 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Pre-training Reduces Label Permutation Instability of Speech Separation
Paper and Code
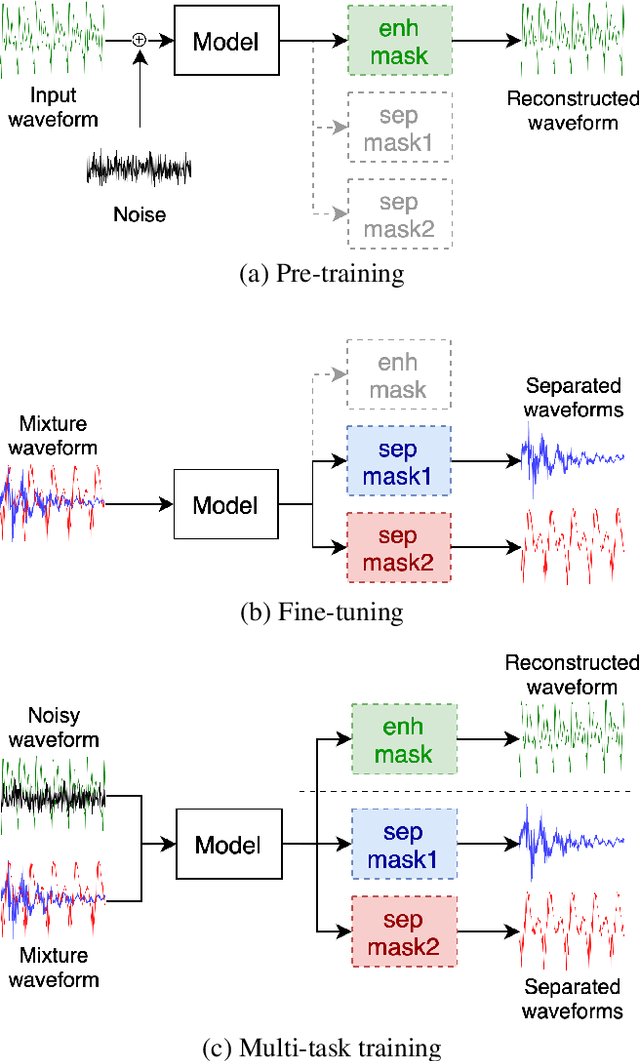
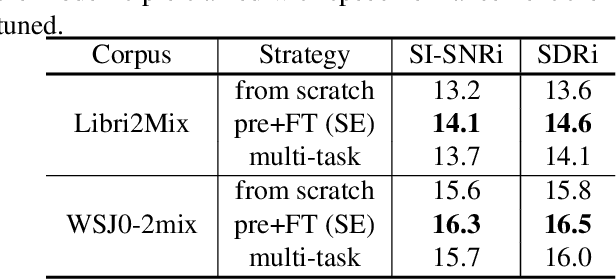
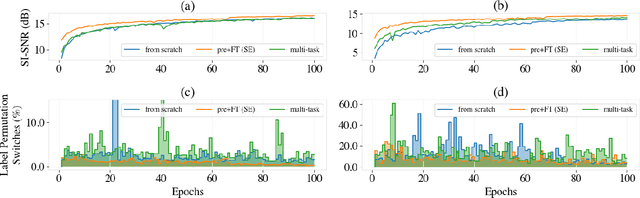
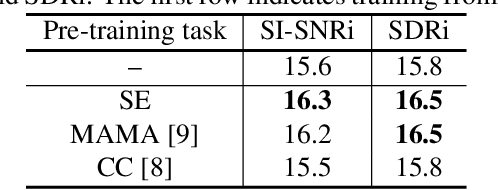
Speech separation has been well-developed while there are still problems waiting to be solved. The main problem we focus on in this paper is the frequent label permutation switching of permutation invariant training (PIT). For N-speaker separation, there would be N! possible label permutations. How to stably select correct label permutations is a long-standing problem. In this paper, we utilize self-supervised pre-training to stabilize the label permutations. Among several types of self-supervised tasks, speech enhancement based pre-training tasks show significant effectiveness in our experiments. When using off-the-shelf pre-trained models, training duration could be shortened to one-third to two-thirds. Furthermore, even taking pre-training time into account, the entire training process could still be shorter without a performance drop when using a larger batch size.