 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure From Tracking: Distilling Structure-Preserving Motion for Video Generation
Dec 12, 2025
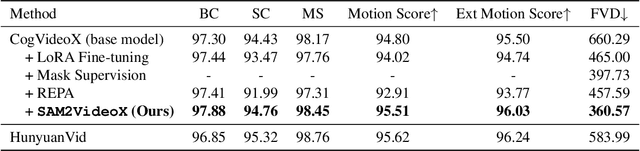
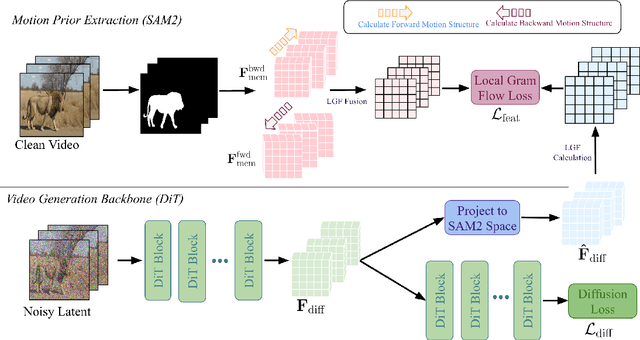
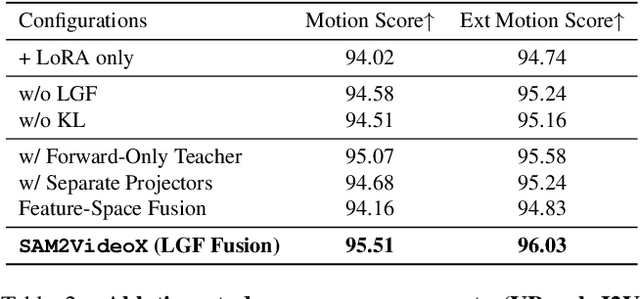
Reality is a dance between rigid constraints and deformable structures. For video models, that means generating motion that preserves fidelity as well as structure. Despite progress in diffusion models, producing realistic structure-preserving motion remains challenging, especially for articulated and deformable objects such as humans and animals. Scaling training data alone, so far, has failed to resolve physically implausible transitions. Existing approaches rely on conditioning with noisy motion representations, such as optical flow or skeletons extracted using an external imperfect model. To address these challenges, we introduce an algorithm to distill structure-preserving motion priors from an autoregressive video tracking model (SAM2) into a bidirectional video diffusion model (CogVideoX). With our method, we train SAM2VideoX, which contains two innovations: (1) a bidirectional feature fusion module that extracts global structure-preserving motion priors from a recurrent model like SAM2; (2) a Local Gram Flow loss that aligns how local features move together. Experiments on VBench and in human studies show that SAM2VideoX delivers consistent gains (+2.60\% on VBench, 21-22\% lower FVD, and 71.4\% human preference) over prior baselines. Specifically, on VBench, we achieve 95.51\%, surpassing REPA (92.91\%) by 2.60\%, and reduce FVD to 360.57, a 21.20\% and 22.46\% improvement over REPA- and LoRA-finetuning, respectively. The project website can be found at https://sam2videox.github.io/ .
How Animals Dance (When You're Not Looking)
May 29, 2025
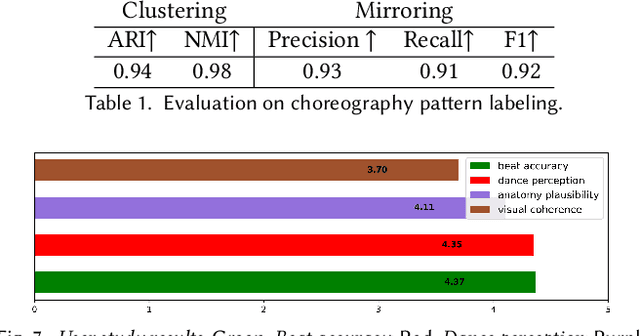

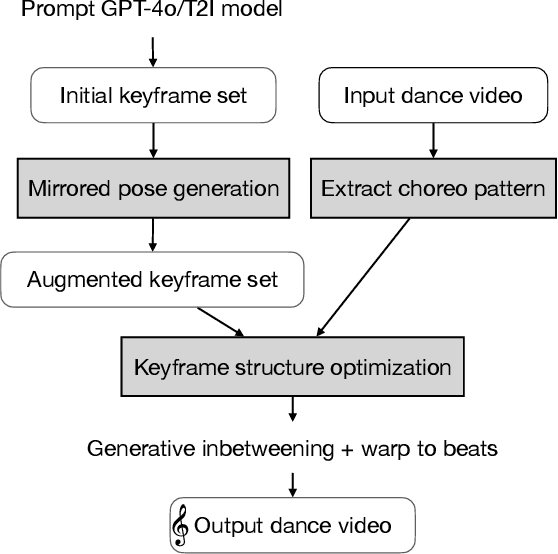
We present a keyframe-based framework for generating music-synchronized, choreography aware animal dance videos. Starting from a few keyframes representing distinct animal poses -- generated via text-to-image prompting or GPT-4o -- we formulate dance synthesis as a graph optimization problem: find the optimal keyframe structure that satisfies a specified choreography pattern of beats, which can be automatically estimated from a reference dance video. We also introduce an approach for mirrored pose image generation, essential for capturing symmetry in dance. In-between frames are synthesized using an video diffusion model. With as few as six input keyframes, our method can produce up to 30 second dance videos across a wide range of animals and music tracks.
Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation
Aug 27, 2024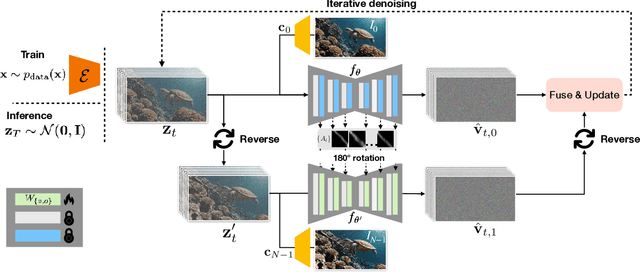
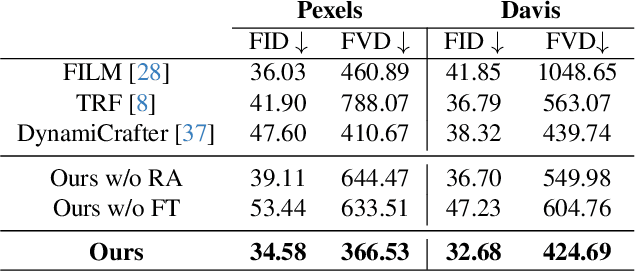

We present a method for generating video sequences with coherent motion between a pair of input key frames. We adapt a pretrained large-scale image-to-video diffusion model (originally trained to generate videos moving forward in time from a single input image) for key frame interpolation, i.e., to produce a video in between two input frames. We accomplish this adaptation through a lightweight fine-tuning technique that produces a version of the model that instead predicts videos moving backwards in time from a single input image. This model (along with the original forward-moving model) is subsequently used in a dual-directional diffusion sampling process that combines the overlapping model estimates starting from each of the two keyframes. Our experiments show that our method outperforms both existing diffusion-based methods and traditional frame interpolation techniques.
Jump Cut Smoothing for Talking Heads
Jan 11, 2024



A jump cut offers an abrupt, sometimes unwanted change in the viewing experience. We present a novel framework for smoothing these jump cuts, in the context of talking head videos. We leverage the appearance of the subject from the other source frames in the video, fusing it with a mid-level representation driven by DensePose keypoints and face landmarks. To achieve motion, we interpolate the keypoints and landmarks between the end frames around the cut. We then use an image translation network from the keypoints and source frames, to synthesize pixels. Because keypoints can contain errors, we propose a cross-modal attention scheme to select and pick the most appropriate source amongst multiple options for each key point. By leveraging this mid-level representation, our method can achieve stronger results than a strong video interpolation baseline. We demonstrate our method on various jump cuts in the talking head videos, such as cutting filler words, pauses, and even random cuts. Our experiments show that we can achieve seamless transitions, even in the challenging cases where the talking head rotates or moves drastically in the jump cut.
Generative Powers of Ten
Dec 04, 2023We present a method that uses a text-to-image model to generate consistent content across multiple image scales, enabling extreme semantic zooms into a scene, e.g., ranging from a wide-angle landscape view of a forest to a macro shot of an insect sitting on one of the tree branches. We achieve this through a joint multi-scale diffusion sampling approach that encourages consistency across different scales while preserving the integrity of each individual sampling process. Since each generated scale is guided by a different text prompt, our method enables deeper levels of zoom than traditional super-resolution methods that may struggle to create new contextual structure at vastly different scales. We compare our method qualitatively with alternative techniques in image super-resolution and outpainting, and show that our method is most effective at generating consistent multi-scale content.
QueryPose: Sparse Multi-Person Pose Regression via Spatial-Aware Part-Level Query
Dec 15, 2022



We propose a sparse end-to-end multi-person pose regression framework, termed QueryPose, which can directly predict multi-person keypoint sequences from the input image. The existing end-to-end methods rely on dense representations to preserve the spatial detail and structure for precise keypoint localization. However, the dense paradigm introduces complex and redundant post-processes during inference. In our framework, each human instance is encoded by several learnable spatial-aware part-level queries associated with an instance-level query. First, we propose the Spatial Part Embedding Generation Module (SPEGM) that considers the local spatial attention mechanism to generate several spatial-sensitive part embeddings, which contain spatial details and structural information for enhancing the part-level queries. Second, we introduce the Selective Iteration Module (SIM) to adaptively update the sparse part-level queries via the generated spatial-sensitive part embeddings stage-by-stage. Based on the two proposed modules, the part-level queries are able to fully encode the spatial details and structural information for precise keypoint regression. With the bipartite matching, QueryPose avoids the hand-designed post-processes and surpasses the existing dense end-to-end methods with 73.6 AP on MS COCO mini-val set and 72.7 AP on CrowdPose test set. Code is available at https://github.com/buptxyb666/QueryPose.
AdaptivePose++: A Powerful Single-Stage Network for Multi-Person Pose Regression
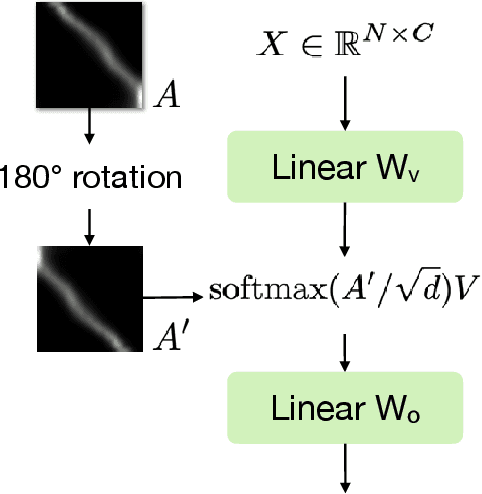
Oct 08, 2022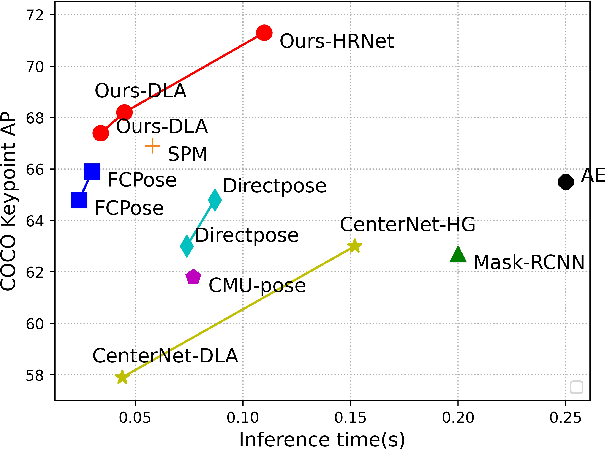

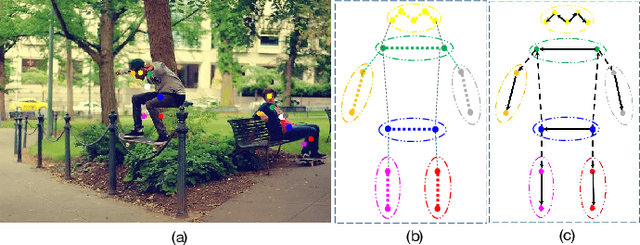
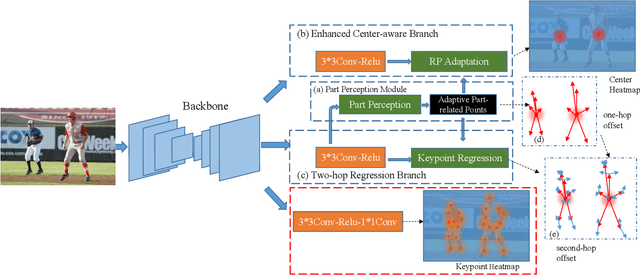
Multi-person pose estimation generally follows top-down and bottom-up paradigms. Both of them use an extra stage ($\boldsymbol{e.g.,}$ human detection in top-down paradigm or grouping process in bottom-up paradigm) to build the relationship between the human instance and corresponding keypoints, thus leading to the high computation cost and redundant two-stage pipeline. To address the above issue, we propose to represent the human parts as adaptive points and introduce a fine-grained body representation method. The novel body representation is able to sufficiently encode the diverse pose information and effectively model the relationship between the human instance and corresponding keypoints in a single-forward pass. With the proposed body representation, we further deliver a compact single-stage multi-person pose regression network, termed as AdaptivePose. During inference, our proposed network only needs a single-step decode operation to form the multi-person pose without complex post-processes and refinements. We employ AdaptivePose for both 2D/3D multi-person pose estimation tasks to verify the effectiveness of AdaptivePose. Without any bells and whistles, we achieve the most competitive performance on MS COCO and CrowdPose in terms of accuracy and speed. Furthermore, the outstanding performance on MuCo-3DHP and MuPoTS-3D further demonstrates the effectiveness and generalizability on 3D scenes. Code is available at https://github.com/buptxyb666/AdaptivePose.
Learning Quality-aware Representation for Multi-person Pose Regression
Jan 04, 2022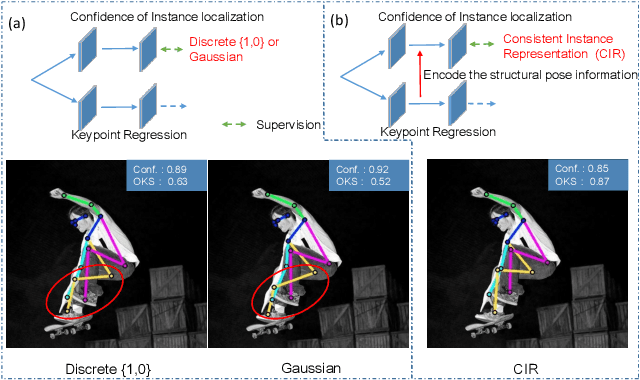

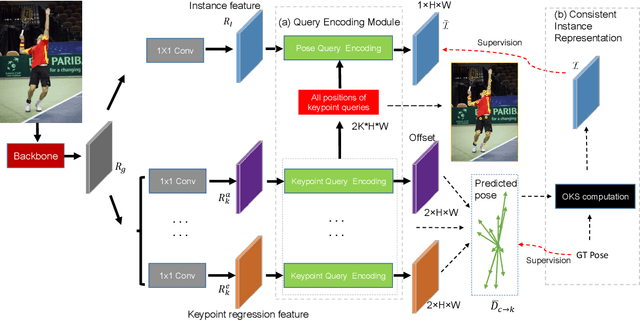
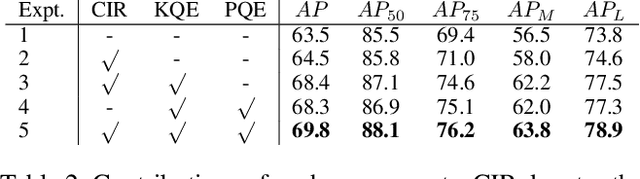
Off-the-shelf single-stage multi-person pose regression methods generally leverage the instance score (i.e., confidence of the instance localization) to indicate the pose quality for selecting the pose candidates. We consider that there are two gaps involved in existing paradigm:~1) The instance score is not well interrelated with the pose regression quality.~2) The instance feature representation, which is used for predicting the instance score, does not explicitly encode the structural pose information to predict the reasonable score that represents pose regression quality. To address the aforementioned issues, we propose to learn the pose regression quality-aware representation. Concretely, for the first gap, instead of using the previous instance confidence label (e.g., discrete {1,0} or Gaussian representation) to denote the position and confidence for person instance, we firstly introduce the Consistent Instance Representation (CIR) that unifies the pose regression quality score of instance and the confidence of background into a pixel-wise score map to calibrates the inconsistency between instance score and pose regression quality. To fill the second gap, we further present the Query Encoding Module (QEM) including the Keypoint Query Encoding (KQE) to encode the positional and semantic information for each keypoint and the Pose Query Encoding (PQE) which explicitly encodes the predicted structural pose information to better fit the Consistent Instance Representation (CIR). By using the proposed components, we significantly alleviate the above gaps. Our method outperforms previous single-stage regression-based even bottom-up methods and achieves the state-of-the-art result of 71.7 AP on MS COCO test-dev set.
AdaptivePose: Human Parts as Adaptive Points
Dec 27, 2021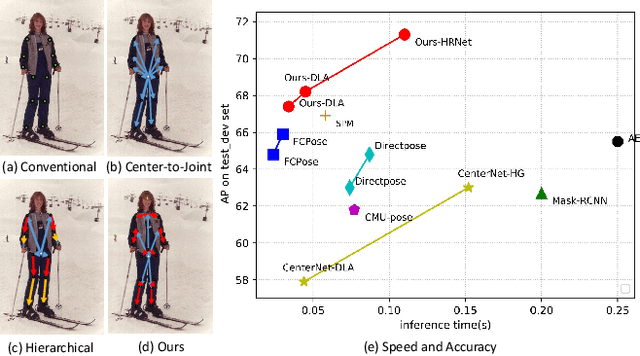
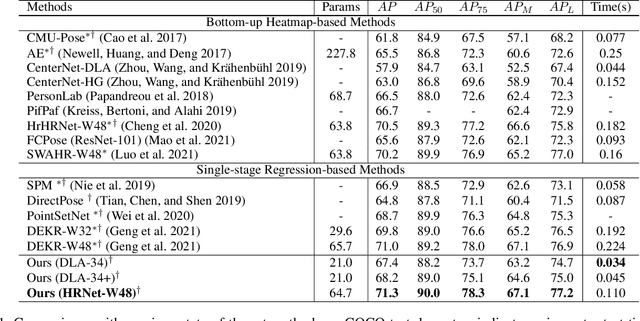
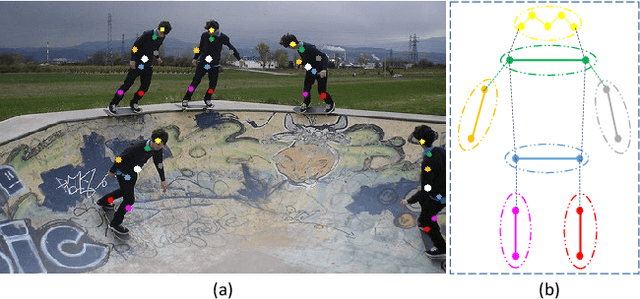
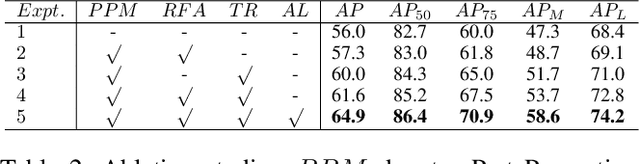
Multi-person pose estimation methods generally follow top-down and bottom-up paradigms, both of which can be considered as two-stage approaches thus leading to the high computation cost and low efficiency. Towards a compact and efficient pipeline for multi-person pose estimation task, in this paper, we propose to represent the human parts as points and present a novel body representation, which leverages an adaptive point set including the human center and seven human-part related points to represent the human instance in a more fine-grained manner. The novel representation is more capable of capturing the various pose deformation and adaptively factorizes the long-range center-to-joint displacement thus delivers a single-stage differentiable network to more precisely regress multi-person pose, termed as AdaptivePose. For inference, our proposed network eliminates the grouping as well as refinements and only needs a single-step disentangling process to form multi-person pose. Without any bells and whistles, we achieve the best speed-accuracy trade-offs of 67.4% AP / 29.4 fps with DLA-34 and 71.3% AP / 9.1 fps with HRNet-W48 on COCO test-dev dataset.
The 2nd Anti-UAV Workshop & Challenge: Methods and Results
Aug 25, 2021

The 2nd Anti-UAV Workshop \& Challenge aims to encourage research in developing novel and accurate methods for multi-scale object tracking. The Anti-UAV dataset used for the Anti-UAV Challenge has been publicly released. There are two subsets in the dataset, $i.e.$, the test-dev subset and test-challenge subset. Both subsets consist of 140 thermal infrared video sequences, spanning multiple occurrences of multi-scale UAVs. Around 24 participating teams from the globe competed in the 2nd Anti-UAV Challenge. In this paper, we provide a brief summary of the 2nd Anti-UAV Workshop \& Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that are interested in the Anti-UAV challenge. The benchmark dataset and other information can be found at: https://anti-uav.github.io/.