 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-Enhanced Gaussian Splatting for Dynamic Scene Reconstruction from Casual Video
Dec 12, 2025We introduce a fully automatic pipeline for dynamic scene reconstruction from casually captured monocular RGB videos. Rather than designing a new scene representation, we enhance the priors that drive Dynamic Gaussian Splatting. Video segmentation combined with epipolar-error maps yields object-level masks that closely follow thin structures; these masks (i) guide an object-depth loss that sharpens the consistent video depth, and (ii) support skeleton-based sampling plus mask-guided re-identification to produce reliable, comprehensive 2-D tracks. Two additional objectives embed the refined priors in the reconstruction stage: a virtual-view depth loss removes floaters, and a scaffold-projection loss ties motion nodes to the tracks, preserving fine geometry and coherent motion. The resulting system surpasses previous monocular dynamic scene reconstruction methods and delivers visibly superior renderings
UltraZoom: Generating Gigapixel Images from Regular Photos
Jun 16, 2025We present UltraZoom, a system for generating gigapixel-resolution images of objects from casually captured inputs, such as handheld phone photos. Given a full-shot image (global, low-detail) and one or more close-ups (local, high-detail), UltraZoom upscales the full image to match the fine detail and scale of the close-up examples. To achieve this, we construct a per-instance paired dataset from the close-ups and adapt a pretrained generative model to learn object-specific low-to-high resolution mappings. At inference, we apply the model in a sliding window fashion over the full image. Constructing these pairs is non-trivial: it requires registering the close-ups within the full image for scale estimation and degradation alignment. We introduce a simple, robust method for getting registration on arbitrary materials in casual, in-the-wild captures. Together, these components form a system that enables seamless pan and zoom across the entire object, producing consistent, photorealistic gigapixel imagery from minimal input.
Generating Fit Check Videos with a Handheld Camera
May 29, 2025Self-captured full-body videos are popular, but most deployments require mounted cameras, carefully-framed shots, and repeated practice. We propose a more convenient solution that enables full-body video capture using handheld mobile devices. Our approach takes as input two static photos (front and back) of you in a mirror, along with an IMU motion reference that you perform while holding your mobile phone, and synthesizes a realistic video of you performing a similar target motion. We enable rendering into a new scene, with consistent illumination and shadows. We propose a novel video diffusion-based model to achieve this. Specifically, we propose a parameter-free frame generation strategy, as well as a multi-reference attention mechanism, that effectively integrate appearance information from both the front and back selfies into the video diffusion model. Additionally, we introduce an image-based fine-tuning strategy to enhance frame sharpness and improve the generation of shadows and reflections, achieving a more realistic human-scene composition.
How Animals Dance (When You're Not Looking)
May 29, 2025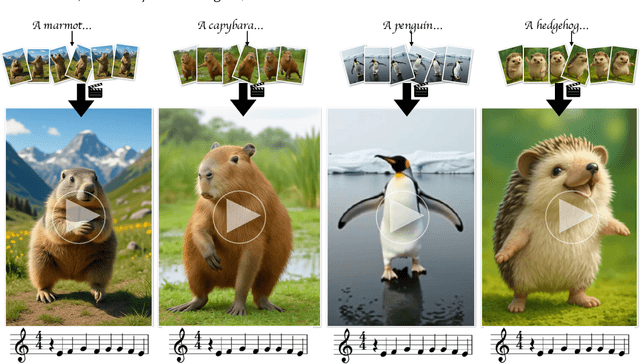
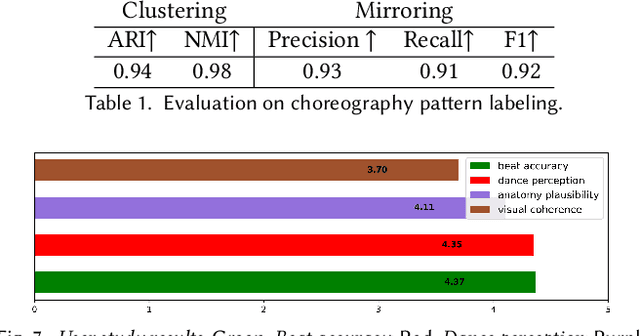

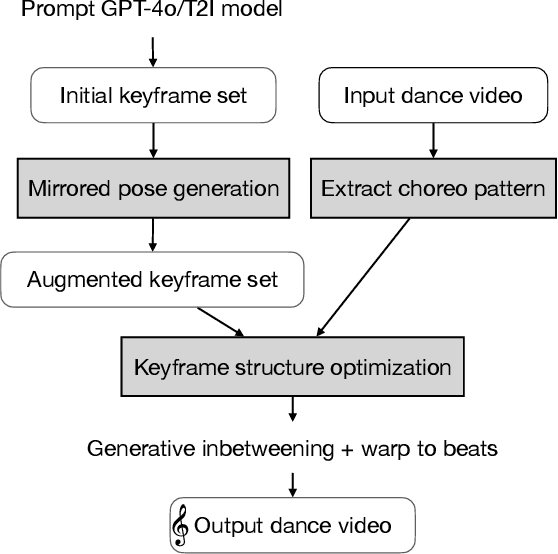
We present a keyframe-based framework for generating music-synchronized, choreography aware animal dance videos. Starting from a few keyframes representing distinct animal poses -- generated via text-to-image prompting or GPT-4o -- we formulate dance synthesis as a graph optimization problem: find the optimal keyframe structure that satisfies a specified choreography pattern of beats, which can be automatically estimated from a reference dance video. We also introduce an approach for mirrored pose image generation, essential for capturing symmetry in dance. In-between frames are synthesized using an video diffusion model. With as few as six input keyframes, our method can produce up to 30 second dance videos across a wide range of animals and music tracks.
View2CAD: Reconstructing View-Centric CAD Models from Single RGB-D Scans
Apr 05, 2025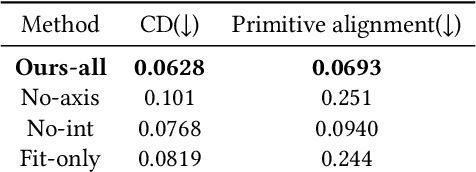
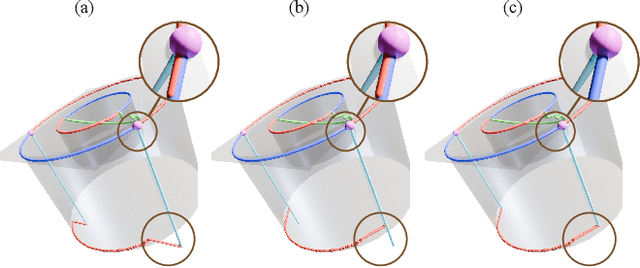

Parametric CAD models, represented as Boundary Representations (B-reps), are foundational to modern design and manufacturing workflows, offering the precision and topological breakdown required for downstream tasks such as analysis, editing, and fabrication. However, B-Reps are often inaccessible due to conversion to more standardized, less expressive geometry formats. Existing methods to recover B-Reps from measured data require complete, noise-free 3D data, which are laborious to obtain. We alleviate this difficulty by enabling the precise reconstruction of CAD shapes from a single RGB-D image. We propose a method that addresses the challenge of reconstructing only the observed geometry from a single view. To allow for these partial observations, and to avoid hallucinating incorrect geometry, we introduce a novel view-centric B-rep (VB-Rep) representation, which incorporates structures to handle visibility limits and encode geometric uncertainty. We combine panoptic image segmentation with iterative geometric optimization to refine and improve the reconstruction process. Our results demonstrate high-quality reconstruction on synthetic and real RGB-D data, showing that our method can bridge the reality gap.
MusicInfuser: Making Video Diffusion Listen and Dance
Mar 18, 2025We introduce MusicInfuser, an approach for generating high-quality dance videos that are synchronized to a specified music track. Rather than attempting to design and train a new multimodal audio-video model, we show how existing video diffusion models can be adapted to align with musical inputs by introducing lightweight music-video cross-attention and a low-rank adapter. Unlike prior work requiring motion capture data, our approach fine-tunes only on dance videos. MusicInfuser achieves high-quality music-driven video generation while preserving the flexibility and generative capabilities of the underlying models. We introduce an evaluation framework using Video-LLMs to assess multiple dimensions of dance generation quality. The project page and code are available at https://susunghong.github.io/MusicInfuser.
VidPanos: Generative Panoramic Videos from Casual Panning Videos
Oct 17, 2024
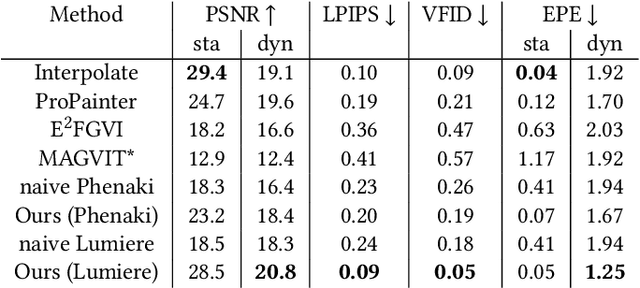
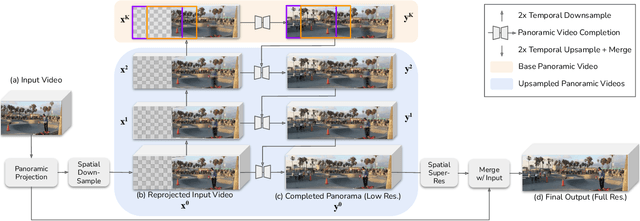
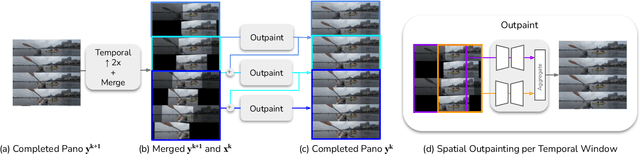
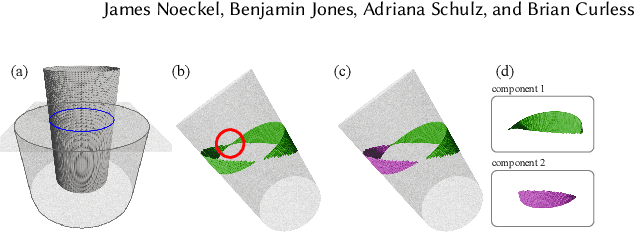
Panoramic image stitching provides a unified, wide-angle view of a scene that extends beyond the camera's field of view. Stitching frames of a panning video into a panoramic photograph is a well-understood problem for stationary scenes, but when objects are moving, a still panorama cannot capture the scene. We present a method for synthesizing a panoramic video from a casually-captured panning video, as if the original video were captured with a wide-angle camera. We pose panorama synthesis as a space-time outpainting problem, where we aim to create a full panoramic video of the same length as the input video. Consistent completion of the space-time volume requires a powerful, realistic prior over video content and motion, for which we adapt generative video models. Existing generative models do not, however, immediately extend to panorama completion, as we show. We instead apply video generation as a component of our panorama synthesis system, and demonstrate how to exploit the strengths of the models while minimizing their limitations. Our system can create video panoramas for a range of in-the-wild scenes including people, vehicles, and flowing water, as well as stationary background features.
Inverse Painting: Reconstructing The Painting Process
Sep 30, 2024
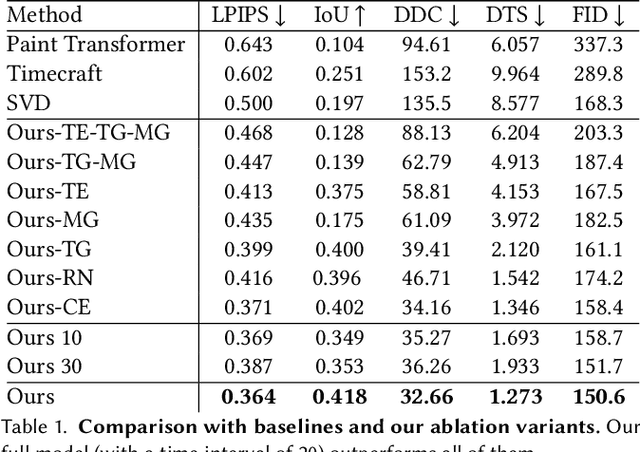

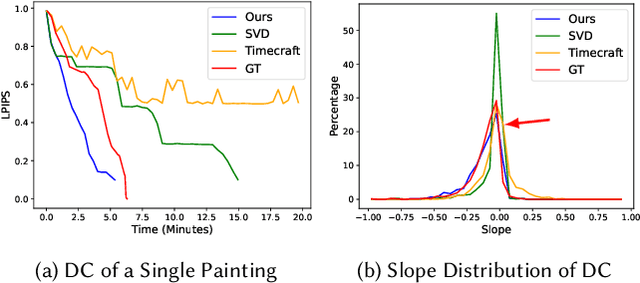
Given an input painting, we reconstruct a time-lapse video of how it may have been painted. We formulate this as an autoregressive image generation problem, in which an initially blank "canvas" is iteratively updated. The model learns from real artists by training on many painting videos. Our approach incorporates text and region understanding to define a set of painting "instructions" and updates the canvas with a novel diffusion-based renderer. The method extrapolates beyond the limited, acrylic style paintings on which it has been trained, showing plausible results for a wide range of artistic styles and genres.
Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation
Aug 27, 2024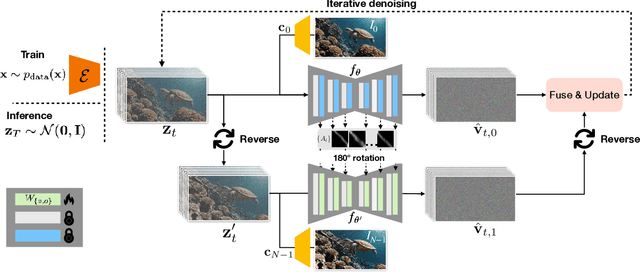
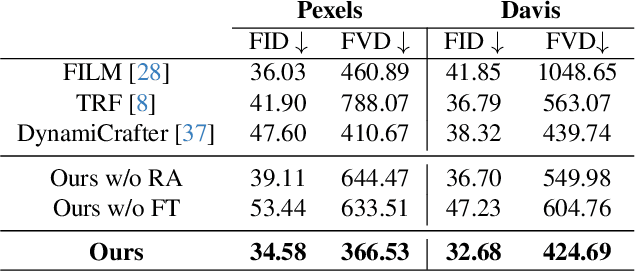
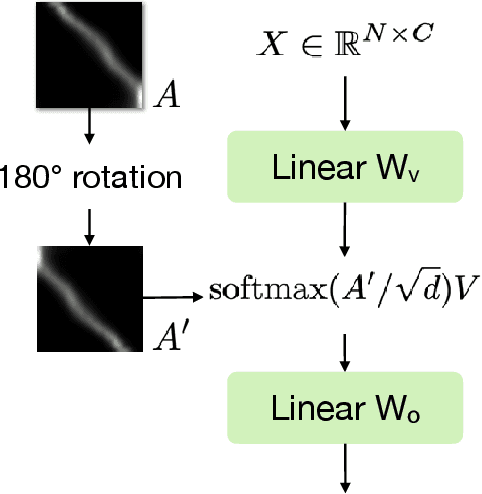

We present a method for generating video sequences with coherent motion between a pair of input key frames. We adapt a pretrained large-scale image-to-video diffusion model (originally trained to generate videos moving forward in time from a single input image) for key frame interpolation, i.e., to produce a video in between two input frames. We accomplish this adaptation through a lightweight fine-tuning technique that produces a version of the model that instead predicts videos moving backwards in time from a single input image. This model (along with the original forward-moving model) is subsequently used in a dual-directional diffusion sampling process that combines the overlapping model estimates starting from each of the two keyframes. Our experiments show that our method outperforms both existing diffusion-based methods and traditional frame interpolation techniques.
Don't Look at the Camera: Achieving Perceived Eye Contact
Apr 26, 2024



We consider the question of how to best achieve the perception of eye contact when a person is captured by camera and then rendered on a 2D display. For single subjects photographed by a camera, conventional wisdom tells us that looking directly into the camera achieves eye contact. Through empirical user studies, we show that it is instead preferable to {\em look just below the camera lens}. We quantitatively assess where subjects should direct their gaze relative to a camera lens to optimize the perception that they are making eye contact.