 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImGeoNet: Image-induced Geometry-aware Voxel Representation for Multi-view 3D Object Detection
Aug 17, 2023



We propose ImGeoNet, a multi-view image-based 3D object detection framework that models a 3D space by an image-induced geometry-aware voxel representation. Unlike previous methods which aggregate 2D features into 3D voxels without considering geometry, ImGeoNet learns to induce geometry from multi-view images to alleviate the confusion arising from voxels of free space, and during the inference phase, only images from multiple views are required. Besides, a powerful pre-trained 2D feature extractor can be leveraged by our representation, leading to a more robust performance. To evaluate the effectiveness of ImGeoNet, we conduct quantitative and qualitative experiments on three indoor datasets, namely ARKitScenes, ScanNetV2, and ScanNet200. The results demonstrate that ImGeoNet outperforms the current state-of-the-art multi-view image-based method, ImVoxelNet, on all three datasets in terms of detection accuracy. In addition, ImGeoNet shows great data efficiency by achieving results comparable to ImVoxelNet with 100 views while utilizing only 40 views. Furthermore, our studies indicate that our proposed image-induced geometry-aware representation can enable image-based methods to attain superior detection accuracy than the seminal point cloud-based method, VoteNet, in two practical scenarios: (1) scenarios where point clouds are sparse and noisy, such as in ARKitScenes, and (2) scenarios involve diverse object classes, particularly classes of small objects, as in the case in ScanNet200.
EURO: ESPnet Unsupervised ASR Open-source Toolkit
Dec 01, 2022



This paper describes the ESPnet Unsupervised ASR Open-source Toolkit (EURO), an end-to-end open-source toolkit for unsupervised automatic speech recognition (UASR). EURO adopts the state-of-the-art UASR learning method introduced by the Wav2vec-U, originally implemented at FAIRSEQ, which leverages self-supervised speech representations and adversarial training. In addition to wav2vec2, EURO extends the functionality and promotes reproducibility for UASR tasks by integrating S3PRL and k2, resulting in flexible frontends from 27 self-supervised models and various graph-based decoding strategies. EURO is implemented in ESPnet and follows its unified pipeline to provide UASR recipes with a complete setup. This improves the pipeline's efficiency and allows EURO to be easily applied to existing datasets in ESPnet. Extensive experiments on three mainstream self-supervised models demonstrate the toolkit's effectiveness and achieve state-of-the-art UASR performance on TIMIT and LibriSpeech datasets. EURO will be publicly available at https://github.com/espnet/espnet, aiming to promote this exciting and emerging research area based on UASR through open-source activity.
Anticipation-free Training for Simultaneous Translation
Jan 30, 2022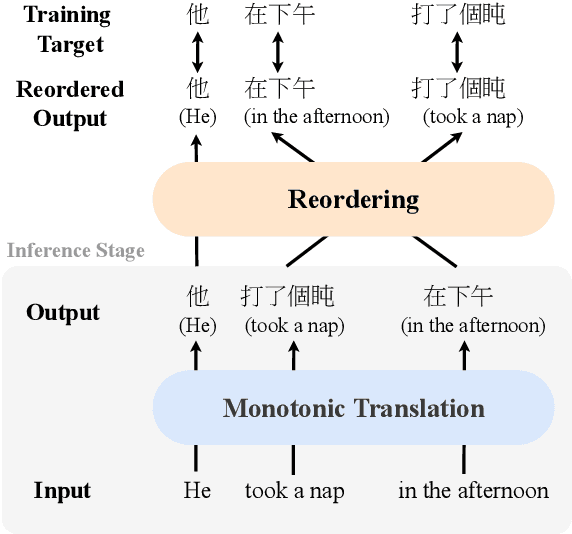



Simultaneous translation (SimulMT) speeds up the translation process by starting to translate before the source sentence is completely available. It is difficult due to limited context and word order difference between languages. Existing methods increase latency or introduce adaptive read-write policies for SimulMT models to handle local reordering and improve translation quality. However, the long-distance reordering would make the SimulMT models learn translation mistakenly. Specifically, the model may be forced to predict target tokens when the corresponding source tokens have not been read. This leads to aggressive anticipation during inference, resulting in the hallucination phenomenon. To mitigate this problem, we propose a new framework that decompose the translation process into the monotonic translation step and the reordering step, and we model the latter by the auxiliary sorting network (ASN). The ASN rearranges the hidden states to match the order in the target language, so that the SimulMT model could learn to translate more reasonably. The entire model is optimized end-to-end and does not rely on external aligners or data. During inference, ASN is removed to achieve streaming. Experiments show the proposed framework could outperform previous methods with less latency.\footnote{The source code is available.
Investigating the Reordering Capability in CTC-based Non-Autoregressive End-to-End Speech Translation
May 11, 2021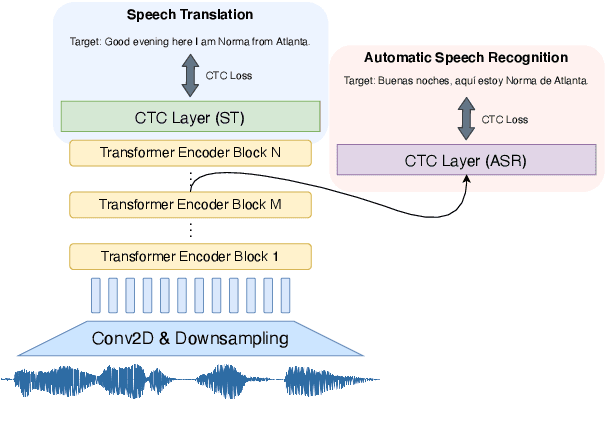
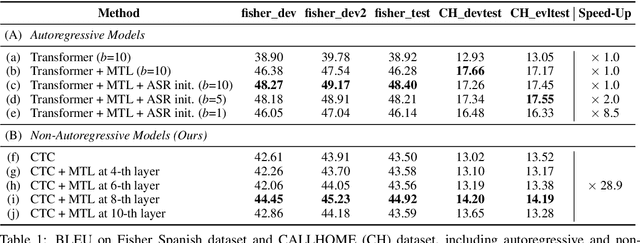
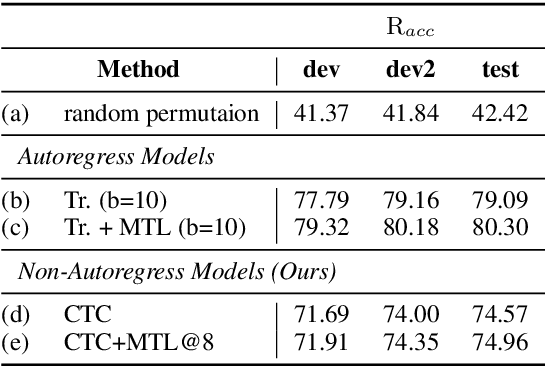
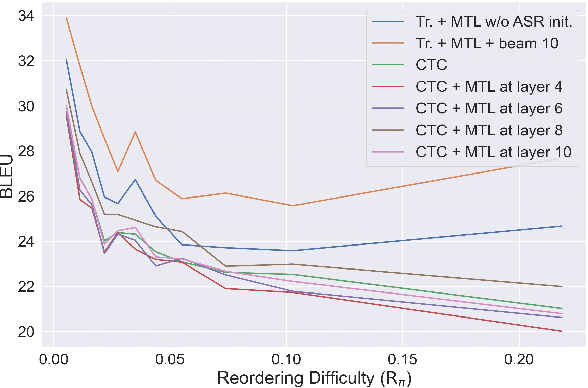
We study the possibilities of building a non-autoregressive speech-to-text translation model using connectionist temporal classification (CTC), and use CTC-based automatic speech recognition as an auxiliary task to improve the performance. CTC's success on translation is counter-intuitive due to its monotonicity assumption, so we analyze its reordering capability. Kendall's tau distance is introduced as the quantitative metric, and gradient-based visualization provides an intuitive way to take a closer look into the model. Our analysis shows that transformer encoders have the ability to change the word order and points out the future research direction that worth being explored more on non-autoregressive speech translation.
Non-autoregressive Mandarin-English Code-switching Speech Recognition with Pinyin Mask-CTC and Word Embedding Regularization
Apr 06, 2021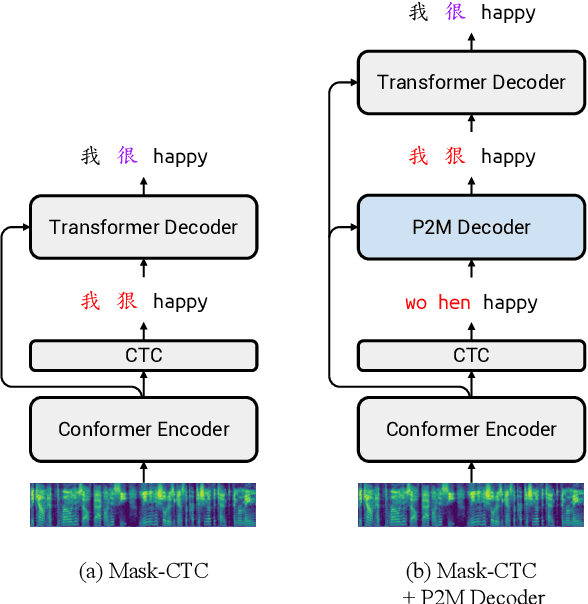
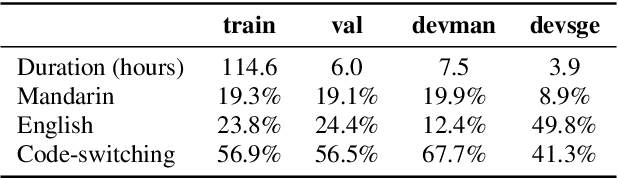
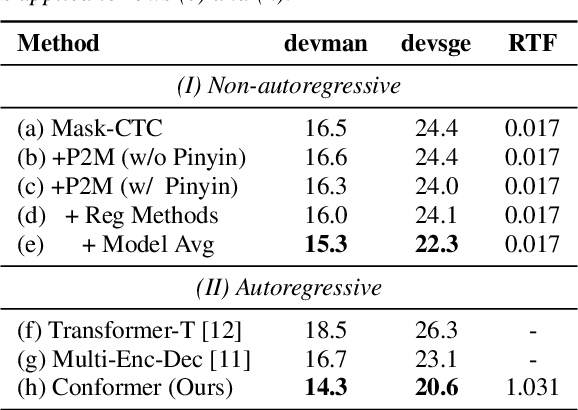
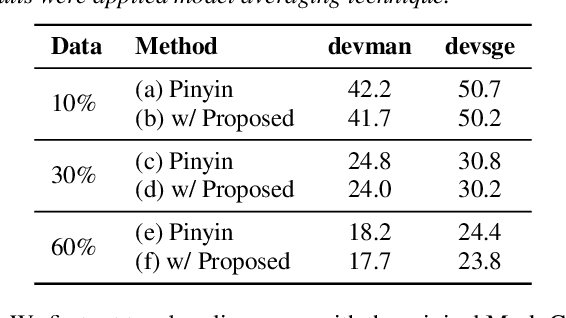
Mandarin-English code-switching (CS) is frequently used among East and Southeast Asian people. However, the intra-sentence language switching of the two very different languages makes recognizing CS speech challenging. Meanwhile, the recent successful non-autoregressive (NAR) ASR models remove the need for left-to-right beam decoding in autoregressive (AR) models and achieved outstanding performance and fast inference speed. Therefore, in this paper, we took advantage of the Mask-CTC NAR ASR framework to tackle the CS speech recognition issue. We propose changing the Mandarin output target of the encoder to Pinyin for faster encoder training, and introduce Pinyin-to-Mandarin decoder to learn contextualized information. Moreover, we propose word embedding label smoothing to regularize the decoder with contextualized information and projection matrix regularization to bridge that gap between the encoder and decoder. We evaluate the proposed methods on the SEAME corpus and achieved exciting results.
Self-supervised Pre-training Reduces Label Permutation Instability of Speech Separation
Oct 29, 2020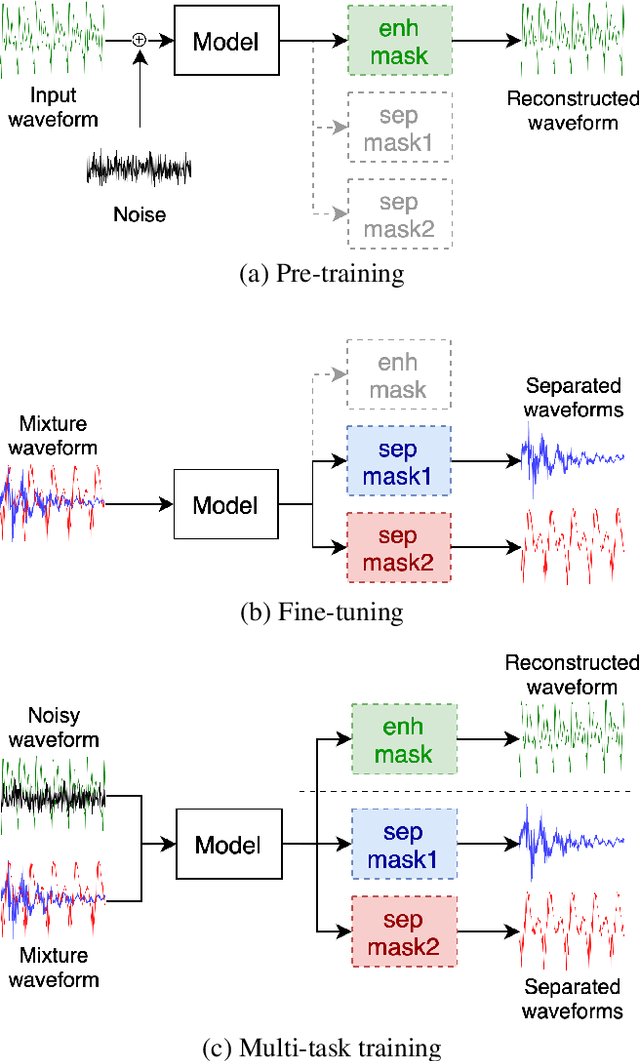
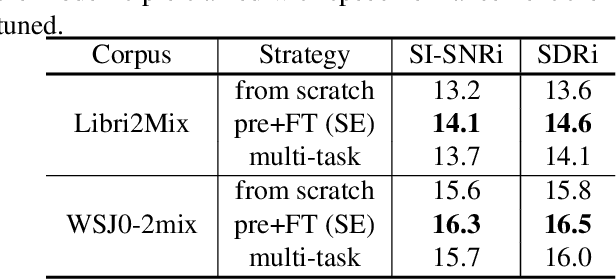
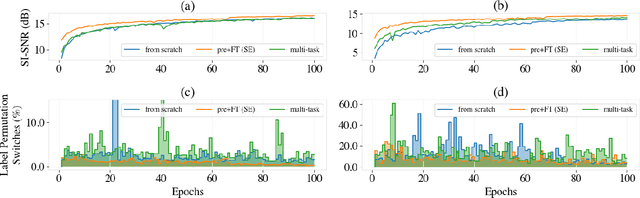
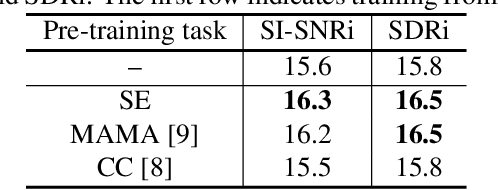
Speech separation has been well-developed while there are still problems waiting to be solved. The main problem we focus on in this paper is the frequent label permutation switching of permutation invariant training (PIT). For N-speaker separation, there would be N! possible label permutations. How to stably select correct label permutations is a long-standing problem. In this paper, we utilize self-supervised pre-training to stabilize the label permutations. Among several types of self-supervised tasks, speech enhancement based pre-training tasks show significant effectiveness in our experiments. When using off-the-shelf pre-trained models, training duration could be shortened to one-third to two-thirds. Furthermore, even taking pre-training time into account, the entire training process could still be shorter without a performance drop when using a larger batch size.
Worse WER, but Better BLEU? Leveraging Word Embedding as Intermediate in Multitask End-to-End Speech Translation
May 21, 2020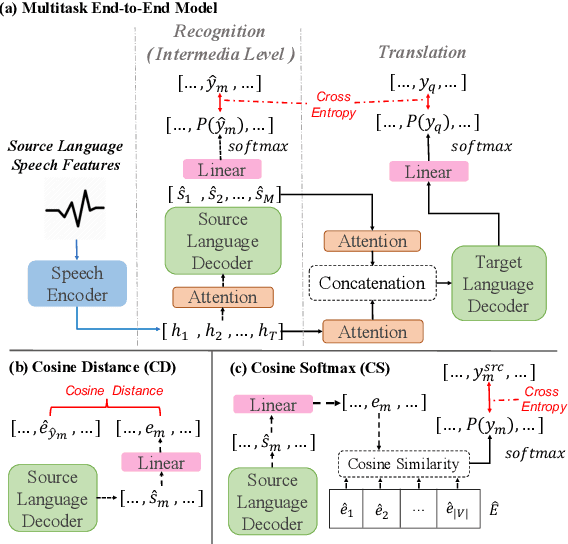

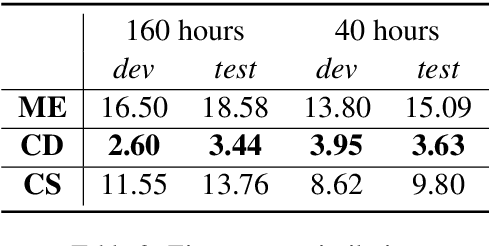
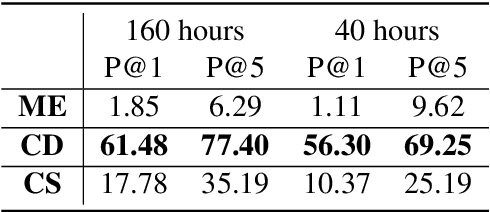
Speech translation (ST) aims to learn transformations from speech in the source language to the text in the target language. Previous works show that multitask learning improves the ST performance, in which the recognition decoder generates the text of the source language, and the translation decoder obtains the final translations based on the output of the recognition decoder. Because whether the output of the recognition decoder has the correct semantics is more critical than its accuracy, we propose to improve the multitask ST model by utilizing word embedding as the intermediate.
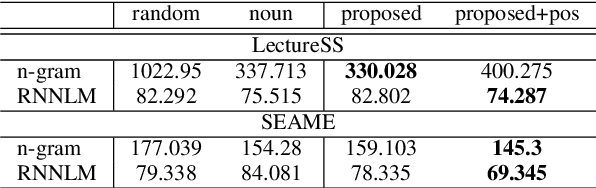
Training a code-switching language model with monolingual data
Nov 14, 2019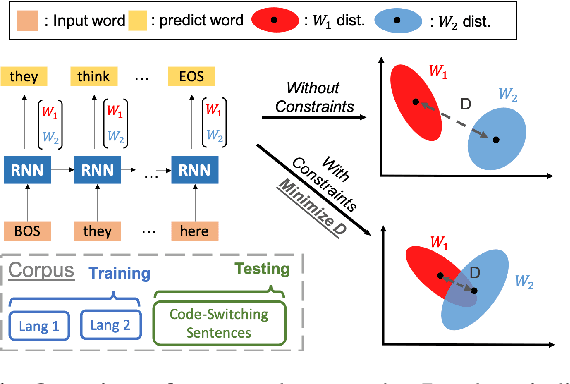
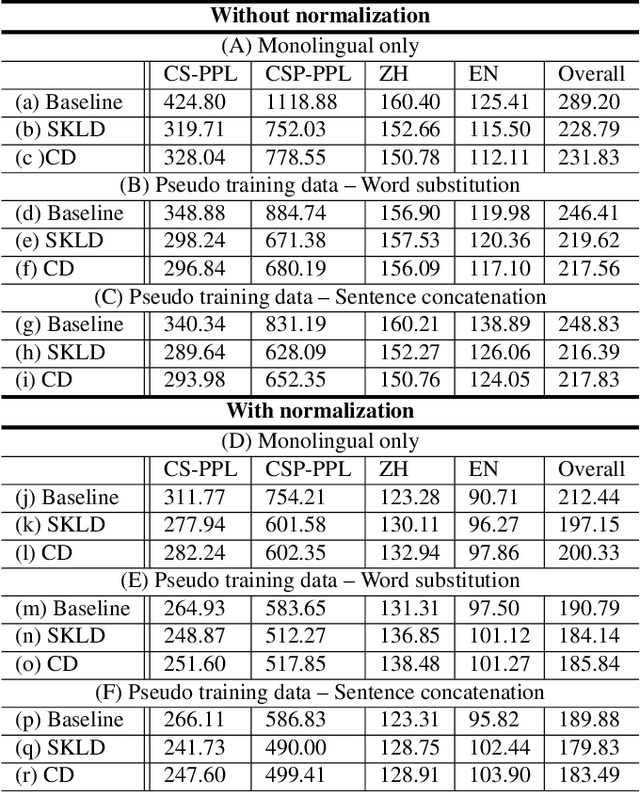
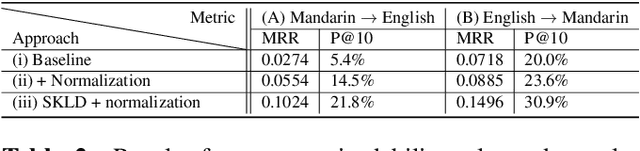
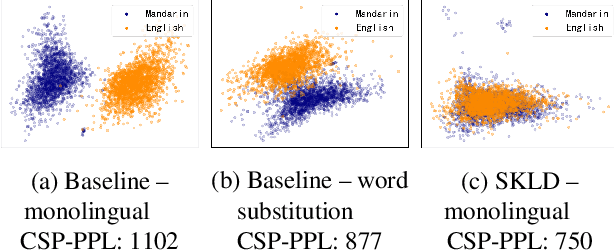
A lack of code-switching data complicates the training of code-switching (CS) language models. We propose an approach to train such CS language models on monolingual data only. By constraining and normalizing the output projection matrix in RNN-based language models, we bring embeddings of different languages closer to each other. Numerical and visualization results show that the proposed approaches remarkably improve the performance of CS language models trained on monolingual data. The proposed approaches are comparable or even better than training CS language models with artificially generated CS data. We additionally use unsupervised bilingual word translation to analyze whether semantically equivalent words in different languages are mapped together.
Sequence-to-sequence Automatic Speech Recognition with Word Embedding Regularization and Fused Decoding
Oct 28, 2019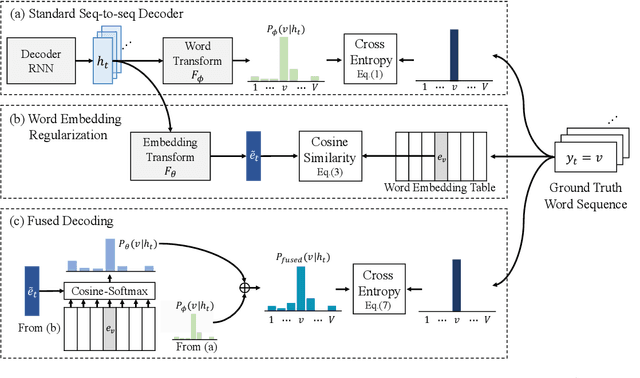

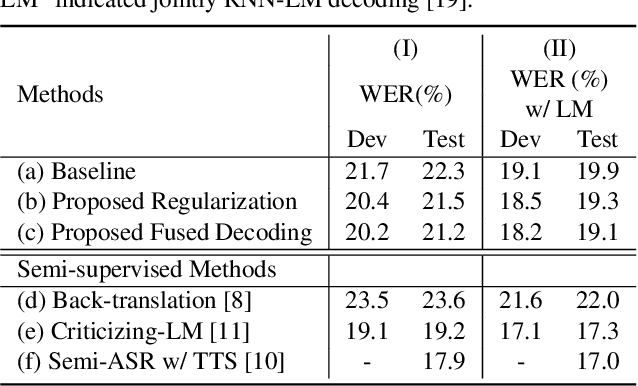
In this paper, we investigate the benefit that off-the-shelf word embedding can bring to the sequence-to-sequence (seq-to-seq) automatic speech recognition (ASR). We first introduced the word embedding regularization by maximizing the cosine similarity between a transformed decoder feature and the target word embedding. Based on the regularized decoder, we further proposed the fused decoding mechanism. This allows the decoder to consider the semantic consistency during decoding by absorbing the information carried by the transformed decoder feature, which is learned to be close to the target word embedding. Initial results on LibriSpeech demonstrated that pre-trained word embedding can significantly lower ASR recognition error with a negligible cost, and the choice of word embedding algorithms among Skip-gram, CBOW and BERT is important.
Code-switching Sentence Generation by Generative Adversarial Networks and its Application to Data Augmentation
Nov 19, 2018


Code-switching is about dealing with alternative languages in speech or text. It is partially speaker-depend and domain-related, so completely explaining the phenomenon by linguistic rules is challenging. Compared to monolingual tasks, insufficient data is an issue for code-switching. To mitigate the issue without expensive human annotation, we proposed an unsupervised method for code-switching data augmentation. By utilizing a generative adversarial network, we can generate intra-sentential code-switching sentences from monolingual sentences. We applied proposed method on two corpora, and the result shows that the generated code-switching sentences improve the performance of code-switching language models.