 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-SAM: Multi-view Promptable Segmentation using Pointmap Guidance
Jan 25, 2026Promptable segmentation has emerged as a powerful paradigm in computer vision, enabling users to guide models in parsing complex scenes with prompts such as clicks, boxes, or textual cues. Recent advances, exemplified by the Segment Anything Model (SAM), have extended this paradigm to videos and multi-view images. However, the lack of 3D awareness often leads to inconsistent results, necessitating costly per-scene optimization to enforce 3D consistency. In this work, we introduce MV-SAM, a framework for multi-view segmentation that achieves 3D consistency using pointmaps -- 3D points reconstructed from unposed images by recent visual geometry models. Leveraging the pixel-point one-to-one correspondence of pointmaps, MV-SAM lifts images and prompts into 3D space, eliminating the need for explicit 3D networks or annotated 3D data. Specifically, MV-SAM extends SAM by lifting image embeddings from its pretrained encoder into 3D point embeddings, which are decoded by a transformer using cross-attention with 3D prompt embeddings. This design aligns 2D interactions with 3D geometry, enabling the model to implicitly learn consistent masks across views through 3D positional embeddings. Trained on the SA-1B dataset, our method generalizes well across domains, outperforming SAM2-Video and achieving comparable performance with per-scene optimization baselines on NVOS, SPIn-NeRF, ScanNet++, uCo3D, and DL3DV benchmarks. Code will be released.
Advancing Structured Priors for Sparse-Voxel Surface Reconstruction
Jan 25, 2026Reconstructing accurate surfaces with radiance fields has progressed rapidly, yet two promising explicit representations, 3D Gaussian Splatting and sparse-voxel rasterization, exhibit complementary strengths and weaknesses. 3D Gaussian Splatting converges quickly and carries useful geometric priors, but surface fidelity is limited by its point-like parameterization. Sparse-voxel rasterization provides continuous opacity fields and crisp geometry, but its typical uniform dense-grid initialization slows convergence and underutilizes scene structure. We combine the advantages of both by introducing a voxel initialization method that places voxels at plausible locations and with appropriate levels of detail, yielding a strong starting point for per-scene optimization. To further enhance depth consistency without blurring edges, we propose refined depth geometry supervision that converts multi-view cues into direct per-ray depth regularization. Experiments on standard benchmarks demonstrate improvements over prior methods in geometric accuracy, better fine-structure recovery, and more complete surfaces, while maintaining fast convergence.
3AM: 3egment Anything with Geometric Consistency in Videos
Jan 18, 2026Video object segmentation methods like SAM2 achieve strong performance through memory-based architectures but struggle under large viewpoint changes due to reliance on appearance features. Traditional 3D instance segmentation methods address viewpoint consistency but require camera poses, depth maps, and expensive preprocessing. We introduce 3AM, a training-time enhancement that integrates 3D-aware features from MUSt3R into SAM2. Our lightweight Feature Merger fuses multi-level MUSt3R features that encode implicit geometric correspondence. Combined with SAM2's appearance features, the model achieves geometry-consistent recognition grounded in both spatial position and visual similarity. We propose a field-of-view aware sampling strategy ensuring frames observe spatially consistent object regions for reliable 3D correspondence learning. Critically, our method requires only RGB input at inference, with no camera poses or preprocessing. On challenging datasets with wide-baseline motion (ScanNet++, Replica), 3AM substantially outperforms SAM2 and extensions, achieving 90.6% IoU and 71.7% Positive IoU on ScanNet++'s Selected Subset, improving over state-of-the-art VOS methods by +15.9 and +30.4 points. Project page: https://jayisaking.github.io/3AM-Page/
OpenVoxel: Training-Free Grouping and Captioning Voxels for Open-Vocabulary 3D Scene Understanding
Jan 14, 2026We propose OpenVoxel, a training-free algorithm for grouping and captioning sparse voxels for the open-vocabulary 3D scene understanding tasks. Given the sparse voxel rasterization (SVR) model obtained from multi-view images of a 3D scene, our OpenVoxel is able to produce meaningful groups that describe different objects in the scene. Also, by leveraging powerful Vision Language Models (VLMs) and Multi-modal Large Language Models (MLLMs), our OpenVoxel successfully build an informative scene map by captioning each group, enabling further 3D scene understanding tasks such as open-vocabulary segmentation (OVS) or referring expression segmentation (RES). Unlike previous methods, our method is training-free and does not introduce embeddings from a CLIP/BERT text encoder. Instead, we directly proceed with text-to-text search using MLLMs. Through extensive experiments, our method demonstrates superior performance compared to recent studies, particularly in complex referring expression segmentation (RES) tasks. The code will be open.
3AM: Segment Anything with Geometric Consistency in Videos
Jan 13, 2026Video object segmentation methods like SAM2 achieve strong performance through memory-based architectures but struggle under large viewpoint changes due to reliance on appearance features. Traditional 3D instance segmentation methods address viewpoint consistency but require camera poses, depth maps, and expensive preprocessing. We introduce 3AM, a training-time enhancement that integrates 3D-aware features from MUSt3R into SAM2. Our lightweight Feature Merger fuses multi-level MUSt3R features that encode implicit geometric correspondence. Combined with SAM2's appearance features, the model achieves geometry-consistent recognition grounded in both spatial position and visual similarity. We propose a field-of-view aware sampling strategy ensuring frames observe spatially consistent object regions for reliable 3D correspondence learning. Critically, our method requires only RGB input at inference, with no camera poses or preprocessing. On challenging datasets with wide-baseline motion (ScanNet++, Replica), 3AM substantially outperforms SAM2 and extensions, achieving 90.6% IoU and 71.7% Positive IoU on ScanNet++'s Selected Subset, improving over state-of-the-art VOS methods by +15.9 and +30.4 points. Project page: https://jayisaking.github.io/3AM-Page/
Quantile Rendering: Efficiently Embedding High-dimensional Feature on 3D Gaussian Splatting
Dec 24, 2025

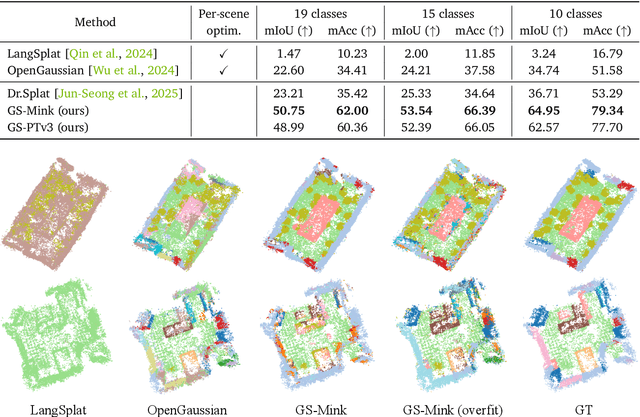

Recent advancements in computer vision have successfully extended Open-vocabulary segmentation (OVS) to the 3D domain by leveraging 3D Gaussian Splatting (3D-GS). Despite this progress, efficiently rendering the high-dimensional features required for open-vocabulary queries poses a significant challenge. Existing methods employ codebooks or feature compression, causing information loss, thereby degrading segmentation quality. To address this limitation, we introduce Quantile Rendering (Q-Render), a novel rendering strategy for 3D Gaussians that efficiently handles high-dimensional features while maintaining high fidelity. Unlike conventional volume rendering, which densely samples all 3D Gaussians intersecting each ray, Q-Render sparsely samples only those with dominant influence along the ray. By integrating Q-Render into a generalizable 3D neural network, we also propose Gaussian Splatting Network (GS-Net), which predicts Gaussian features in a generalizable manner. Extensive experiments on ScanNet and LeRF demonstrate that our framework outperforms state-of-the-art methods, while enabling real-time rendering with an approximate ~43.7x speedup on 512-D feature maps. Code will be made publicly available.
LongSplat: Robust Unposed 3D Gaussian Splatting for Casual Long Videos
Aug 19, 2025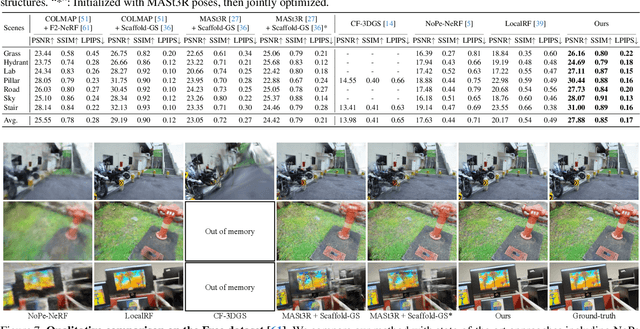
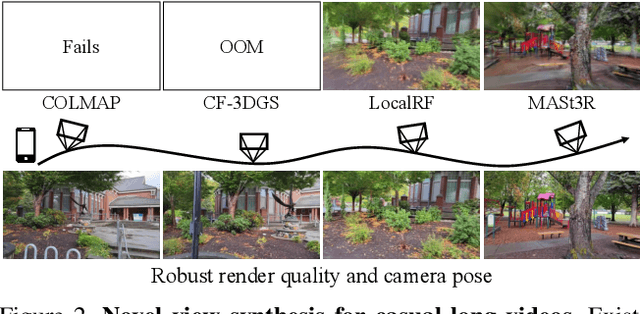
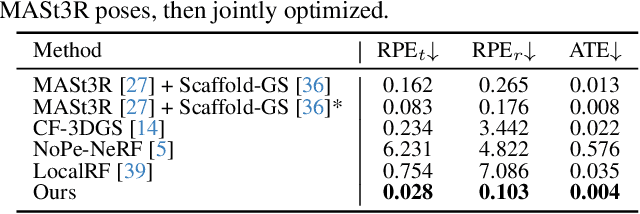
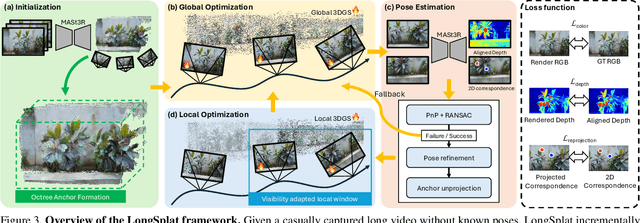
LongSplat addresses critical challenges in novel view synthesis (NVS) from casually captured long videos characterized by irregular camera motion, unknown camera poses, and expansive scenes. Current methods often suffer from pose drift, inaccurate geometry initialization, and severe memory limitations. To address these issues, we introduce LongSplat, a robust unposed 3D Gaussian Splatting framework featuring: (1) Incremental Joint Optimization that concurrently optimizes camera poses and 3D Gaussians to avoid local minima and ensure global consistency; (2) a robust Pose Estimation Module leveraging learned 3D priors; and (3) an efficient Octree Anchor Formation mechanism that converts dense point clouds into anchors based on spatial density. Extensive experiments on challenging benchmarks demonstrate that LongSplat achieves state-of-the-art results, substantially improving rendering quality, pose accuracy, and computational efficiency compared to prior approaches. Project page: https://linjohnss.github.io/longsplat/
BOFormer: Learning to Solve Multi-Objective Bayesian Optimization via Non-Markovian RL
May 29, 2025Bayesian optimization (BO) offers an efficient pipeline for optimizing black-box functions with the help of a Gaussian process prior and an acquisition function (AF). Recently, in the context of single-objective BO, learning-based AFs witnessed promising empirical results given its favorable non-myopic nature. Despite this, the direct extension of these approaches to multi-objective Bayesian optimization (MOBO) suffer from the \textit{hypervolume identifiability issue}, which results from the non-Markovian nature of MOBO problems. To tackle this, inspired by the non-Markovian RL literature and the success of Transformers in language modeling, we present a generalized deep Q-learning framework and propose \textit{BOFormer}, which substantiates this framework for MOBO via sequence modeling. Through extensive evaluation, we demonstrate that BOFormer constantly outperforms the benchmark rule-based and learning-based algorithms in various synthetic MOBO and real-world multi-objective hyperparameter optimization problems. We have made the source code publicly available to encourage further research in this direction.
Streamlining Biomedical Research with Specialized LLMs
Apr 15, 2025In this paper, we propose a novel system that integrates state-of-the-art, domain-specific large language models with advanced information retrieval techniques to deliver comprehensive and context-aware responses. Our approach facilitates seamless interaction among diverse components, enabling cross-validation of outputs to produce accurate, high-quality responses enriched with relevant data, images, tables, and other modalities. We demonstrate the system's capability to enhance response precision by leveraging a robust question-answering model, significantly improving the quality of dialogue generation. The system provides an accessible platform for real-time, high-fidelity interactions, allowing users to benefit from efficient human-computer interaction, precise retrieval, and simultaneous access to a wide range of literature and data. This dramatically improves the research efficiency of professionals in the biomedical and pharmaceutical domains and facilitates faster, more informed decision-making throughout the R\&D process. Furthermore, the system proposed in this paper is available at https://synapse-chat.patsnap.com.
Segment Anything, Even Occluded
Mar 08, 2025Amodal instance segmentation, which aims to detect and segment both visible and invisible parts of objects in images, plays a crucial role in various applications including autonomous driving, robotic manipulation, and scene understanding. While existing methods require training both front-end detectors and mask decoders jointly, this approach lacks flexibility and fails to leverage the strengths of pre-existing modal detectors. To address this limitation, we propose SAMEO, a novel framework that adapts the Segment Anything Model (SAM) as a versatile mask decoder capable of interfacing with various front-end detectors to enable mask prediction even for partially occluded objects. Acknowledging the constraints of limited amodal segmentation datasets, we introduce Amodal-LVIS, a large-scale synthetic dataset comprising 300K images derived from the modal LVIS and LVVIS datasets. This dataset significantly expands the training data available for amodal segmentation research. Our experimental results demonstrate that our approach, when trained on the newly extended dataset, including Amodal-LVIS, achieves remarkable zero-shot performance on both COCOA-cls and D2SA benchmarks, highlighting its potential for generalization to unseen scenarios.