 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-Mimi: A Transformer-based Mimi Decoder for Real-Time On-Phone TTS
Jan 27, 2026Neural audio codecs provide promising acoustic features for speech synthesis, with representative streaming codecs like Mimi providing high-quality acoustic features for real-time Text-to-Speech (TTS) applications. However, Mimi's decoder, which employs a hybrid transformer and convolution architecture, introduces significant latency bottlenecks on edge devices due to the the compute intensive nature of deconvolution layers which are not friendly for mobile-CPUs, such as the most representative framework XNNPACK. This paper introduces T-Mimi, a novel modification of the Mimi codec decoder that replaces its convolutional components with a purely transformer-based decoder, inspired by the TS3-Codec architecture. This change dramatically reduces on-device TTS latency from 42.1ms to just 4.4ms. Furthermore, we conduct quantization aware training and derive a crucial finding: the final two transformer layers and the concluding linear layers of the decoder, which are close to the waveform, are highly sensitive to quantization and must be preserved at full precision to maintain audio quality.
Do Neural Codecs Generalize? A Controlled Study Across Unseen Languages and Non-Speech Tasks
Jan 18, 2026This paper investigates three crucial yet underexplored aspects of the generalization capabilities of neural audio codecs (NACs): (i) whether NACs can generalize to unseen languages during pre-training, (ii) whether speech-only pre-trained NACs can effectively generalize to non-speech applications such as environmental sounds, music, and animal vocalizations, and (iii) whether incorporating non-speech data during pre-training can improve performance on both speech and non-speech tasks. Existing studies typically rely on off-the-shelf NACs for comparison, which limits insight due to variations in implementation. In this work, we train NACs from scratch using strictly controlled configurations and carefully curated pre-training data to enable fair comparisons. We conduct a comprehensive evaluation of NAC performance on both signal reconstruction quality and downstream applications using 11 metrics. Our results show that NACs can generalize to unseen languages during pre-training, speech-only pre-trained NACs exhibit degraded performance on non-speech tasks, and incorporating non-speech data during pre-training improves performance on non-speech tasks while maintaining comparable performance on speech tasks.
How Does Instrumental Music Help SingFake Detection?
Sep 18, 2025Although many models exist to detect singing voice deepfakes (SingFake), how these models operate, particularly with instrumental accompaniment, is unclear. We investigate how instrumental music affects SingFake detection from two perspectives. To investigate the behavioral effect, we test different backbones, unpaired instrumental tracks, and frequency subbands. To analyze the representational effect, we probe how fine-tuning alters encoders' speech and music capabilities. Our results show that instrumental accompaniment acts mainly as data augmentation rather than providing intrinsic cues (e.g., rhythm or harmony). Furthermore, fine-tuning increases reliance on shallow speaker features while reducing sensitivity to content, paralinguistic, and semantic information. These insights clarify how models exploit vocal versus instrumental cues and can inform the design of more interpretable and robust SingFake detection systems.
Discrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
Towards Generalized Source Tracing for Codec-Based Deepfake Speech
Jun 08, 2025Recent attempts at source tracing for codec-based deepfake speech (CodecFake), generated by neural audio codec-based speech generation (CoSG) models, have exhibited suboptimal performance. However, how to train source tracing models using simulated CoSG data while maintaining strong performance on real CoSG-generated audio remains an open challenge. In this paper, we show that models trained solely on codec-resynthesized data tend to overfit to non-speech regions and struggle to generalize to unseen content. To mitigate these challenges, we introduce the Semantic-Acoustic Source Tracing Network (SASTNet), which jointly leverages Whisper for semantic feature encoding and Wav2vec2 with AudioMAE for acoustic feature encoding. Our proposed SASTNet achieves state-of-the-art performance on the CoSG test set of the CodecFake+ dataset, demonstrating its effectiveness for reliable source tracing.
Towards Efficient Speech-Text Jointly Decoding within One Speech Language Model
Jun 04, 2025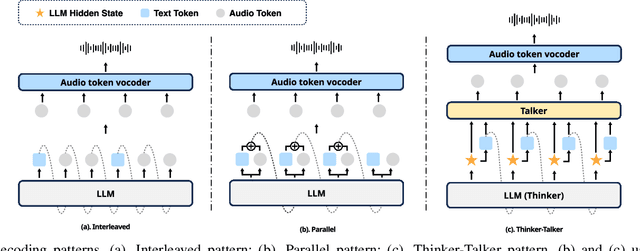
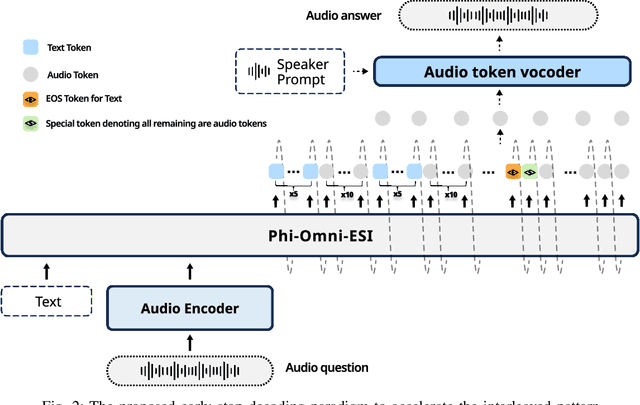


Speech language models (Speech LMs) enable end-to-end speech-text modelling within a single model, offering a promising direction for spoken dialogue systems. The choice of speech-text jointly decoding paradigm plays a critical role in performance, efficiency, and alignment quality. In this work, we systematically compare representative joint speech-text decoding strategies-including the interleaved, and parallel generation paradigms-under a controlled experimental setup using the same base language model, speech tokenizer and training data. Our results show that the interleaved approach achieves the best alignment. However it suffers from slow inference due to long token sequence length. To address this, we propose a novel early-stop interleaved (ESI) pattern that not only significantly accelerates decoding but also yields slightly better performance. Additionally, we curate high-quality question answering (QA) datasets to further improve speech QA performance.
Phi-Omni-ST: A multimodal language model for direct speech-to-speech translation
Jun 04, 2025Speech-aware language models (LMs) have demonstrated capabilities in understanding spoken language while generating text-based responses. However, enabling them to produce speech output efficiently and effectively remains a challenge. In this paper, we present Phi-Omni-ST, a multimodal LM for direct speech-to-speech translation (ST), built on the open-source Phi-4 MM model. Phi-Omni-ST extends its predecessor by generating translated speech using an audio transformer head that predicts audio tokens with a delay relative to text tokens, followed by a streaming vocoder for waveform synthesis. Our experimental results on the CVSS-C dataset demonstrate Phi-Omni-ST's superior performance, significantly surpassing existing baseline models trained on the same dataset. Furthermore, when we scale up the training data and the model size, Phi-Omni-ST reaches on-par performance with the current SOTA model.
Codec-Based Deepfake Source Tracing via Neural Audio Codec Taxonomy
May 19, 2025



Recent advances in neural audio codec-based speech generation (CoSG) models have produced remarkably realistic audio deepfakes. We refer to deepfake speech generated by CoSG systems as codec-based deepfake, or CodecFake. Although existing anti-spoofing research on CodecFake predominantly focuses on verifying the authenticity of audio samples, almost no attention was given to tracing the CoSG used in generating these deepfakes. In CodecFake generation, processes such as speech-to-unit encoding, discrete unit modeling, and unit-to-speech decoding are fundamentally based on neural audio codecs. Motivated by this, we introduce source tracing for CodecFake via neural audio codec taxonomy, which dissects neural audio codecs to trace CoSG. Our experimental results on the CodecFake+ dataset provide promising initial evidence for the feasibility of CodecFake source tracing while also highlighting several challenges that warrant further investigation.
Pseudo-Autoregressive Neural Codec Language Models for Efficient Zero-Shot Text-to-Speech Synthesis
Apr 14, 2025
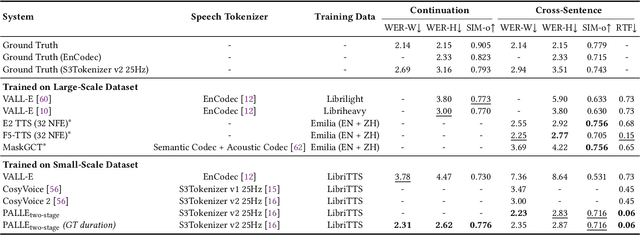

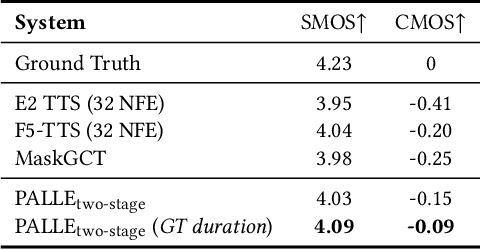
Recent zero-shot text-to-speech (TTS) systems face a common dilemma: autoregressive (AR) models suffer from slow generation and lack duration controllability, while non-autoregressive (NAR) models lack temporal modeling and typically require complex designs. In this paper, we introduce a novel pseudo-autoregressive (PAR) codec language modeling approach that unifies AR and NAR modeling. Combining explicit temporal modeling from AR with parallel generation from NAR, PAR generates dynamic-length spans at fixed time steps. Building on PAR, we propose PALLE, a two-stage TTS system that leverages PAR for initial generation followed by NAR refinement. In the first stage, PAR progressively generates speech tokens along the time dimension, with each step predicting all positions in parallel but only retaining the left-most span. In the second stage, low-confidence tokens are iteratively refined in parallel, leveraging the global contextual information. Experiments demonstrate that PALLE, trained on LibriTTS, outperforms state-of-the-art systems trained on large-scale data, including F5-TTS, E2-TTS, and MaskGCT, on the LibriSpeech test-clean set in terms of speech quality, speaker similarity, and intelligibility, while achieving up to ten times faster inference speed. Audio samples are available at https://anonymous-palle.github.io.
On The Landscape of Spoken Language Models: A Comprehensive Survey
Apr 11, 2025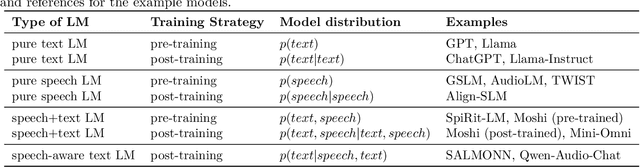
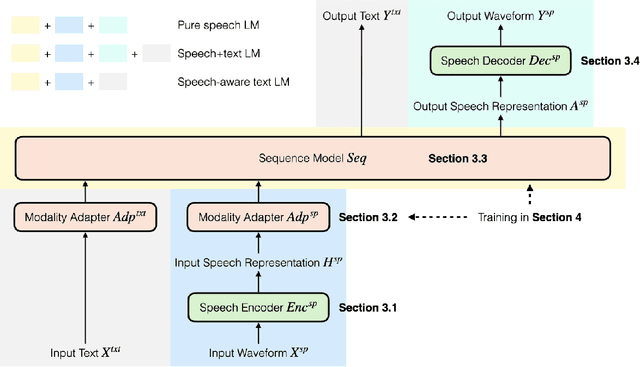
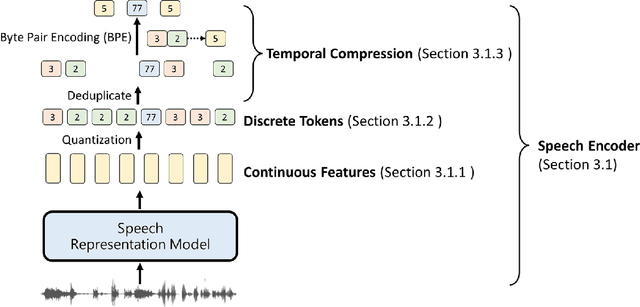
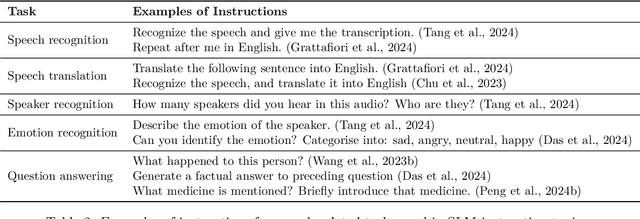
The field of spoken language processing is undergoing a shift from training custom-built, task-specific models toward using and optimizing spoken language models (SLMs) which act as universal speech processing systems. This trend is similar to the progression toward universal language models that has taken place in the field of (text) natural language processing. SLMs include both "pure" language models of speech -- models of the distribution of tokenized speech sequences -- and models that combine speech encoders with text language models, often including both spoken and written input or output. Work in this area is very diverse, with a range of terminology and evaluation settings. This paper aims to contribute an improved understanding of SLMs via a unifying literature survey of recent work in the context of the evolution of the field. Our survey categorizes the work in this area by model architecture, training, and evaluation choices, and describes some key challenges and directions for future work.