 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3AM: 3egment Anything with Geometric Consistency in Videos
Jan 18, 2026Video object segmentation methods like SAM2 achieve strong performance through memory-based architectures but struggle under large viewpoint changes due to reliance on appearance features. Traditional 3D instance segmentation methods address viewpoint consistency but require camera poses, depth maps, and expensive preprocessing. We introduce 3AM, a training-time enhancement that integrates 3D-aware features from MUSt3R into SAM2. Our lightweight Feature Merger fuses multi-level MUSt3R features that encode implicit geometric correspondence. Combined with SAM2's appearance features, the model achieves geometry-consistent recognition grounded in both spatial position and visual similarity. We propose a field-of-view aware sampling strategy ensuring frames observe spatially consistent object regions for reliable 3D correspondence learning. Critically, our method requires only RGB input at inference, with no camera poses or preprocessing. On challenging datasets with wide-baseline motion (ScanNet++, Replica), 3AM substantially outperforms SAM2 and extensions, achieving 90.6% IoU and 71.7% Positive IoU on ScanNet++'s Selected Subset, improving over state-of-the-art VOS methods by +15.9 and +30.4 points. Project page: https://jayisaking.github.io/3AM-Page/
3AM: Segment Anything with Geometric Consistency in Videos
Jan 13, 2026Video object segmentation methods like SAM2 achieve strong performance through memory-based architectures but struggle under large viewpoint changes due to reliance on appearance features. Traditional 3D instance segmentation methods address viewpoint consistency but require camera poses, depth maps, and expensive preprocessing. We introduce 3AM, a training-time enhancement that integrates 3D-aware features from MUSt3R into SAM2. Our lightweight Feature Merger fuses multi-level MUSt3R features that encode implicit geometric correspondence. Combined with SAM2's appearance features, the model achieves geometry-consistent recognition grounded in both spatial position and visual similarity. We propose a field-of-view aware sampling strategy ensuring frames observe spatially consistent object regions for reliable 3D correspondence learning. Critically, our method requires only RGB input at inference, with no camera poses or preprocessing. On challenging datasets with wide-baseline motion (ScanNet++, Replica), 3AM substantially outperforms SAM2 and extensions, achieving 90.6% IoU and 71.7% Positive IoU on ScanNet++'s Selected Subset, improving over state-of-the-art VOS methods by +15.9 and +30.4 points. Project page: https://jayisaking.github.io/3AM-Page/
GaMO: Geometry-aware Multi-view Diffusion Outpainting for Sparse-View 3D Reconstruction
Dec 31, 2025Recent advances in 3D reconstruction have achieved remarkable progress in high-quality scene capture from dense multi-view imagery, yet struggle when input views are limited. Various approaches, including regularization techniques, semantic priors, and geometric constraints, have been implemented to address this challenge. Latest diffusion-based methods have demonstrated substantial improvements by generating novel views from new camera poses to augment training data, surpassing earlier regularization and prior-based techniques. Despite this progress, we identify three critical limitations in these state-of-the-art approaches: inadequate coverage beyond known view peripheries, geometric inconsistencies across generated views, and computationally expensive pipelines. We introduce GaMO (Geometry-aware Multi-view Outpainter), a framework that reformulates sparse-view reconstruction through multi-view outpainting. Instead of generating new viewpoints, GaMO expands the field of view from existing camera poses, which inherently preserves geometric consistency while providing broader scene coverage. Our approach employs multi-view conditioning and geometry-aware denoising strategies in a zero-shot manner without training. Extensive experiments on Replica and ScanNet++ demonstrate state-of-the-art reconstruction quality across 3, 6, and 9 input views, outperforming prior methods in PSNR and LPIPS, while achieving a $25\times$ speedup over SOTA diffusion-based methods with processing time under 10 minutes. Project page: https://yichuanh.github.io/GaMO/
Stream-DiffVSR: Low-Latency Streamable Video Super-Resolution via Auto-Regressive Diffusion
Dec 29, 2025Diffusion-based video super-resolution (VSR) methods achieve strong perceptual quality but remain impractical for latency-sensitive settings due to reliance on future frames and expensive multi-step denoising. We propose Stream-DiffVSR, a causally conditioned diffusion framework for efficient online VSR. Operating strictly on past frames, it combines a four-step distilled denoiser for fast inference, an Auto-regressive Temporal Guidance (ARTG) module that injects motion-aligned cues during latent denoising, and a lightweight temporal-aware decoder with a Temporal Processor Module (TPM) that enhances detail and temporal coherence. Stream-DiffVSR processes 720p frames in 0.328 seconds on an RTX4090 GPU and significantly outperforms prior diffusion-based methods. Compared with the online SOTA TMP, it boosts perceptual quality (LPIPS +0.095) while reducing latency by over 130x. Stream-DiffVSR achieves the lowest latency reported for diffusion-based VSR, reducing initial delay from over 4600 seconds to 0.328 seconds, thereby making it the first diffusion VSR method suitable for low-latency online deployment. Project page: https://jamichss.github.io/stream-diffvsr-project-page/
See, Point, Fly: A Learning-Free VLM Framework for Universal Unmanned Aerial Navigation
Sep 26, 2025



We present See, Point, Fly (SPF), a training-free aerial vision-and-language navigation (AVLN) framework built atop vision-language models (VLMs). SPF is capable of navigating to any goal based on any type of free-form instructions in any kind of environment. In contrast to existing VLM-based approaches that treat action prediction as a text generation task, our key insight is to consider action prediction for AVLN as a 2D spatial grounding task. SPF harnesses VLMs to decompose vague language instructions into iterative annotation of 2D waypoints on the input image. Along with the predicted traveling distance, SPF transforms predicted 2D waypoints into 3D displacement vectors as action commands for UAVs. Moreover, SPF also adaptively adjusts the traveling distance to facilitate more efficient navigation. Notably, SPF performs navigation in a closed-loop control manner, enabling UAVs to follow dynamic targets in dynamic environments. SPF sets a new state of the art in DRL simulation benchmark, outperforming the previous best method by an absolute margin of 63%. In extensive real-world evaluations, SPF outperforms strong baselines by a large margin. We also conduct comprehensive ablation studies to highlight the effectiveness of our design choice. Lastly, SPF shows remarkable generalization to different VLMs. Project page: https://spf-web.pages.dev
LongSplat: Robust Unposed 3D Gaussian Splatting for Casual Long Videos
Aug 19, 2025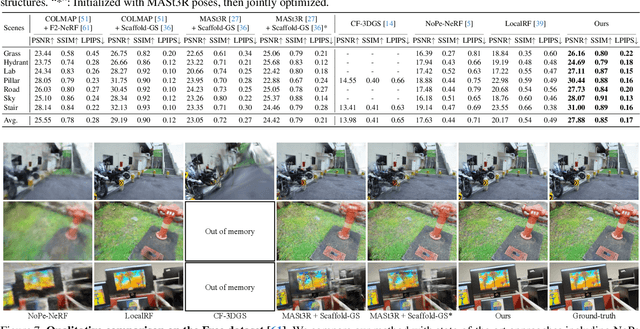
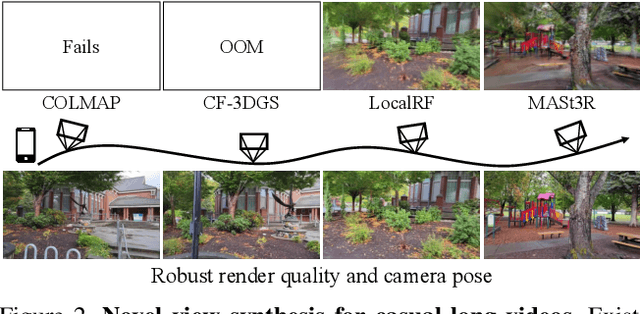
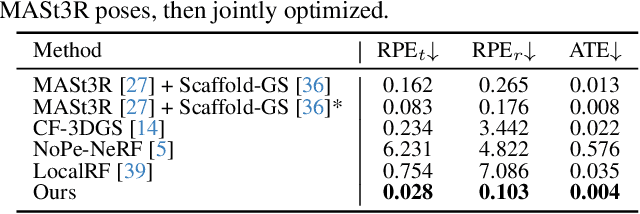
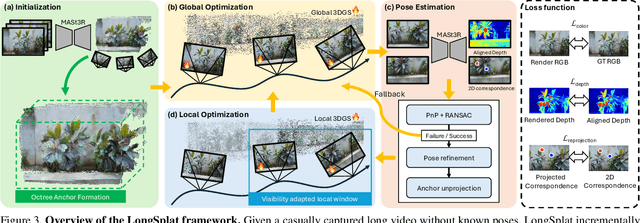
LongSplat addresses critical challenges in novel view synthesis (NVS) from casually captured long videos characterized by irregular camera motion, unknown camera poses, and expansive scenes. Current methods often suffer from pose drift, inaccurate geometry initialization, and severe memory limitations. To address these issues, we introduce LongSplat, a robust unposed 3D Gaussian Splatting framework featuring: (1) Incremental Joint Optimization that concurrently optimizes camera poses and 3D Gaussians to avoid local minima and ensure global consistency; (2) a robust Pose Estimation Module leveraging learned 3D priors; and (3) an efficient Octree Anchor Formation mechanism that converts dense point clouds into anchors based on spatial density. Extensive experiments on challenging benchmarks demonstrate that LongSplat achieves state-of-the-art results, substantially improving rendering quality, pose accuracy, and computational efficiency compared to prior approaches. Project page: https://linjohnss.github.io/longsplat/
AuraFusion360: Augmented Unseen Region Alignment for Reference-based 360° Unbounded Scene Inpainting
Feb 07, 2025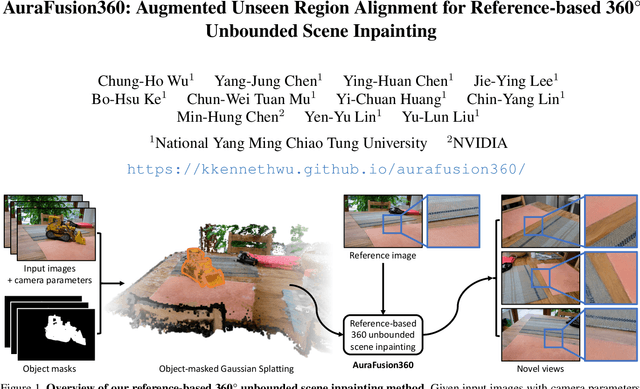
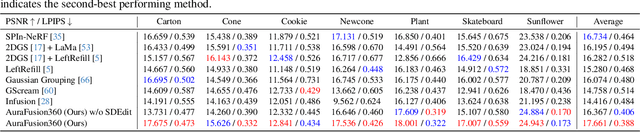

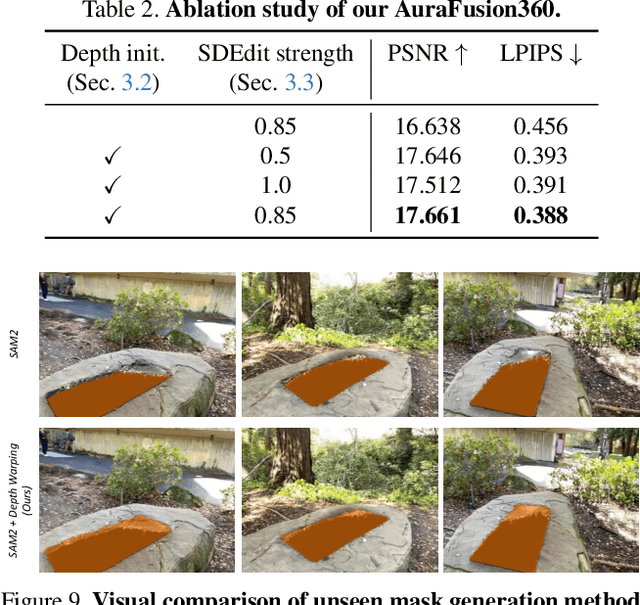
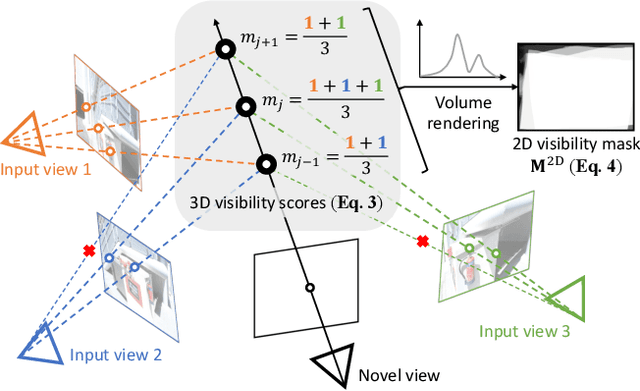
Three-dimensional scene inpainting is crucial for applications from virtual reality to architectural visualization, yet existing methods struggle with view consistency and geometric accuracy in 360{\deg} unbounded scenes. We present AuraFusion360, a novel reference-based method that enables high-quality object removal and hole filling in 3D scenes represented by Gaussian Splatting. Our approach introduces (1) depth-aware unseen mask generation for accurate occlusion identification, (2) Adaptive Guided Depth Diffusion, a zero-shot method for accurate initial point placement without requiring additional training, and (3) SDEdit-based detail enhancement for multi-view coherence. We also introduce 360-USID, the first comprehensive dataset for 360{\deg} unbounded scene inpainting with ground truth. Extensive experiments demonstrate that AuraFusion360 significantly outperforms existing methods, achieving superior perceptual quality while maintaining geometric accuracy across dramatic viewpoint changes. See our project page for video results and the dataset at https://kkennethwu.github.io/aurafusion360/.
FrugalNeRF: Fast Convergence for Few-shot Novel View Synthesis without Learned Priors
Oct 21, 2024Neural Radiance Fields (NeRF) face significant challenges in few-shot scenarios, primarily due to overfitting and long training times for high-fidelity rendering. Existing methods, such as FreeNeRF and SparseNeRF, use frequency regularization or pre-trained priors but struggle with complex scheduling and bias. We introduce FrugalNeRF, a novel few-shot NeRF framework that leverages weight-sharing voxels across multiple scales to efficiently represent scene details. Our key contribution is a cross-scale geometric adaptation scheme that selects pseudo ground truth depth based on reprojection errors across scales. This guides training without relying on externally learned priors, enabling full utilization of the training data. It can also integrate pre-trained priors, enhancing quality without slowing convergence. Experiments on LLFF, DTU, and RealEstate-10K show that FrugalNeRF outperforms other few-shot NeRF methods while significantly reducing training time, making it a practical solution for efficient and accurate 3D scene reconstruction.
BoostMVSNeRFs: Boosting MVS-based NeRFs to Generalizable View Synthesis in Large-scale Scenes
Jul 22, 2024


While Neural Radiance Fields (NeRFs) have demonstrated exceptional quality, their protracted training duration remains a limitation. Generalizable and MVS-based NeRFs, although capable of mitigating training time, often incur tradeoffs in quality. This paper presents a novel approach called BoostMVSNeRFs to enhance the rendering quality of MVS-based NeRFs in large-scale scenes. We first identify limitations in MVS-based NeRF methods, such as restricted viewport coverage and artifacts due to limited input views. Then, we address these limitations by proposing a new method that selects and combines multiple cost volumes during volume rendering. Our method does not require training and can adapt to any MVS-based NeRF methods in a feed-forward fashion to improve rendering quality. Furthermore, our approach is also end-to-end trainable, allowing fine-tuning on specific scenes. We demonstrate the effectiveness of our method through experiments on large-scale datasets, showing significant rendering quality improvements in large-scale scenes and unbounded outdoor scenarios. We release the source code of BoostMVSNeRFs at https://su-terry.github.io/BoostMVSNeRFs/.
DiffIR2VR-Zero: Zero-Shot Video Restoration with Diffusion-based Image Restoration Models
Jul 01, 2024This paper introduces a method for zero-shot video restoration using pre-trained image restoration diffusion models. Traditional video restoration methods often need retraining for different settings and struggle with limited generalization across various degradation types and datasets. Our approach uses a hierarchical token merging strategy for keyframes and local frames, combined with a hybrid correspondence mechanism that blends optical flow and feature-based nearest neighbor matching (latent merging). We show that our method not only achieves top performance in zero-shot video restoration but also significantly surpasses trained models in generalization across diverse datasets and extreme degradations (8$\times$ super-resolution and high-standard deviation video denoising). We present evidence through quantitative metrics and visual comparisons on various challenging datasets. Additionally, our technique works with any 2D restoration diffusion model, offering a versatile and powerful tool for video enhancement tasks without extensive retraining. This research leads to more efficient and widely applicable video restoration technologies, supporting advancements in fields that require high-quality video output. See our project page for video results at https://jimmycv07.github.io/DiffIR2VR_web/.