 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoshiRAG: Asynchronous Knowledge Retrieval for Full-Duplex Speech Language Models
Apr 14, 2026Speech-to-speech language models have recently emerged to enhance the naturalness of conversational AI. In particular, full-duplex models are distinguished by their real-time interactivity, including handling of pauses, interruptions, and backchannels. However, improving their factuality remains an open challenge. While scaling the model size could address this gap, it would make real-time inference prohibitively expensive. In this work, we propose MoshiRAG, a modular approach that combines a compact full-duplex interface with selective retrieval to access more powerful knowledge sources. Our asynchronous framework enables the model to identify knowledge-demanding queries and ground its responses in external information. By leveraging the natural temporal gap between response onset and the delivery of core information, the retrieval process can be completed while maintaining a natural conversation flow. With this approach, MoshiRAG achieves factuality comparable to the best publicly released non-duplex speech language models while preserving the interactivity inherent to full-duplex systems. Moreover, our flexible design supports plug-and-play retrieval methods without retraining and demonstrates strong performance on out-of-domain mathematical reasoning tasks.
On The Landscape of Spoken Language Models: A Comprehensive Survey
Apr 11, 2025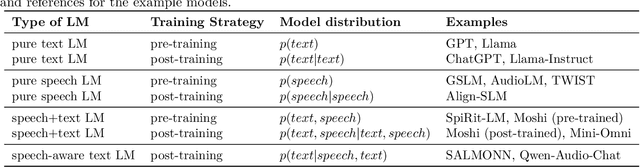
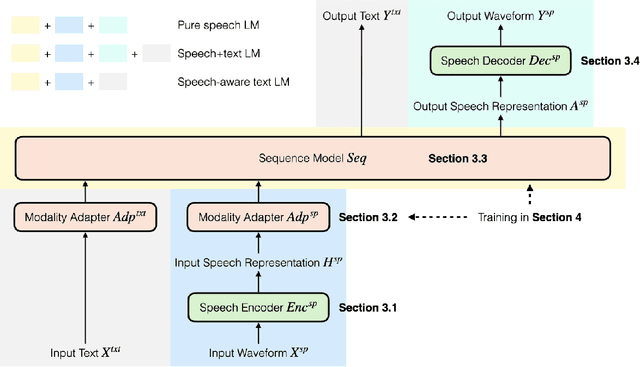
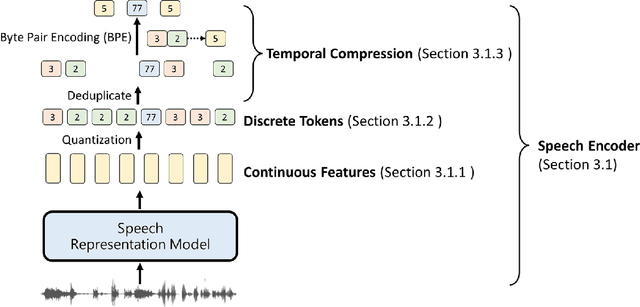
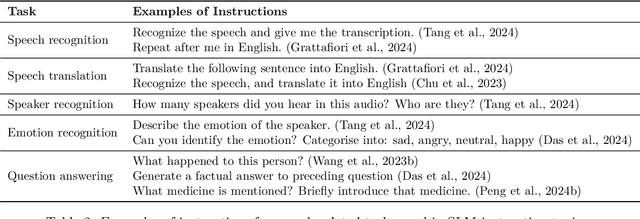
The field of spoken language processing is undergoing a shift from training custom-built, task-specific models toward using and optimizing spoken language models (SLMs) which act as universal speech processing systems. This trend is similar to the progression toward universal language models that has taken place in the field of (text) natural language processing. SLMs include both "pure" language models of speech -- models of the distribution of tokenized speech sequences -- and models that combine speech encoders with text language models, often including both spoken and written input or output. Work in this area is very diverse, with a range of terminology and evaluation settings. This paper aims to contribute an improved understanding of SLMs via a unifying literature survey of recent work in the context of the evolution of the field. Our survey categorizes the work in this area by model architecture, training, and evaluation choices, and describes some key challenges and directions for future work.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
On the Evaluation of Speech Foundation Models for Spoken Language Understanding
Jun 14, 2024The Spoken Language Understanding Evaluation (SLUE) suite of benchmark tasks was recently introduced to address the need for open resources and benchmarking of complex spoken language understanding (SLU) tasks, including both classification and sequence generation tasks, on natural speech. The benchmark has demonstrated preliminary success in using pre-trained speech foundation models (SFM) for these SLU tasks. However, the community still lacks a fine-grained understanding of the comparative utility of different SFMs. Inspired by this, we ask: which SFMs offer the most benefits for these complex SLU tasks, and what is the most effective approach for incorporating these SFMs? To answer this, we perform an extensive evaluation of multiple supervised and self-supervised SFMs using several evaluation protocols: (i) frozen SFMs with a lightweight prediction head, (ii) frozen SFMs with a complex prediction head, and (iii) fine-tuned SFMs with a lightweight prediction head. Although the supervised SFMs are pre-trained on much more speech recognition data (with labels), they do not always outperform self-supervised SFMs; the latter tend to perform at least as well as, and sometimes better than, supervised SFMs, especially on the sequence generation tasks in SLUE. While there is no universally optimal way of incorporating SFMs, the complex prediction head gives the best performance for most tasks, although it increases the inference time. We also introduce an open-source toolkit and performance leaderboard, SLUE-PERB, for these tasks and modeling strategies.
Learning Fine-Grained Controllability on Speech Generation via Efficient Fine-Tuning
Jun 10, 2024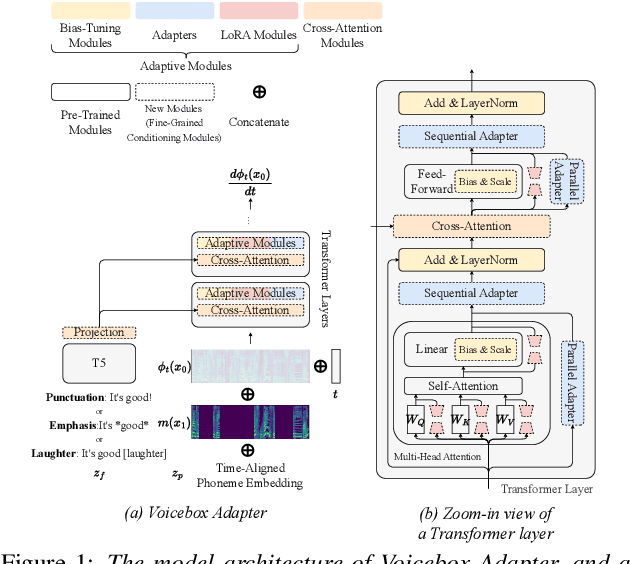
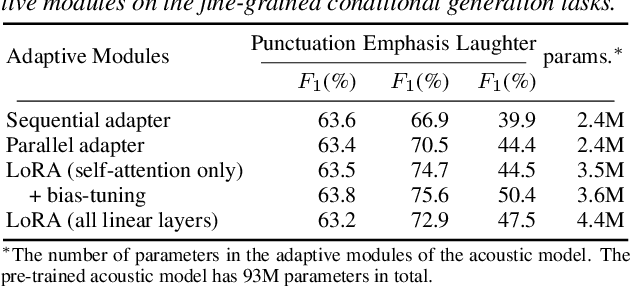
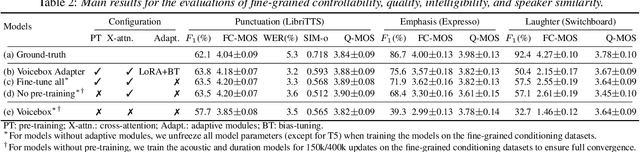
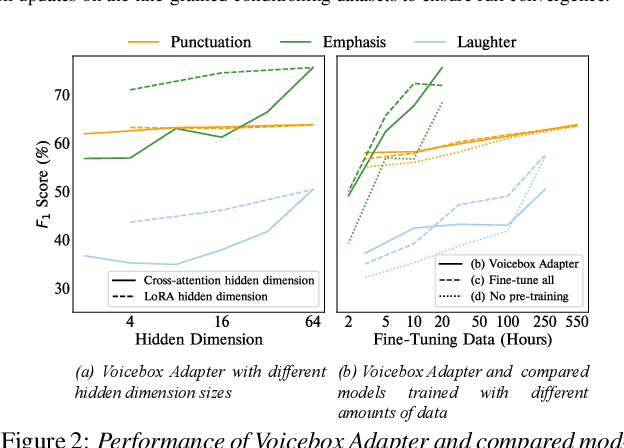
As the scale of generative models continues to grow, efficient reuse and adaptation of pre-trained models have become crucial considerations. In this work, we propose Voicebox Adapter, a novel approach that integrates fine-grained conditions into a pre-trained Voicebox speech generation model using a cross-attention module. To ensure a smooth integration of newly added modules with pre-trained ones, we explore various efficient fine-tuning approaches. Our experiment shows that the LoRA with bias-tuning configuration yields the best performance, enhancing controllability without compromising speech quality. Across three fine-grained conditional generation tasks, we demonstrate the effectiveness and resource efficiency of Voicebox Adapter. Follow-up experiments further highlight the robustness of Voicebox Adapter across diverse data setups.
Toward Joint Language Modeling for Speech Units and Text
Oct 12, 2023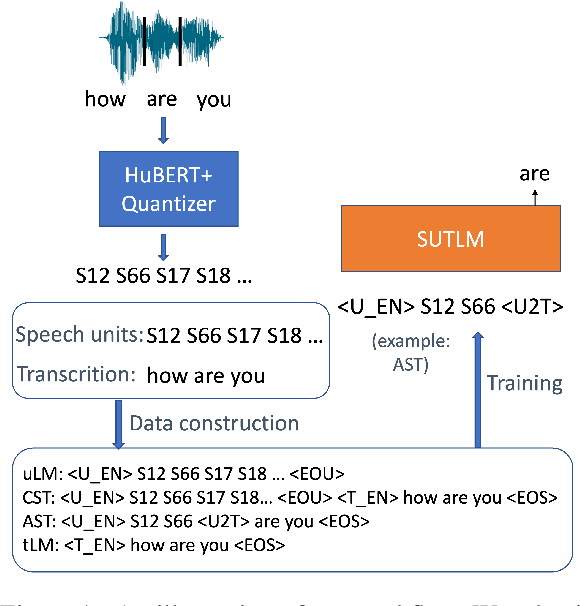

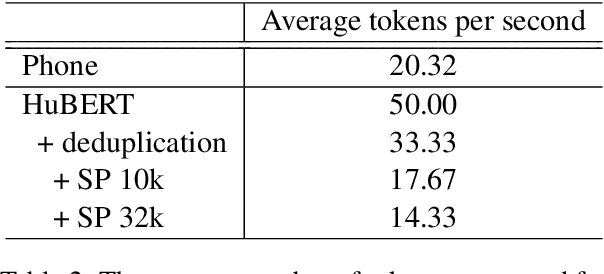
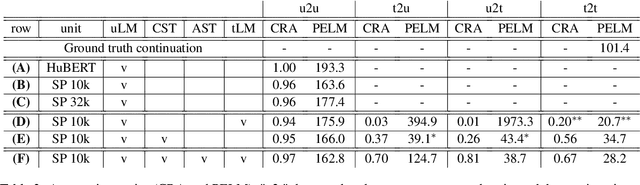
Speech and text are two major forms of human language. The research community has been focusing on mapping speech to text or vice versa for many years. However, in the field of language modeling, very little effort has been made to model them jointly. In light of this, we explore joint language modeling for speech units and text. Specifically, we compare different speech tokenizers to transform continuous speech signals into discrete units and use different methods to construct mixed speech-text data. We introduce automatic metrics to evaluate how well the joint LM mixes speech and text. We also fine-tune the LM on downstream spoken language understanding (SLU) tasks with different modalities (speech or text) and test its performance to assess the model's learning of shared representations. Our results show that by mixing speech units and text with our proposed mixing techniques, the joint LM improves over a speech-only baseline on SLU tasks and shows zero-shot cross-modal transferability.
Few-Shot Spoken Language Understanding via Joint Speech-Text Models
Oct 09, 2023Recent work on speech representation models jointly pre-trained with text has demonstrated the potential of improving speech representations by encoding speech and text in a shared space. In this paper, we leverage such shared representations to address the persistent challenge of limited data availability in spoken language understanding tasks. By employing a pre-trained speech-text model, we find that models fine-tuned on text can be effectively transferred to speech testing data. With as little as 1 hour of labeled speech data, our proposed approach achieves comparable performance on spoken language understanding tasks (specifically, sentiment analysis and named entity recognition) when compared to previous methods using speech-only pre-trained models fine-tuned on 10 times more data. Beyond the proof-of-concept study, we also analyze the latent representations. We find that the bottom layers of speech-text models are largely task-agnostic and align speech and text representations into a shared space, while the top layers are more task-specific.
AV2Wav: Diffusion-Based Re-synthesis from Continuous Self-supervised Features for Audio-Visual Speech Enhancement
Sep 14, 2023Speech enhancement systems are typically trained using pairs of clean and noisy speech. In audio-visual speech enhancement (AVSE), there is not as much ground-truth clean data available; most audio-visual datasets are collected in real-world environments with background noise and reverberation, hampering the development of AVSE. In this work, we introduce AV2Wav, a resynthesis-based audio-visual speech enhancement approach that can generate clean speech despite the challenges of real-world training data. We obtain a subset of nearly clean speech from an audio-visual corpus using a neural quality estimator, and then train a diffusion model on this subset to generate waveforms conditioned on continuous speech representations from AV-HuBERT with noise-robust training. We use continuous rather than discrete representations to retain prosody and speaker information. With this vocoding task alone, the model can perform speech enhancement better than a masking-based baseline. We further fine-tune the diffusion model on clean/noisy utterance pairs to improve the performance. Our approach outperforms a masking-based baseline in terms of both automatic metrics and a human listening test and is close in quality to the target speech in the listening test. Audio samples can be found at https://home.ttic.edu/~jcchou/demo/avse/avse_demo.html.
What do self-supervised speech models know about words?
Jun 30, 2023Many self-supervised speech models (S3Ms) have been introduced over the last few years, producing performance and data efficiency improvements for a variety of speech tasks. Evidence is emerging that different S3Ms encode linguistic information in different layers, and also that some S3Ms appear to learn phone-like sub-word units. However, the extent to which these models capture larger linguistic units, such as words, and where word-related information is encoded, remains unclear. In this study, we conduct several analyses of word segment representations extracted from different layers of three S3Ms: wav2vec2, HuBERT, and WavLM. We employ canonical correlation analysis (CCA), a lightweight analysis tool, to measure the similarity between these representations and word-level linguistic properties. We find that the maximal word-level linguistic content tends to be found in intermediate model layers, while some lower-level information like pronunciation is also retained in higher layers of HuBERT and WavLM. Syntactic and semantic word attributes have similar layer-wise behavior. We also find that, for all of the models tested, word identity information is concentrated near the center of each word segment. We then test the layer-wise performance of the same models, when used directly with no additional learned parameters, on several tasks: acoustic word discrimination, word segmentation, and semantic sentence similarity. We find similar layer-wise trends in performance, and furthermore, find that when using the best-performing layer of HuBERT or WavLM, it is possible to achieve performance on word segmentation and sentence similarity that rivals more complex existing approaches.
Voice Filter: Few-shot text-to-speech speaker adaptation using voice conversion as a post-processing module
Feb 16, 2022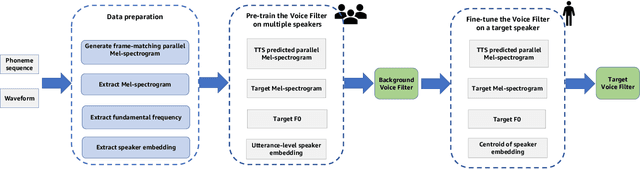

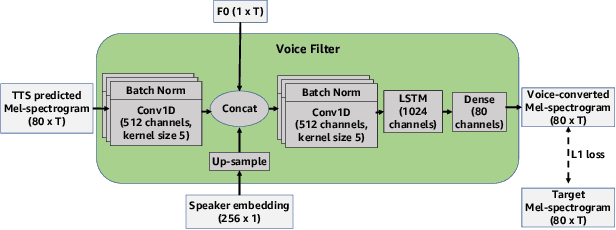

State-of-the-art text-to-speech (TTS) systems require several hours of recorded speech data to generate high-quality synthetic speech. When using reduced amounts of training data, standard TTS models suffer from speech quality and intelligibility degradations, making training low-resource TTS systems problematic. In this paper, we propose a novel extremely low-resource TTS method called Voice Filter that uses as little as one minute of speech from a target speaker. It uses voice conversion (VC) as a post-processing module appended to a pre-existing high-quality TTS system and marks a conceptual shift in the existing TTS paradigm, framing the few-shot TTS problem as a VC task. Furthermore, we propose to use a duration-controllable TTS system to create a parallel speech corpus to facilitate the VC task. Results show that the Voice Filter outperforms state-of-the-art few-shot speech synthesis techniques in terms of objective and subjective metrics on one minute of speech on a diverse set of voices, while being competitive against a TTS model built on 30 times more data.