 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultispectral airborne laser scanning for tree species classification: a benchmark of machine learning and deep learning algorithms
Apr 19, 2025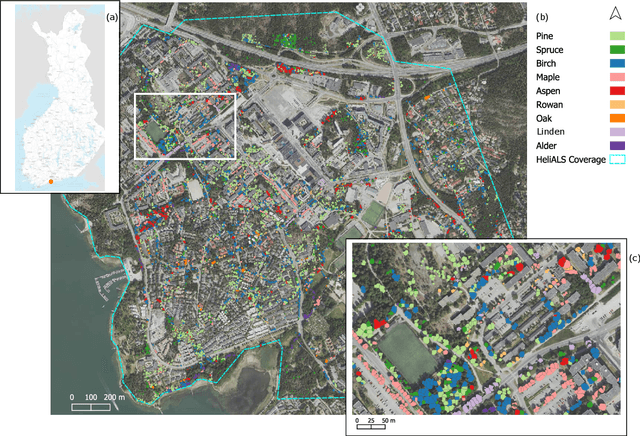


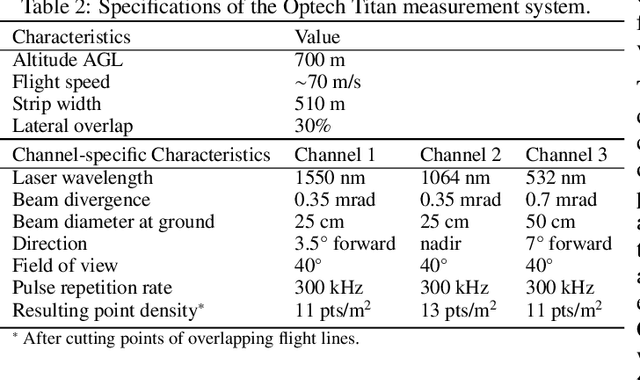
Climate-smart and biodiversity-preserving forestry demands precise information on forest resources, extending to the individual tree level. Multispectral airborne laser scanning (ALS) has shown promise in automated point cloud processing and tree segmentation, but challenges remain in identifying rare tree species and leveraging deep learning techniques. This study addresses these gaps by conducting a comprehensive benchmark of machine learning and deep learning methods for tree species classification. For the study, we collected high-density multispectral ALS data (>1000 pts/m$^2$) at three wavelengths using the FGI-developed HeliALS system, complemented by existing Optech Titan data (35 pts/m$^2$), to evaluate the species classification accuracy of various algorithms in a test site located in Southern Finland. Based on 5261 test segments, our findings demonstrate that point-based deep learning methods, particularly a point transformer model, outperformed traditional machine learning and image-based deep learning approaches on high-density multispectral point clouds. For the high-density ALS dataset, a point transformer model provided the best performance reaching an overall (macro-average) accuracy of 87.9% (74.5%) with a training set of 1065 segments and 92.0% (85.1%) with 5000 training segments. The best image-based deep learning method, DetailView, reached an overall (macro-average) accuracy of 84.3% (63.9%), whereas a random forest (RF) classifier achieved an overall (macro-average) accuracy of 83.2% (61.3%). Importantly, the overall classification accuracy of the point transformer model on the HeliALS data increased from 73.0% with no spectral information to 84.7% with single-channel reflectance, and to 87.9% with spectral information of all the three channels.
Speech Representation Learning Through Self-supervised Pretraining And Multi-task Finetuning
Oct 18, 2021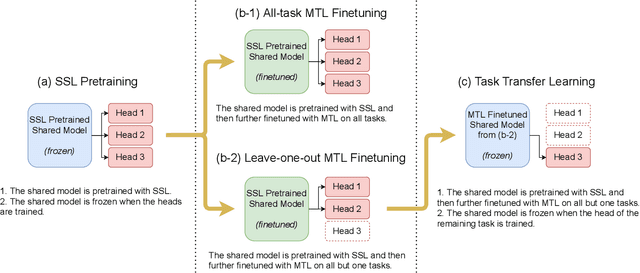
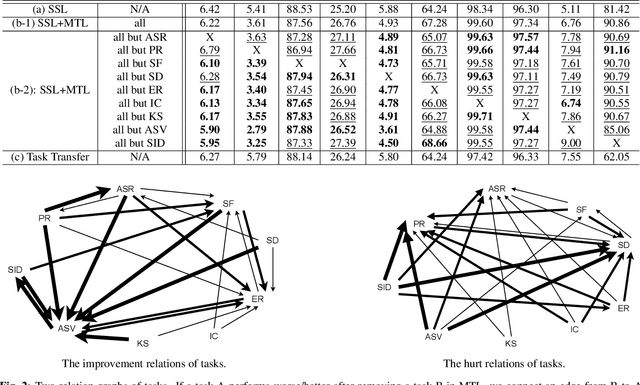
Speech representation learning plays a vital role in speech processing. Among them, self-supervised learning (SSL) has become an important research direction. It has been shown that an SSL pretraining model can achieve excellent performance in various downstream tasks of speech processing. On the other hand, supervised multi-task learning (MTL) is another representation learning paradigm, which has been proven effective in computer vision (CV) and natural language processing (NLP). However, there is no systematic research on the general representation learning model trained by supervised MTL in speech processing. In this paper, we show that MTL finetuning can further improve SSL pretraining. We analyze the generalizability of supervised MTL finetuning to examine if the speech representation learned by MTL finetuning can generalize to unseen new tasks.
SpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 31, 2021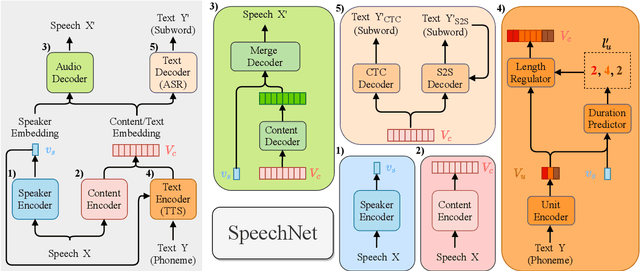
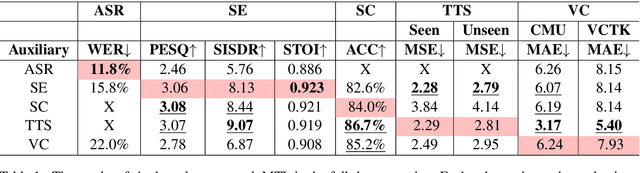
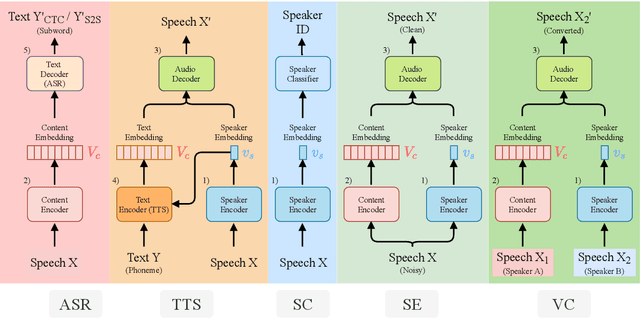
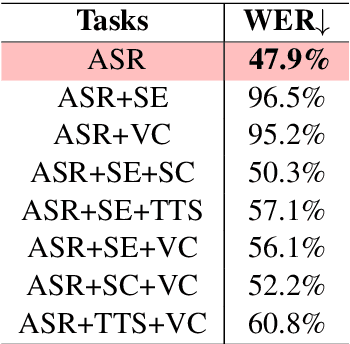
There is a wide variety of speech processing tasks ranging from extracting content information from speech signals to generating speech signals. For different tasks, model networks are usually designed and tuned separately. If a universal model can perform multiple speech processing tasks, some tasks might be improved with the related abilities learned from other tasks. The multi-task learning of a wide variety of speech processing tasks with a universal model has not been studied. This paper proposes a universal modularized model, SpeechNet, which treats all speech processing tasks into a speech/text input and speech/text output format. We select five essential speech processing tasks for multi-task learning experiments with SpeechNet. We show that SpeechNet learns all of the above tasks, and we further analyze which tasks can be improved by other tasks. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We release the code and experimental settings to facilitate the research of modularized universal models and multi-task learning of speech processing tasks.
Self-supervised Pre-training Reduces Label Permutation Instability of Speech Separation
Oct 29, 2020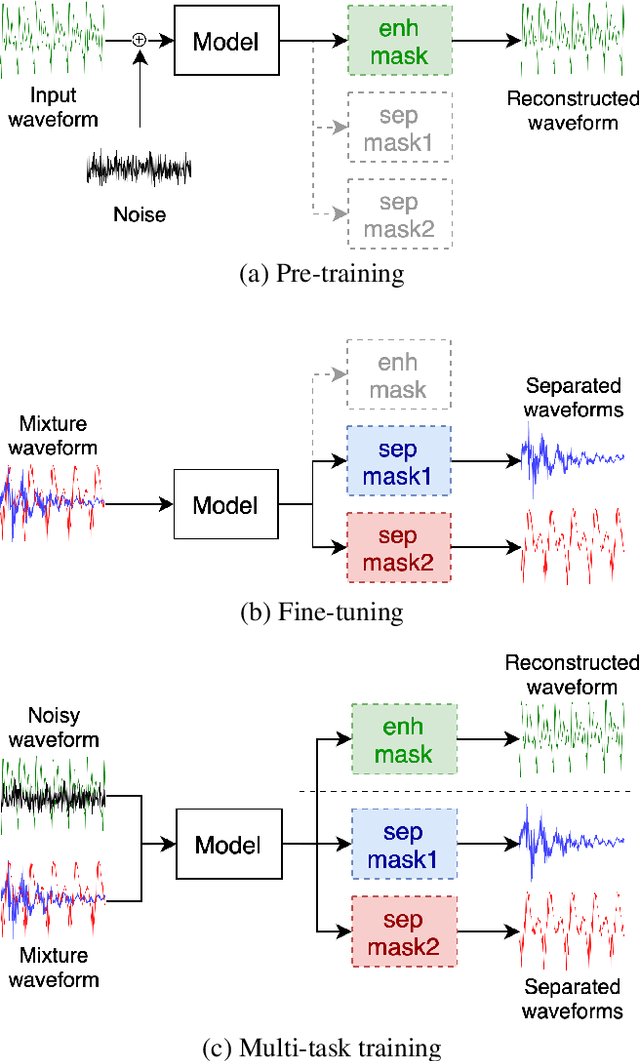
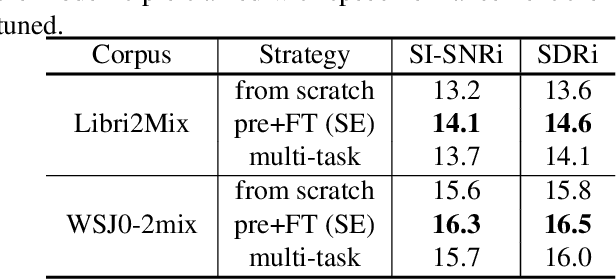
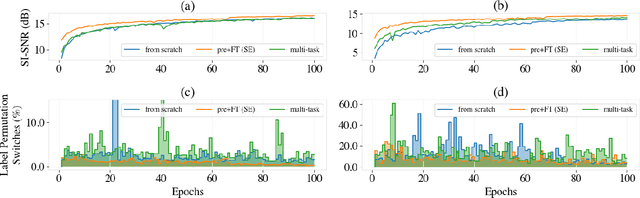
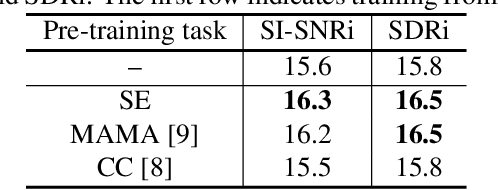
Speech separation has been well-developed while there are still problems waiting to be solved. The main problem we focus on in this paper is the frequent label permutation switching of permutation invariant training (PIT). For N-speaker separation, there would be N! possible label permutations. How to stably select correct label permutations is a long-standing problem. In this paper, we utilize self-supervised pre-training to stabilize the label permutations. Among several types of self-supervised tasks, speech enhancement based pre-training tasks show significant effectiveness in our experiments. When using off-the-shelf pre-trained models, training duration could be shortened to one-third to two-thirds. Furthermore, even taking pre-training time into account, the entire training process could still be shorter without a performance drop when using a larger batch size.
DARTS-ASR: Differentiable Architecture Search for Multilingual Speech Recognition and Adaptation
May 13, 2020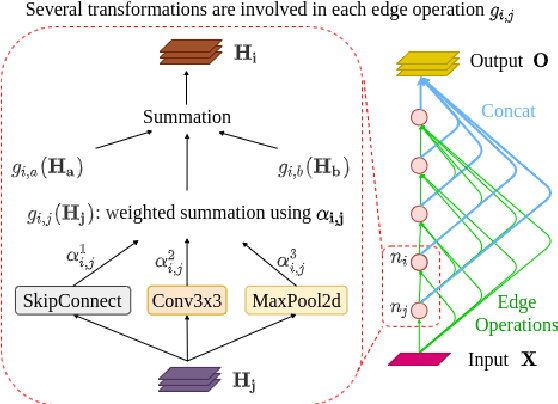
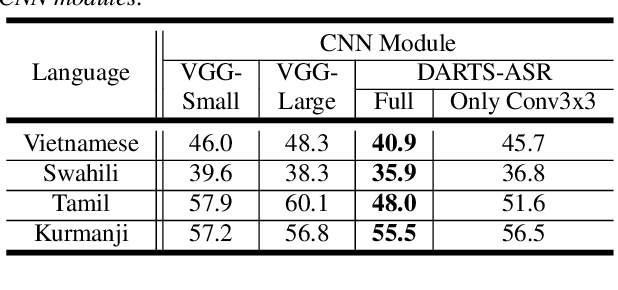
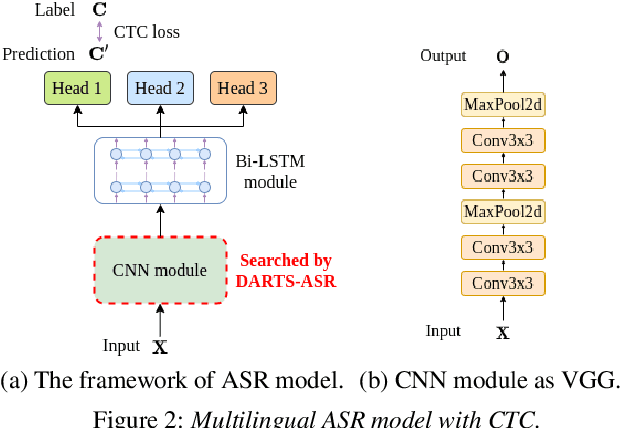
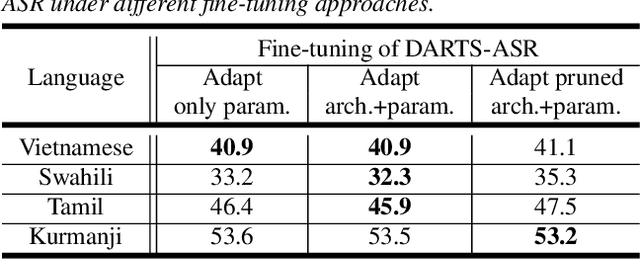
In previous works, only parameter weights of ASR models are optimized under fixed-topology architecture. However, the design of successful model architecture has always relied on human experience and intuition. Besides, many hyperparameters related to model architecture need to be manually tuned. Therefore in this paper, we propose an ASR approach with efficient gradient-based architecture search, DARTS-ASR. In order to examine the generalizability of DARTS-ASR, we apply our approach not only on many languages to perform monolingual ASR, but also on a multilingual ASR setting. Following previous works, we conducted experiments on a multilingual dataset, IARPA BABEL. The experiment results show that our approach outperformed the baseline fixed-topology architecture by 10.2% and 10.0% relative reduction on character error rates under monolingual and multilingual ASR settings respectively. Furthermore, we perform some analysis on the searched architectures by DARTS-ASR.
AIPNet: Generative Adversarial Pre-training of Accent-invariant Networks for End-to-end Speech Recognition
Nov 27, 2019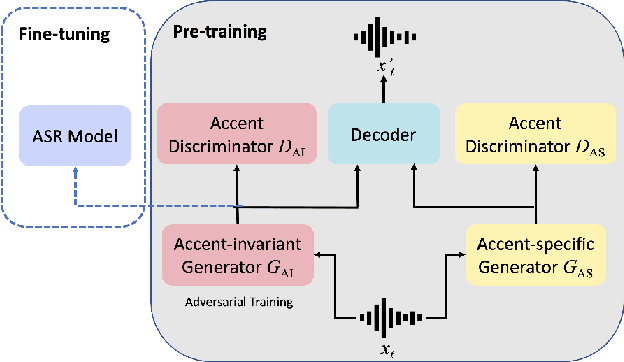
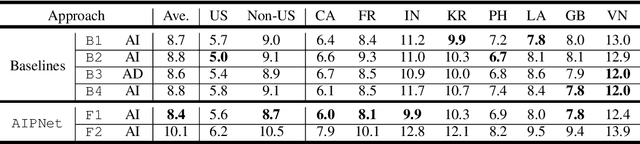
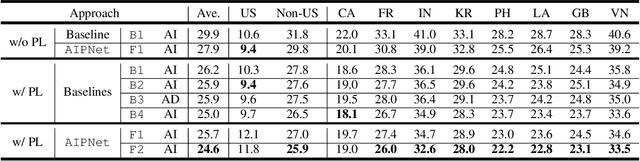
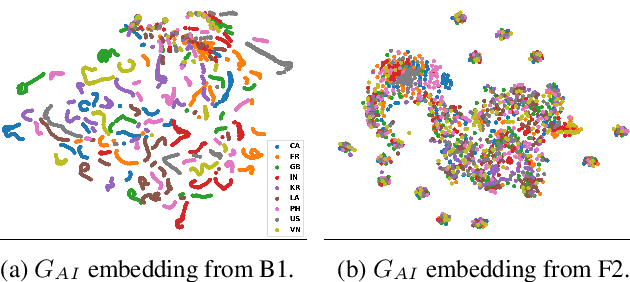
As one of the major sources in speech variability, accents have posed a grand challenge to the robustness of speech recognition systems. In this paper, our goal is to build a unified end-to-end speech recognition system that generalizes well across accents. For this purpose, we propose a novel pre-training framework AIPNet based on generative adversarial nets (GAN) for accent-invariant representation learning: Accent Invariant Pre-training Networks. We pre-train AIPNet to disentangle accent-invariant and accent-specific characteristics from acoustic features through adversarial training on accented data for which transcriptions are not necessarily available. We further fine-tune AIPNet by connecting the accent-invariant module with an attention-based encoder-decoder model for multi-accent speech recognition. In the experiments, our approach is compared against four baselines including both accent-dependent and accent-independent models. Experimental results on 9 English accents show that the proposed approach outperforms all the baselines by 2.3 \sim 4.5% relative reduction on average WER when transcriptions are available in all accents and by 1.6 \sim 6.1% relative reduction when transcriptions are only available in US accent.
From Semi-supervised to Almost-unsupervised Speech Recognition with Very-low Resource by Jointly Learning Phonetic Structures from Audio and Text Embeddings
Apr 10, 2019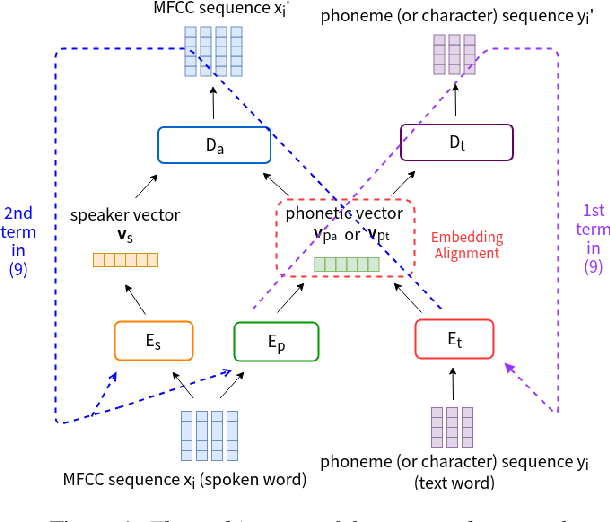
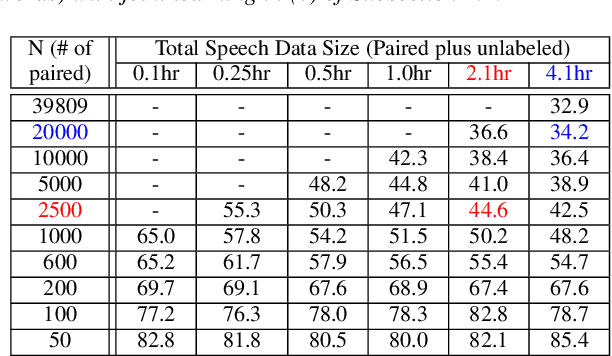
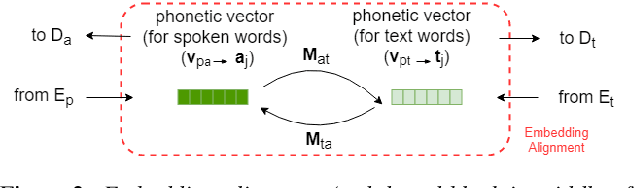

Producing a large amount of annotated speech data for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced. However, we note human babies start to learn the language by the sounds (or phonetic structures) of a small number of exemplar words, and "generalize" such knowledge to other words without hearing a large amount of data. We initiate some preliminary work in this direction. Audio Word2Vec is used to learn the phonetic structures from spoken words (signal segments), while another autoencoder is used to learn the phonetic structures from text words. The relationships among the above two can be learned jointly, or separately after the above two are well trained. This relationship can be used in speech recognition with very low resource. In the initial experiments on the TIMIT dataset, only 2.1 hours of speech data (in which 2500 spoken words were annotated and the rest unlabeled) gave a word error rate of 44.6%, and this number can be reduced to 34.2% if 4.1 hr of speech data (in which 20000 spoken words were annotated) were given. These results are not satisfactory, but a good starting point.
Improved Audio Embeddings by Adjacency-Based Clustering with Applications in Spoken Term Detection
Nov 07, 2018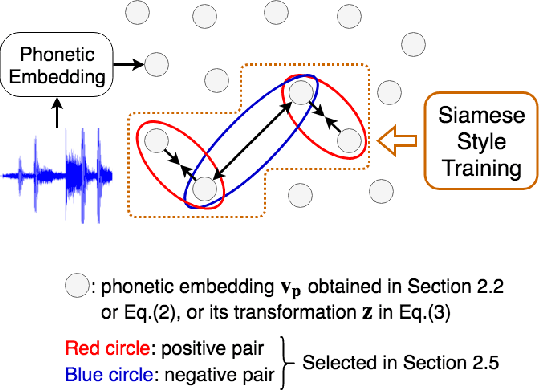
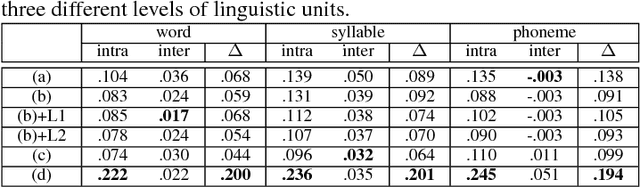
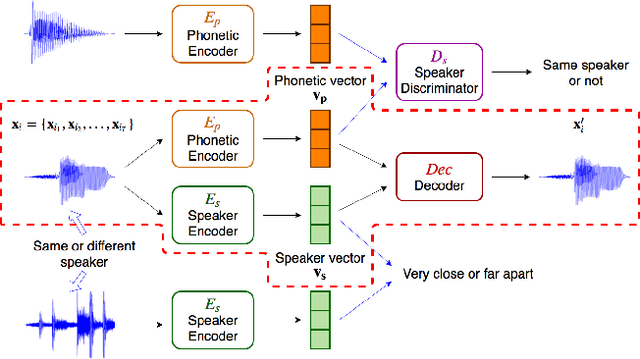
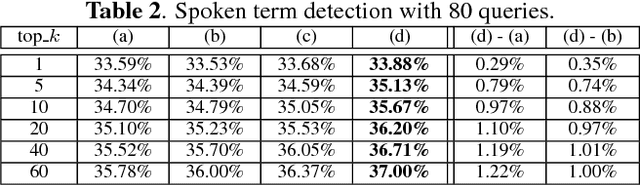
Embedding audio signal segments into vectors with fixed dimensionality is attractive because all following processing will be easier and more efficient, for example modeling, classifying or indexing. Audio Word2Vec previously proposed was shown to be able to represent audio segments for spoken words as such vectors carrying information about the phonetic structures of the signal segments. However, each linguistic unit (word, syllable, phoneme in text form) corresponds to unlimited number of audio segments with vector representations inevitably spread over the embedding space, which causes some confusion. It is therefore desired to better cluster the audio embeddings such that those corresponding to the same linguistic unit can be more compactly distributed. In this paper, inspired by Siamese networks, we propose some approaches to achieve the above goal. This includes identifying positive and negative pairs from unlabeled data for Siamese style training, disentangling acoustic factors such as speaker characteristics from the audio embedding, handling unbalanced data distribution, and having the embedding processes learn from the adjacency relationships among data points. All these can be done in an unsupervised way. Improved performance was obtained in preliminary experiments on the LibriSpeech data set, including clustering characteristics analysis and applications of spoken term detection.
Almost-unsupervised Speech Recognition with Close-to-zero Resource Based on Phonetic Structures Learned from Very Small Unpaired Speech and Text Data
Oct 30, 2018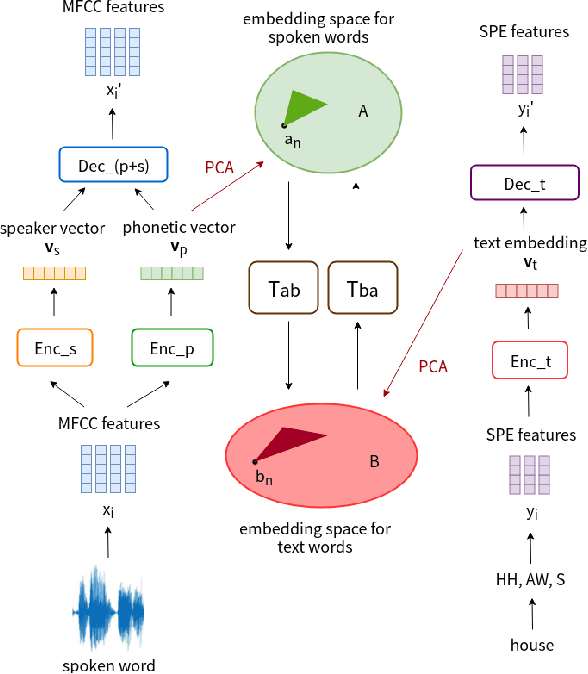
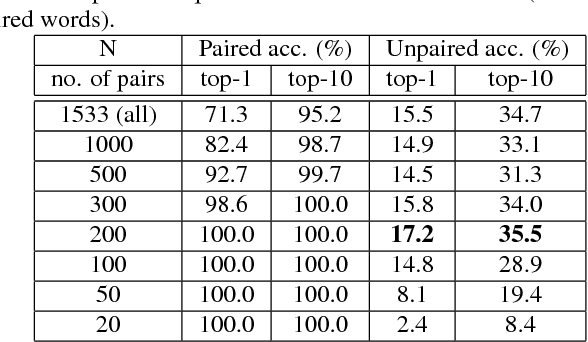
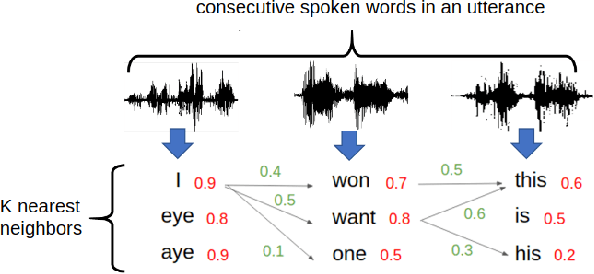
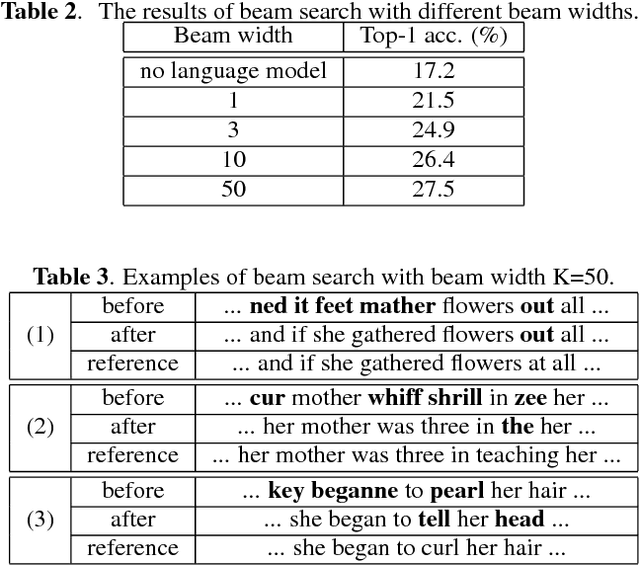
Producing a large amount of annotated speech data for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced. However, we note human babies start to learn the language by the sounds of a small number of exemplar words without hearing a large amount of data. We initiate some preliminary work in this direction in this paper. Audio Word2Vec is used to obtain embeddings of spoken words which carry phonetic information extracted from the signals. An autoencoder is used to generate embeddings of text words based on the articulatory features for the phoneme sequences. Both sets of embeddings for spoken and text words describe similar phonetic structures among words in their respective latent spaces. A mapping relation from the audio embeddings to text embeddings actually gives the word-level ASR. This can be learned by aligning a small number of spoken words and the corresponding text words in the embedding spaces. In the initial experiments only 200 annotated spoken words and one hour of speech data without annotation gave a word accuracy of 27.5%, which is low but a good starting point.
Phonetic-and-Semantic Embedding of Spoken Words with Applications in Spoken Content Retrieval
Sep 03, 2018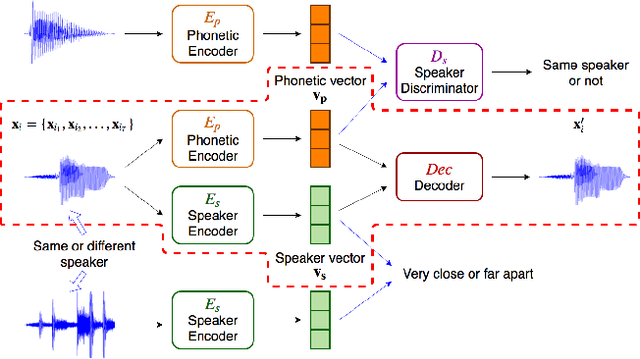
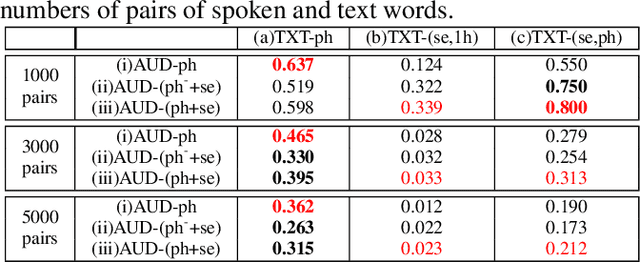
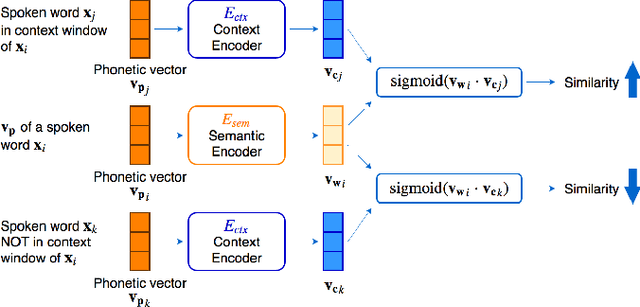
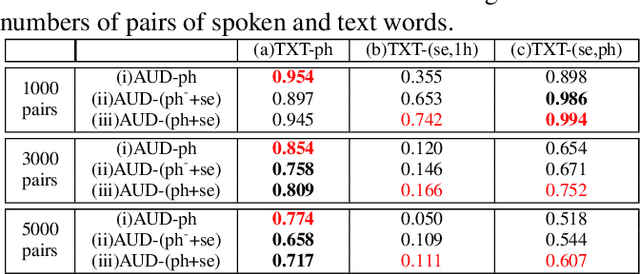
Word embedding or Word2Vec has been successful in offering semantics for text words learned from the context of words. Audio Word2Vec was shown to offer phonetic structures for spoken words (signal segments for words) learned from signals within spoken words. This paper proposes a two-stage framework to perform phonetic-and-semantic embedding on spoken words considering the context of the spoken words. Stage 1 performs phonetic embedding with speaker characteristics disentangled. Stage 2 then performs semantic embedding in addition. We further propose to evaluate the phonetic-and-semantic nature of the audio embeddings obtained in Stage 2 by parallelizing with text embeddings. In general, phonetic structure and semantics inevitably disturb each other. For example the words "brother" and "sister" are close in semantics but very different in phonetic structure, while the words "brother" and "bother" are in the other way around. But phonetic-and-semantic embedding is attractive, as shown in the initial experiments on spoken document retrieval. Not only spoken documents including the spoken query can be retrieved based on the phonetic structures, but spoken documents semantically related to the query but not including the query can also be retrieved based on the semantics.