational demands, limiting practical deployment. While recent methods utilizing consistency-based distillation aim to achieve few-step or single-step inference, their one-step performance is constrained by curved trajectories, preventing them from surpassing traditional diffusion models. In this work, we introduce FlashAudio with rectified flows to learn straight flow for fast simulation. To alleviate the inefficient timesteps allocation and suboptimal distribution of noise, FlashAudio optimizes the time distribution of rectified flow with Bifocal Samplers and proposes immiscible flow to minimize the total distance of data-noise pairs in a batch vias assignment. Furthermore, to address the amplified accumulation error caused by the classifier-free guidance (CFG), we propose Anchored Optimization, which refines the guidance scale by anchoring it to a reference trajectory. Experimental results on text-to-audio generation demonstrate that FlashAudio's one-step generation performance surpasses the diffusion-based models with hundreds of sampling steps on audio quality and enables a sampling speed of 400x faster than real-time on a single NVIDIA 4090Ti GPU.
IntrinsicVoice: Empowering LLMs with Intrinsic Real-time Voice Interaction Abilities
Oct 09, 2024



Current methods of building LLMs with voice interaction capabilities rely heavily on explicit text autoregressive generation before or during speech response generation to maintain content quality, which unfortunately brings computational overhead and increases latency in multi-turn interactions. To address this, we introduce IntrinsicVoic,e an LLM designed with intrinsic real-time voice interaction capabilities. IntrinsicVoice aims to facilitate the transfer of textual capabilities of pre-trained LLMs to the speech modality by mitigating the modality gap between text and speech. Our novelty architecture, GroupFormer, can reduce speech sequences to lengths comparable to text sequences while generating high-quality audio, significantly reducing the length difference between speech and text, speeding up inference, and alleviating long-text modeling issues. Additionally, we construct a multi-turn speech-to-speech dialogue dataset named \method-500k which includes nearly 500k turns of speech-to-speech dialogues, and a cross-modality training strategy to enhance the semantic alignment between speech and text. Experimental results demonstrate that IntrinsicVoice can generate high-quality speech response with latency lower than 100ms in multi-turn dialogue scenarios. Demos are available at https://instrinsicvoice.github.io/.
Deep Learning Meets OBIA: Tasks, Challenges, Strategies, and Perspectives
Aug 02, 2024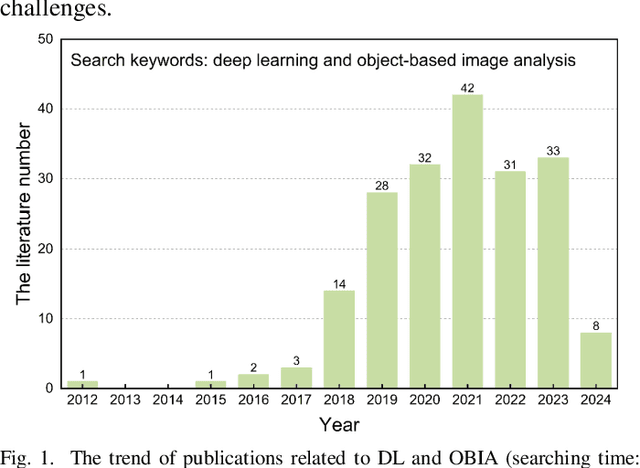
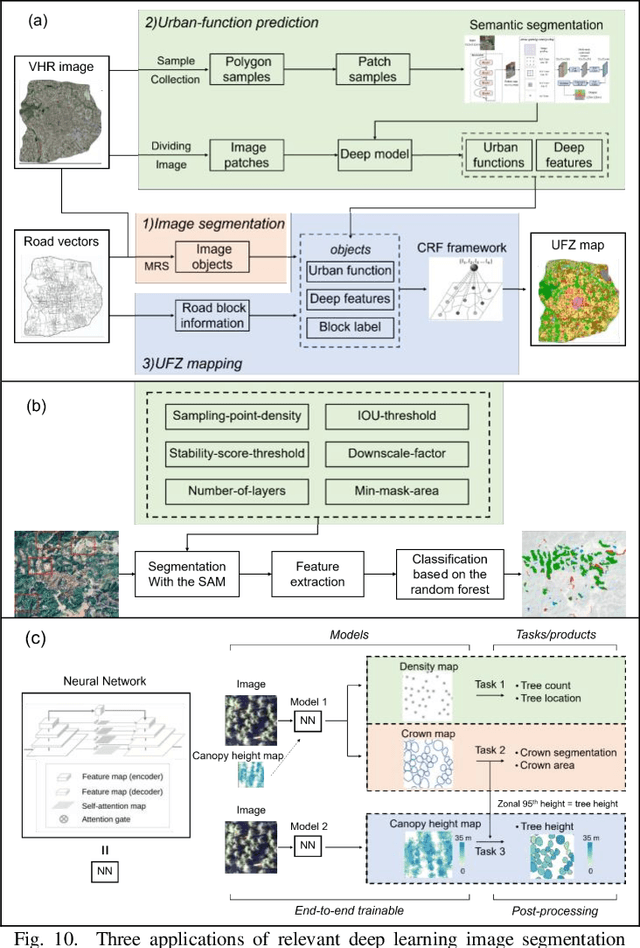
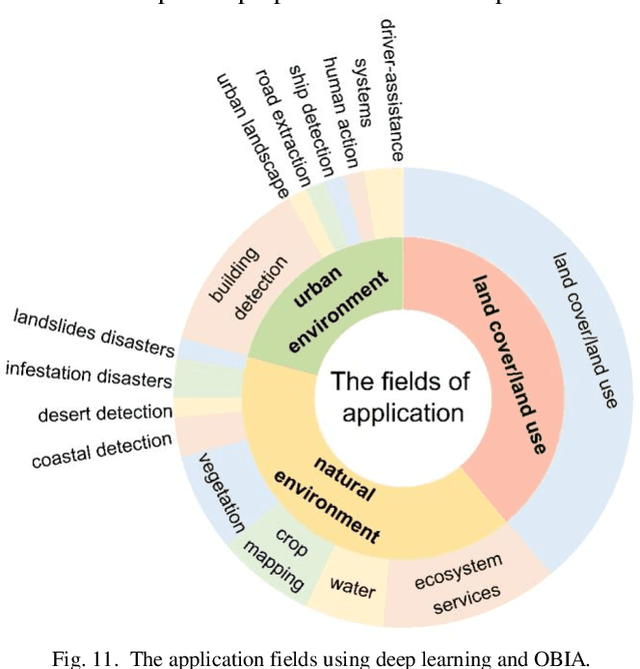

Deep learning has gained significant attention in remote sensing, especially in pixel- or patch-level applications. Despite initial attempts to integrate deep learning into object-based image analysis (OBIA), its full potential remains largely unexplored. In this article, as OBIA usage becomes more widespread, we conducted a comprehensive review and expansion of its task subdomains, with or without the integration of deep learning. Furthermore, we have identified and summarized five prevailing strategies to address the challenge of deep learning's limitations in directly processing unstructured object data within OBIA, and this review also recommends some important future research directions. Our goal with these endeavors is to inspire more exploration in this fascinating yet overlooked area and facilitate the integration of deep learning into OBIA processing workflows.
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
Jul 09, 2024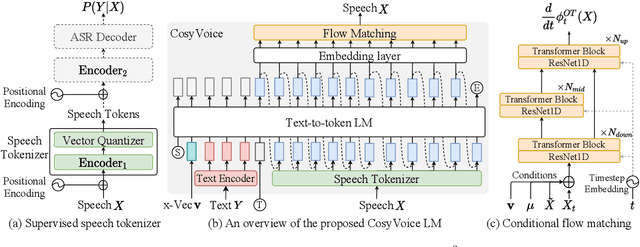

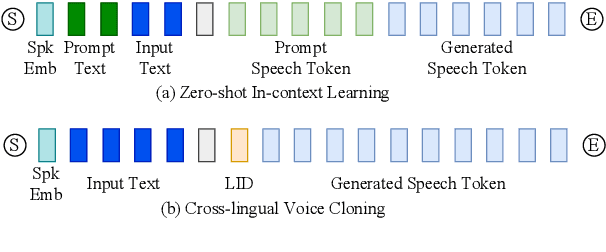
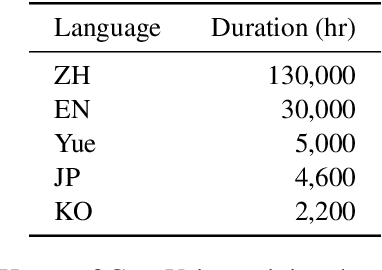
Recent years have witnessed a trend that large language model (LLM) based text-to-speech (TTS) emerges into the mainstream due to their high naturalness and zero-shot capacity. In this paradigm, speech signals are discretized into token sequences, which are modeled by an LLM with text as prompts and reconstructed by a token-based vocoder to waveforms. Obviously, speech tokens play a critical role in LLM-based TTS models. Current speech tokens are learned in an unsupervised manner, which lacks explicit semantic information and alignment to the text. In this paper, we propose to represent speech with supervised semantic tokens, which are derived from a multilingual speech recognition model by inserting vector quantization into the encoder. Based on the tokens, we further propose a scalable zero-shot TTS synthesizer, CosyVoice, which consists of an LLM for text-to-token generation and a conditional flow matching model for token-to-speech synthesis. Experimental results show that supervised semantic tokens significantly outperform existing unsupervised tokens in terms of content consistency and speaker similarity for zero-shot voice cloning. Moreover, we find that utilizing large-scale data further improves the synthesis performance, indicating the scalable capacity of CosyVoice. To the best of our knowledge, this is the first attempt to involve supervised speech tokens into TTS models.
The Impact of Quantization and Pruning on Deep Reinforcement Learning Models
Jul 05, 2024



Deep reinforcement learning (DRL) has achieved remarkable success across various domains, such as video games, robotics, and, recently, large language models. However, the computational costs and memory requirements of DRL models often limit their deployment in resource-constrained environments. The challenge underscores the urgent need to explore neural network compression methods to make RDL models more practical and broadly applicable. Our study investigates the impact of two prominent compression methods, quantization and pruning on DRL models. We examine how these techniques influence four performance factors: average return, memory, inference time, and battery utilization across various DRL algorithms and environments. Despite the decrease in model size, we identify that these compression techniques generally do not improve the energy efficiency of DRL models, but the model size decreases. We provide insights into the trade-offs between model compression and DRL performance, offering guidelines for deploying efficient DRL models in resource-constrained settings.
GMP-ATL: Gender-augmented Multi-scale Pseudo-label Enhanced Adaptive Transfer Learning for Speech Emotion Recognition via HuBERT
May 03, 2024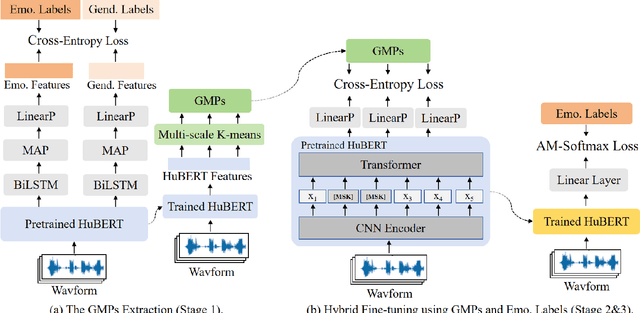
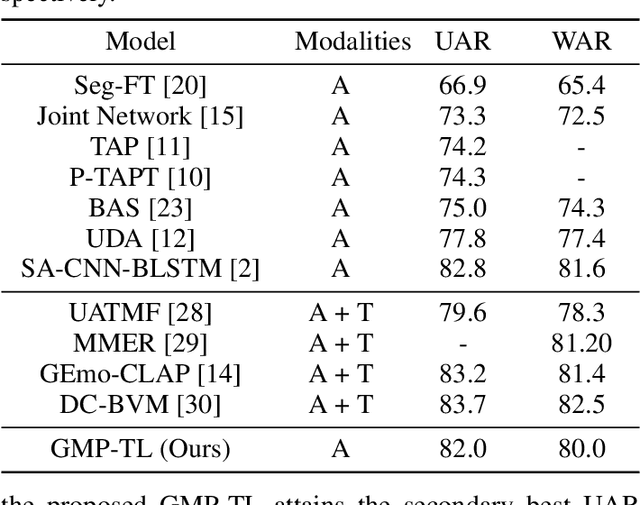
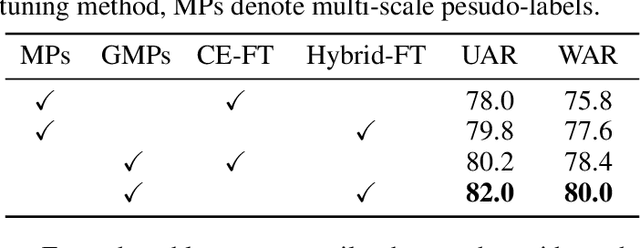
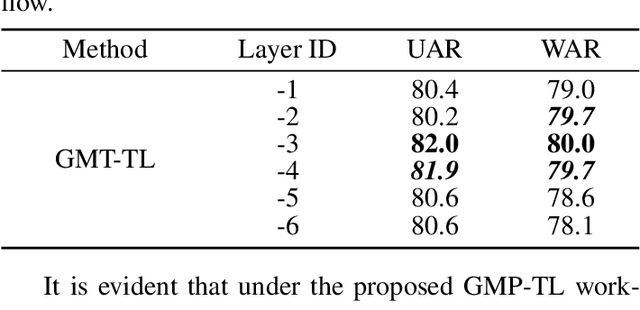
The continuous evolution of pre-trained speech models has greatly advanced Speech Emotion Recognition (SER). However, there is still potential for enhancement in the performance of these methods. In this paper, we present GMP-ATL (Gender-augmented Multi-scale Pseudo-label Adaptive Transfer Learning), a novel HuBERT-based adaptive transfer learning framework for SER. Specifically, GMP-ATL initially employs the pre-trained HuBERT, implementing multi-task learning and multi-scale k-means clustering to acquire frame-level gender-augmented multi-scale pseudo-labels. Then, to fully leverage both obtained frame-level and utterance-level emotion labels, we incorporate model retraining and fine-tuning methods to further optimize GMP-ATL. Experiments on IEMOCAP show that our GMP-ATL achieves superior recognition performance, with a WAR of 80.0\% and a UAR of 82.0\%, surpassing state-of-the-art unimodal SER methods, while also yielding comparable results with multimodal SER approaches.