 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaMO: Geometry-aware Multi-view Diffusion Outpainting for Sparse-View 3D Reconstruction
Dec 31, 2025Recent advances in 3D reconstruction have achieved remarkable progress in high-quality scene capture from dense multi-view imagery, yet struggle when input views are limited. Various approaches, including regularization techniques, semantic priors, and geometric constraints, have been implemented to address this challenge. Latest diffusion-based methods have demonstrated substantial improvements by generating novel views from new camera poses to augment training data, surpassing earlier regularization and prior-based techniques. Despite this progress, we identify three critical limitations in these state-of-the-art approaches: inadequate coverage beyond known view peripheries, geometric inconsistencies across generated views, and computationally expensive pipelines. We introduce GaMO (Geometry-aware Multi-view Outpainter), a framework that reformulates sparse-view reconstruction through multi-view outpainting. Instead of generating new viewpoints, GaMO expands the field of view from existing camera poses, which inherently preserves geometric consistency while providing broader scene coverage. Our approach employs multi-view conditioning and geometry-aware denoising strategies in a zero-shot manner without training. Extensive experiments on Replica and ScanNet++ demonstrate state-of-the-art reconstruction quality across 3, 6, and 9 input views, outperforming prior methods in PSNR and LPIPS, while achieving a $25\times$ speedup over SOTA diffusion-based methods with processing time under 10 minutes. Project page: https://yichuanh.github.io/GaMO/
Prior-Enhanced Gaussian Splatting for Dynamic Scene Reconstruction from Casual Video
Dec 12, 2025We introduce a fully automatic pipeline for dynamic scene reconstruction from casually captured monocular RGB videos. Rather than designing a new scene representation, we enhance the priors that drive Dynamic Gaussian Splatting. Video segmentation combined with epipolar-error maps yields object-level masks that closely follow thin structures; these masks (i) guide an object-depth loss that sharpens the consistent video depth, and (ii) support skeleton-based sampling plus mask-guided re-identification to produce reliable, comprehensive 2-D tracks. Two additional objectives embed the refined priors in the reconstruction stage: a virtual-view depth loss removes floaters, and a scaffold-projection loss ties motion nodes to the tracks, preserving fine geometry and coherent motion. The resulting system surpasses previous monocular dynamic scene reconstruction methods and delivers visibly superior renderings
AuraFusion360: Augmented Unseen Region Alignment for Reference-based 360° Unbounded Scene Inpainting
Feb 07, 2025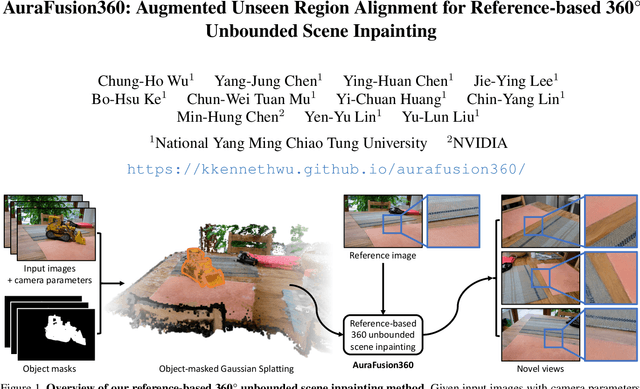
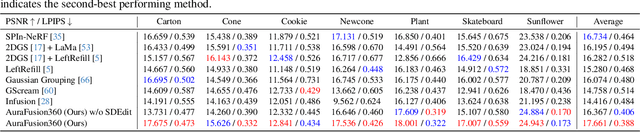

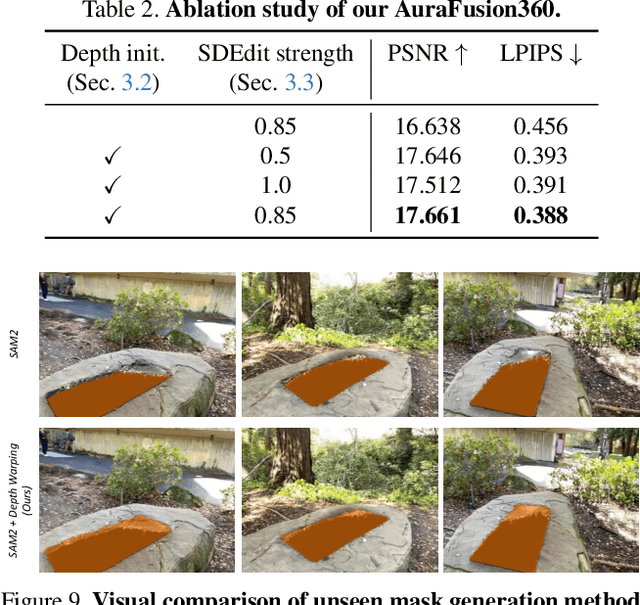
Three-dimensional scene inpainting is crucial for applications from virtual reality to architectural visualization, yet existing methods struggle with view consistency and geometric accuracy in 360{\deg} unbounded scenes. We present AuraFusion360, a novel reference-based method that enables high-quality object removal and hole filling in 3D scenes represented by Gaussian Splatting. Our approach introduces (1) depth-aware unseen mask generation for accurate occlusion identification, (2) Adaptive Guided Depth Diffusion, a zero-shot method for accurate initial point placement without requiring additional training, and (3) SDEdit-based detail enhancement for multi-view coherence. We also introduce 360-USID, the first comprehensive dataset for 360{\deg} unbounded scene inpainting with ground truth. Extensive experiments demonstrate that AuraFusion360 significantly outperforms existing methods, achieving superior perceptual quality while maintaining geometric accuracy across dramatic viewpoint changes. See our project page for video results and the dataset at https://kkennethwu.github.io/aurafusion360/.