 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 31, 2021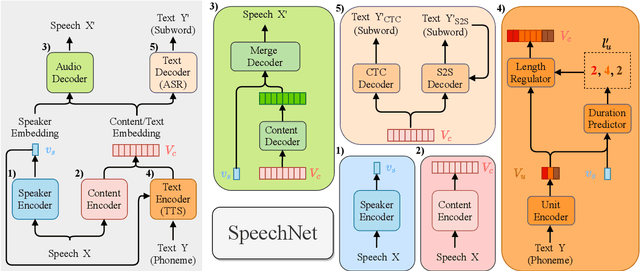
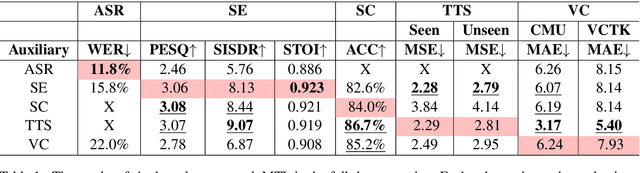
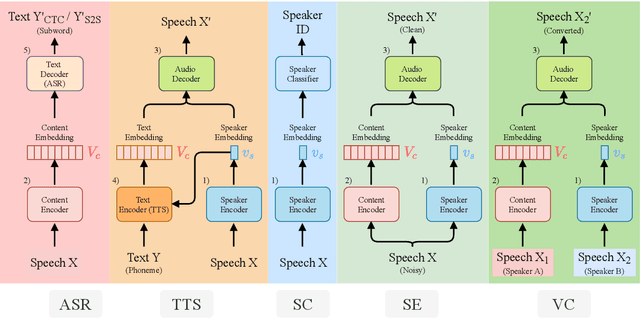
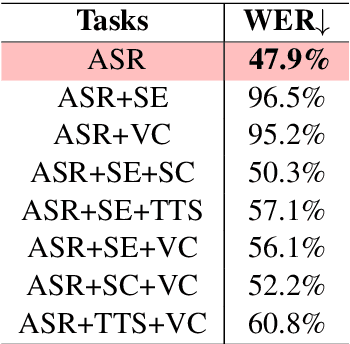
There is a wide variety of speech processing tasks ranging from extracting content information from speech signals to generating speech signals. For different tasks, model networks are usually designed and tuned separately. If a universal model can perform multiple speech processing tasks, some tasks might be improved with the related abilities learned from other tasks. The multi-task learning of a wide variety of speech processing tasks with a universal model has not been studied. This paper proposes a universal modularized model, SpeechNet, which treats all speech processing tasks into a speech/text input and speech/text output format. We select five essential speech processing tasks for multi-task learning experiments with SpeechNet. We show that SpeechNet learns all of the above tasks, and we further analyze which tasks can be improved by other tasks. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We release the code and experimental settings to facilitate the research of modularized universal models and multi-task learning of speech processing tasks.
S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations
Apr 07, 2021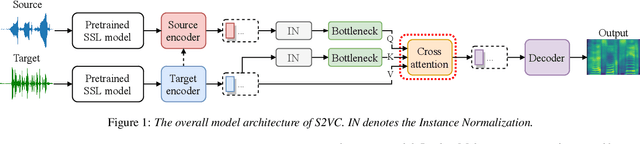
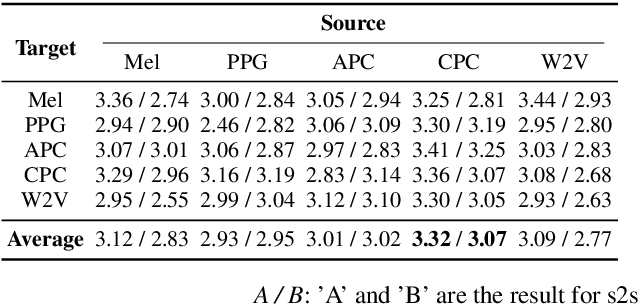
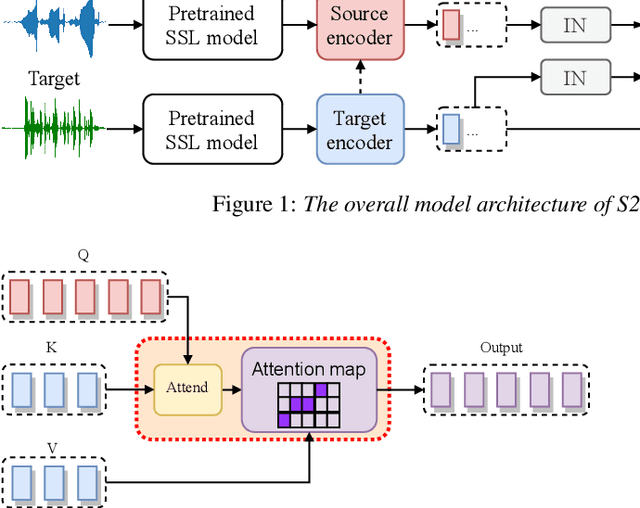

Any-to-any voice conversion (VC) aims to convert the timbre of utterances from and to any speakers seen or unseen during training. Various any-to-any VC approaches have been proposed like AUTOVC, AdaINVC, and FragmentVC. AUTOVC, and AdaINVC utilize source and target encoders to disentangle the content and speaker information of the features. FragmentVC utilizes two encoders to encode source and target information and adopts cross attention to align the source and target features with similar phonetic content. Moreover, pre-trained features are adopted. AUTOVC used dvector to extract speaker information, and self-supervised learning (SSL) features like wav2vec 2.0 is used in FragmentVC to extract the phonetic content information. Different from previous works, we proposed S2VC that utilizes Self-Supervised features as both source and target features for VC model. Supervised phoneme posteriororgram (PPG), which is believed to be speaker-independent and widely used in VC to extract content information, is chosen as a strong baseline for SSL features. The objective evaluation and subjective evaluation both show models taking SSL feature CPC as both source and target features outperforms that taking PPG as source feature, suggesting that SSL features have great potential in improving VC.