 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Audio Embeddings by Adjacency-Based Clustering with Applications in Spoken Term Detection
Paper and Code
Nov 07, 2018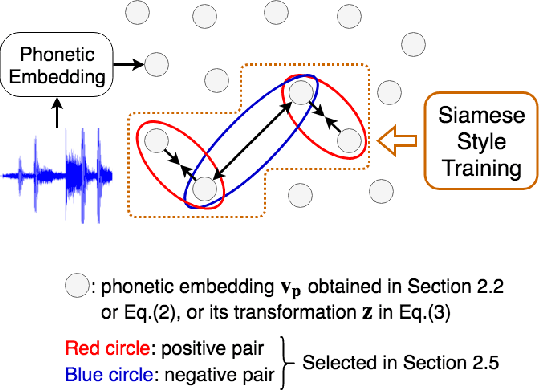
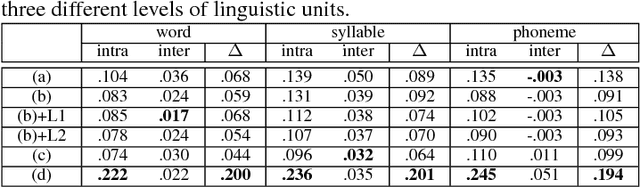
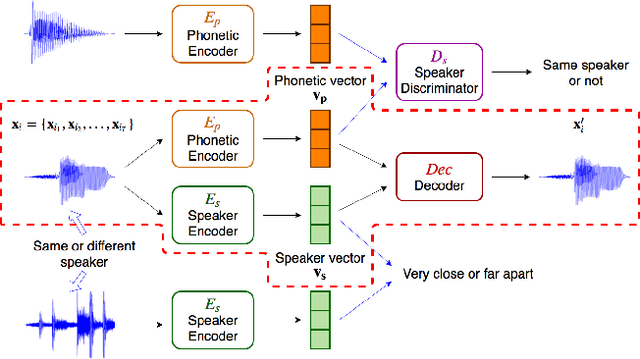
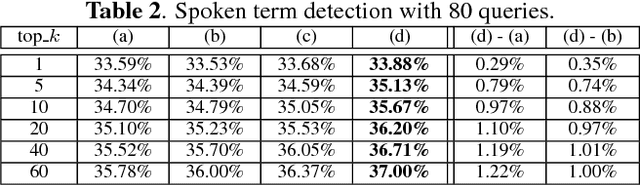
Embedding audio signal segments into vectors with fixed dimensionality is attractive because all following processing will be easier and more efficient, for example modeling, classifying or indexing. Audio Word2Vec previously proposed was shown to be able to represent audio segments for spoken words as such vectors carrying information about the phonetic structures of the signal segments. However, each linguistic unit (word, syllable, phoneme in text form) corresponds to unlimited number of audio segments with vector representations inevitably spread over the embedding space, which causes some confusion. It is therefore desired to better cluster the audio embeddings such that those corresponding to the same linguistic unit can be more compactly distributed. In this paper, inspired by Siamese networks, we propose some approaches to achieve the above goal. This includes identifying positive and negative pairs from unlabeled data for Siamese style training, disentangling acoustic factors such as speaker characteristics from the audio embedding, handling unbalanced data distribution, and having the embedding processes learn from the adjacency relationships among data points. All these can be done in an unsupervised way. Improved performance was obtained in preliminary experiments on the LibriSpeech data set, including clustering characteristics analysis and applications of spoken term detection.