 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeave No Knowledge Behind During Knowledge Distillation: Towards Practical and Effective Knowledge Distillation for Code-Switching ASR Using Realistic Data
Jul 15, 2024



Recent advances in automatic speech recognition (ASR) often rely on large speech foundation models for generating high-quality transcriptions. However, these models can be impractical due to limited computing resources. The situation is even more severe in terms of more realistic or difficult scenarios, such as code-switching ASR (CS-ASR). To address this, we present a framework for developing more efficient models for CS-ASR through knowledge distillation using realistic speech-only data. Our proposed method, Leave No Knowledge Behind During Knowledge Distillation (K$^2$D), leverages both the teacher model's knowledge and additional insights from a small auxiliary model. We evaluate our approach on two in-domain and two out-domain datasets, demonstrating that K$^2$D is effective. By conducting K$^2$D on the unlabeled realistic data, we have successfully obtained a 2-time smaller model with 5-time faster generation speed while outperforming the baseline methods and the teacher model on all the testing sets. We have made our model publicly available on Hugging Face (https://huggingface.co/andybi7676/k2d-whisper.zh-en).
Investigating the Effects of Large-Scale Pseudo-Stereo Data and Different Speech Foundation Model on Dialogue Generative Spoken Language Model
Jul 02, 2024


Recent efforts in Spoken Dialogue Modeling aim to synthesize spoken dialogue without the need for direct transcription, thereby preserving the wealth of non-textual information inherent in speech. However, this approach faces a challenge when speakers talk simultaneously, requiring stereo dialogue data with speakers recorded on separate channels, a notably scarce resource. To address this, we have developed an innovative pipeline capable of transforming single-channel dialogue data into pseudo-stereo data. This expanded our training dataset from a mere 2,000 to an impressive 17,600 hours, significantly enriching the diversity and quality of the training examples available. The inclusion of this pseudo-stereo data has proven to be effective in improving the performance of spoken dialogue language models. Additionally, we explored the use of discrete units of different speech foundation models for spoken dialogue generation.
Maximum Entropy Reinforcement Learning via Energy-Based Normalizing Flow
May 22, 2024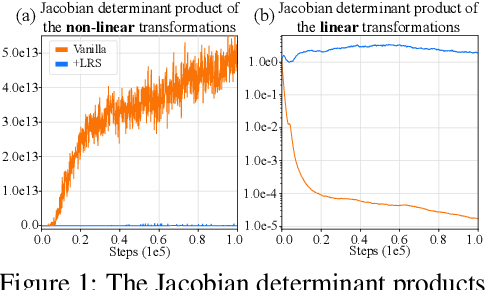
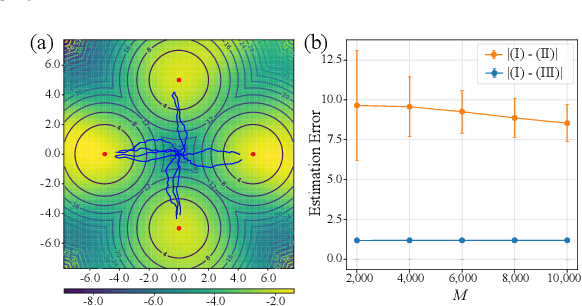
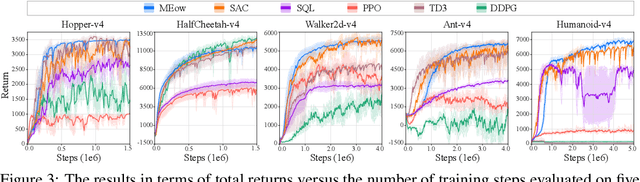
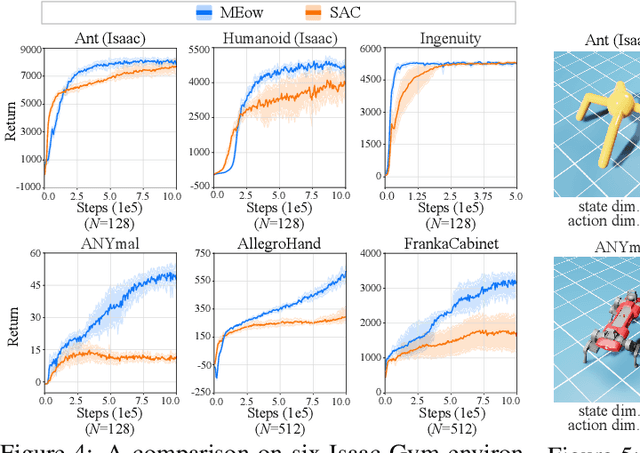
Existing Maximum-Entropy (MaxEnt) Reinforcement Learning (RL) methods for continuous action spaces are typically formulated based on actor-critic frameworks and optimized through alternating steps of policy evaluation and policy improvement. In the policy evaluation steps, the critic is updated to capture the soft Q-function. In the policy improvement steps, the actor is adjusted in accordance with the updated soft Q-function. In this paper, we introduce a new MaxEnt RL framework modeled using Energy-Based Normalizing Flows (EBFlow). This framework integrates the policy evaluation steps and the policy improvement steps, resulting in a single objective training process. Our method enables the calculation of the soft value function used in the policy evaluation target without Monte Carlo approximation. Moreover, this design supports the modeling of multi-modal action distributions while facilitating efficient action sampling. To evaluate the performance of our method, we conducted experiments on the MuJoCo benchmark suite and a number of high-dimensional robotic tasks simulated by Omniverse Isaac Gym. The evaluation results demonstrate that our method achieves superior performance compared to widely-adopted representative baselines.
A Unified Framework for Factorizing Distributional Value Functions for Multi-Agent Reinforcement Learning
Jun 04, 2023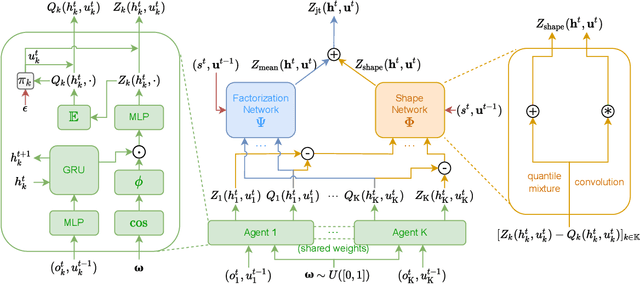

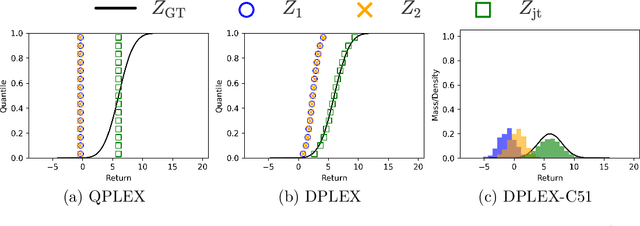
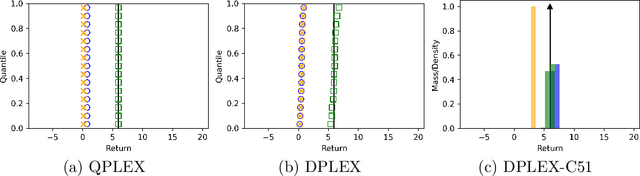
In fully cooperative multi-agent reinforcement learning (MARL) settings, environments are highly stochastic due to the partial observability of each agent and the continuously changing policies of other agents. To address the above issues, we proposed a unified framework, called DFAC, for integrating distributional RL with value function factorization methods. This framework generalizes expected value function factorization methods to enable the factorization of return distributions. To validate DFAC, we first demonstrate its ability to factorize the value functions of a simple matrix game with stochastic rewards. Then, we perform experiments on all Super Hard maps of the StarCraft Multi-Agent Challenge and six self-designed Ultra Hard maps, showing that DFAC is able to outperform a number of baselines.
Inductive Attention for Video Action Anticipation
Dec 17, 2022



Anticipating future actions based on video observations is an important task in video understanding, which would be useful for some precautionary systems that require response time to react before an event occurs. Since the input in action anticipation is only pre-action frames, models do not have enough information about the target action; moreover, similar pre-action frames may lead to different futures. Consequently, any solution using existing action recognition models can only be suboptimal. Recently, researchers have proposed using a longer video context to remedy the insufficient information in pre-action intervals, as well as the self-attention to query past relevant moments to address the anticipation problem. However, the indirect use of video input features as the query might be inefficient, as it only serves as the proxy to the anticipation goal. To this end, we propose an inductive attention model, which transparently uses prior prediction as the query to derive the anticipation result by induction from past experience. Our method naturally considers the uncertainty of multiple futures via the many-to-many association. On the large-scale egocentric video datasets, our model not only shows consistently better performance than state of the art using the same backbone, and is competitive to the methods that employ a stronger backbone, but also superior efficiency in less model parameters.
NVIDIA-UNIBZ Submission for EPIC-KITCHENS-100 Action Anticipation Challenge 2022
Jun 22, 2022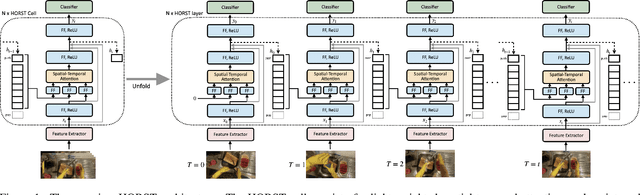
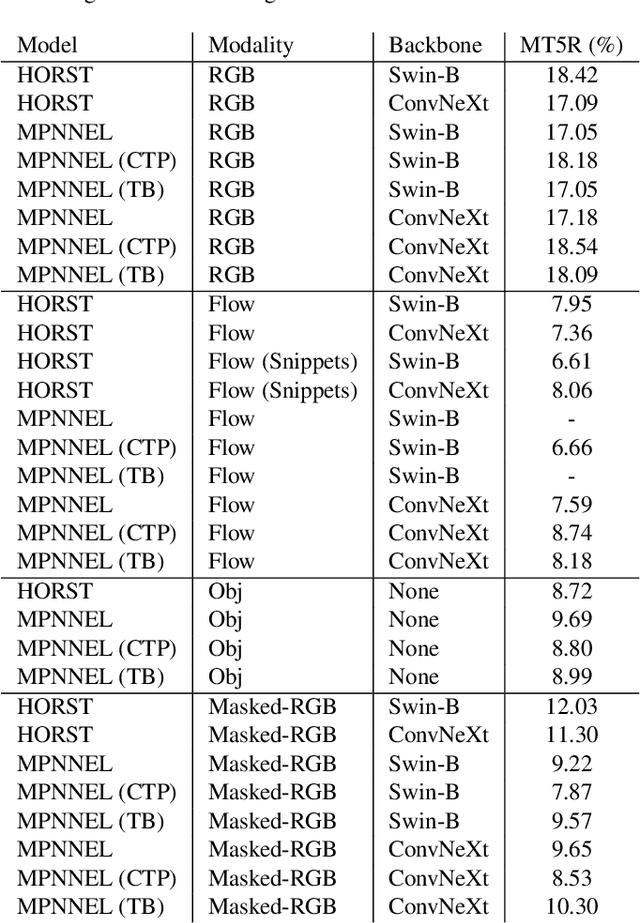

In this report, we describe the technical details of our submission for the EPIC-Kitchen-100 action anticipation challenge. Our modelings, the higher-order recurrent space-time transformer and the message-passing neural network with edge learning, are both recurrent-based architectures which observe only 2.5 seconds inference context to form the action anticipation prediction. By averaging the prediction scores from a set of models compiled with our proposed training pipeline, we achieved strong performance on the test set, which is 19.61% overall mean top-5 recall, recorded as second place on the public leaderboard.
Unified Recurrence Modeling for Video Action Anticipation
Jun 02, 2022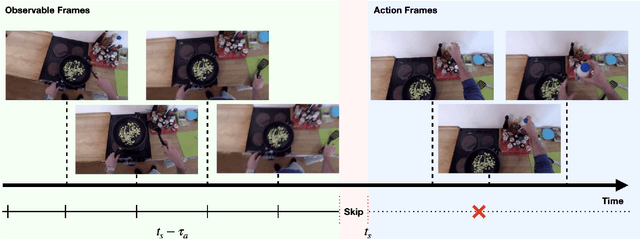
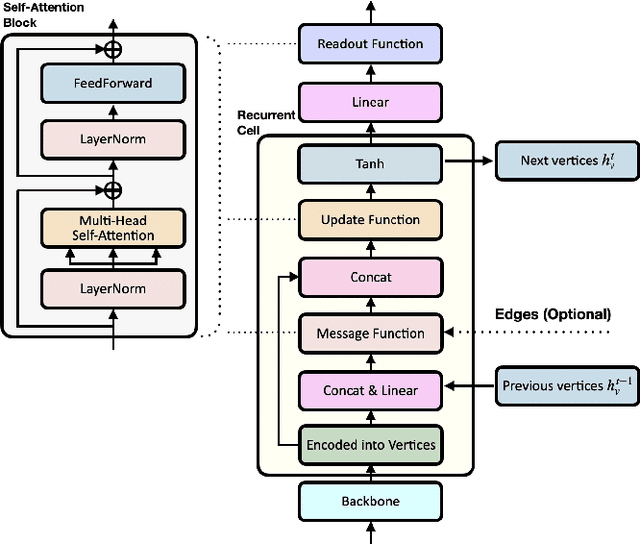


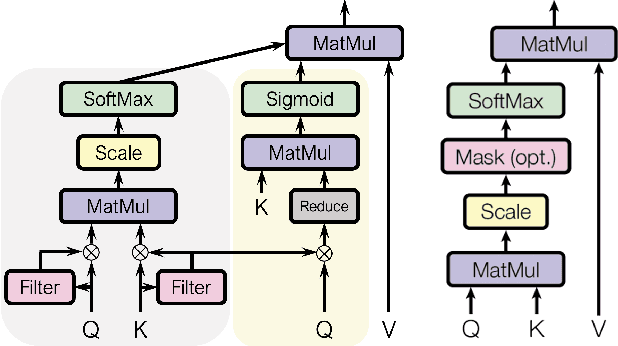
Forecasting future events based on evidence of current conditions is an innate skill of human beings, and key for predicting the outcome of any decision making. In artificial vision for example, we would like to predict the next human action before it happens, without observing the future video frames associated to it. Computer vision models for action anticipation are expected to collect the subtle evidence in the preamble of the target actions. In prior studies recurrence modeling often leads to better performance, the strong temporal inference is assumed to be a key element for reasonable prediction. To this end, we propose a unified recurrence modeling for video action anticipation via message passing framework. The information flow in space-time can be described by the interaction between vertices and edges, and the changes of vertices for each incoming frame reflects the underlying dynamics. Our model leverages self-attention as the building blocks for each of the message passing functions. In addition, we introduce different edge learning strategies that can be end-to-end optimized to gain better flexibility for the connectivity between vertices. Our experimental results demonstrate that our proposed method outperforms previous works on the large-scale EPIC-Kitchen dataset.
Speech Representation Learning Through Self-supervised Pretraining And Multi-task Finetuning
Oct 18, 2021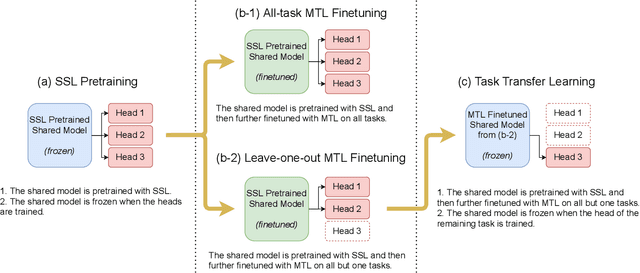
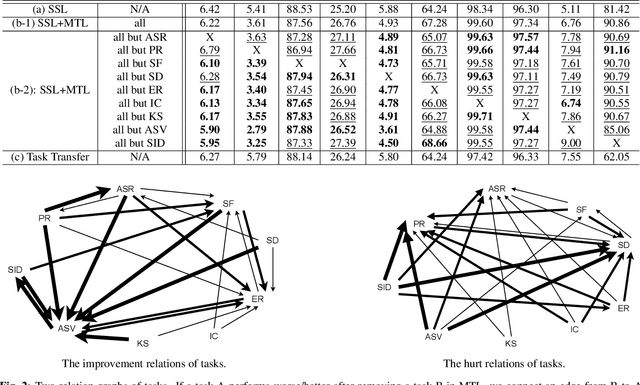
Speech representation learning plays a vital role in speech processing. Among them, self-supervised learning (SSL) has become an important research direction. It has been shown that an SSL pretraining model can achieve excellent performance in various downstream tasks of speech processing. On the other hand, supervised multi-task learning (MTL) is another representation learning paradigm, which has been proven effective in computer vision (CV) and natural language processing (NLP). However, there is no systematic research on the general representation learning model trained by supervised MTL in speech processing. In this paper, we show that MTL finetuning can further improve SSL pretraining. We analyze the generalizability of supervised MTL finetuning to examine if the speech representation learned by MTL finetuning can generalize to unseen new tasks.
SpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 31, 2021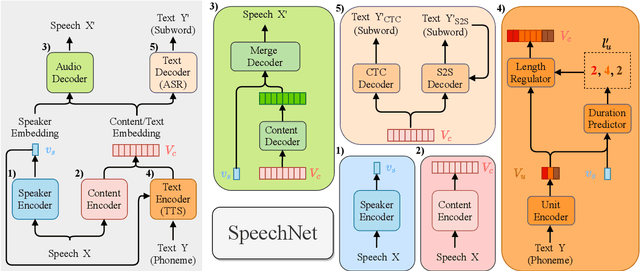
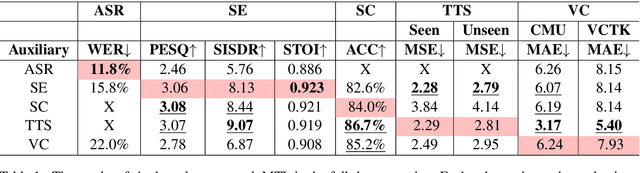
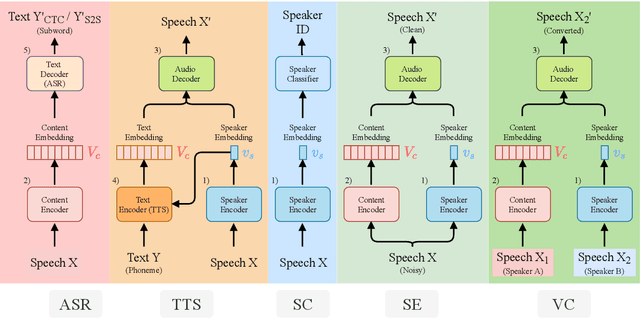
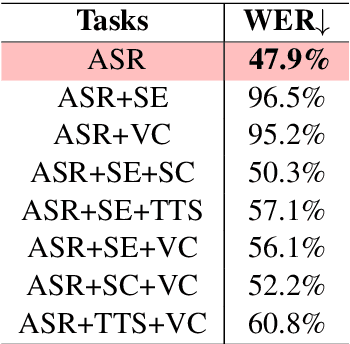
There is a wide variety of speech processing tasks ranging from extracting content information from speech signals to generating speech signals. For different tasks, model networks are usually designed and tuned separately. If a universal model can perform multiple speech processing tasks, some tasks might be improved with the related abilities learned from other tasks. The multi-task learning of a wide variety of speech processing tasks with a universal model has not been studied. This paper proposes a universal modularized model, SpeechNet, which treats all speech processing tasks into a speech/text input and speech/text output format. We select five essential speech processing tasks for multi-task learning experiments with SpeechNet. We show that SpeechNet learns all of the above tasks, and we further analyze which tasks can be improved by other tasks. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We release the code and experimental settings to facilitate the research of modularized universal models and multi-task learning of speech processing tasks.
Higher Order Recurrent Space-Time Transformer
Apr 17, 2021
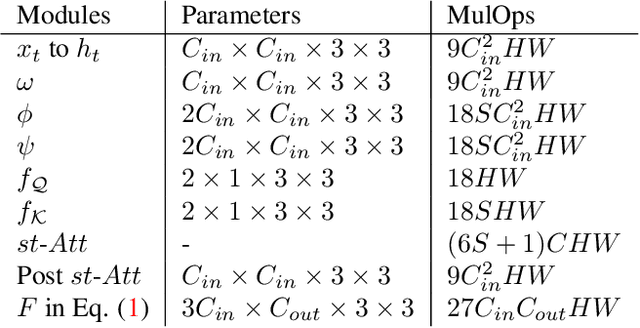


Endowing visual agents with predictive capability is a key step towards video intelligence at scale. The predominant modeling paradigm for this is sequence learning, mostly implemented through LSTMs. Feed-forward Transformer architectures have replaced recurrent model designs in ML applications of language processing and also partly in computer vision. In this paper we investigate on the competitiveness of Transformer-style architectures for video predictive tasks. To do so we propose HORST, a novel higher order recurrent layer design whose core element is a spatial-temporal decomposition of self-attention for video. HORST achieves state of the art competitive performance on Something-Something-V2 early action recognition and EPIC-Kitchens-55 action anticipation, without exploiting a task specific design. We believe this is promising evidence of causal predictive capability that we attribute to our recurrent higher order design of self-attention.