 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVC-LLM: Automated Advertisement Video Creation from Raw Footage using Multi-modal LLMs
Apr 08, 2025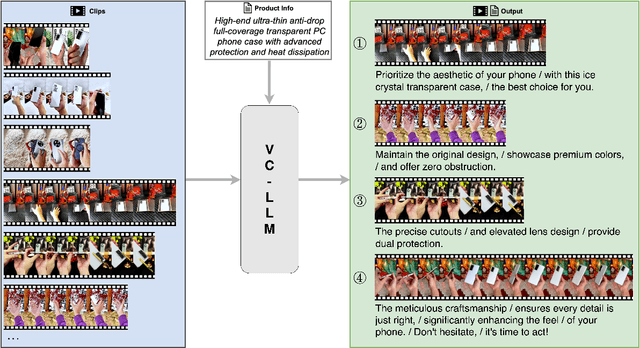
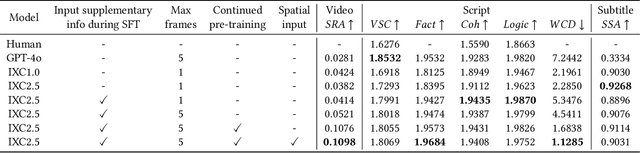
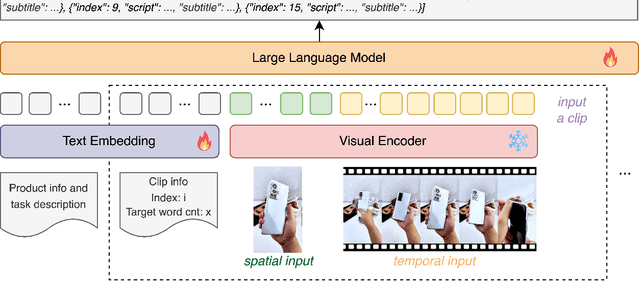

As short videos have risen in popularity, the role of video content in advertising has become increasingly significant. Typically, advertisers record a large amount of raw footage about the product and then create numerous different short-form advertisement videos based on this raw footage. Creating such videos mainly involves editing raw footage and writing advertisement scripts, which requires a certain level of creative ability. It is usually challenging to create many different video contents for the same product, and manual efficiency is often low. In this paper, we present VC-LLM, a framework powered by Large Language Models for the automatic creation of high-quality short-form advertisement videos. Our approach leverages high-resolution spatial input and low-resolution temporal input to represent video clips more effectively, capturing both fine-grained visual details and broader temporal dynamics. In addition, during training, we incorporate supplementary information generated by rewriting the ground truth text, ensuring that all key output information can be directly traced back to the input, thereby reducing model hallucinations. We also designed a benchmark to evaluate the quality of the created videos. Experiments show that VC-LLM based on GPT-4o can produce videos comparable to those created by humans. Furthermore, we collected numerous high-quality short advertisement videos to create a pre-training dataset and manually cleaned a portion of the data to construct a high-quality fine-tuning dataset. Experiments indicate that, on the benchmark, the VC-LLM based on fine-tuned LLM can produce videos with superior narrative logic compared to those created by the VC-LLM based on GPT-4o.
YOLIC: An Efficient Method for Object Localization and Classification on Edge Devices
Jul 30, 2023



In the realm of Tiny AI, we introduce ``You Only Look at Interested Cells" (YOLIC), an efficient method for object localization and classification on edge devices. Through seamlessly blending the strengths of semantic segmentation and object detection, YOLIC offers superior computational efficiency and precision. By adopting Cells of Interest for classification instead of individual pixels, YOLIC encapsulates relevant information, reduces computational load, and enables rough object shape inference. Importantly, the need for bounding box regression is obviated, as YOLIC capitalizes on the predetermined cell configuration that provides information about potential object location, size, and shape. To tackle the issue of single-label classification limitations, a multi-label classification approach is applied to each cell for effectively recognizing overlapping or closely situated objects. This paper presents extensive experiments on multiple datasets to demonstrate that YOLIC achieves detection performance comparable to the state-of-the-art YOLO algorithms while surpassing in speed, exceeding 30fps on a Raspberry Pi 4B CPU. All resources related to this study, including datasets, cell designer, image annotation tool, and source code, have been made publicly available on our project website at https://kai3316.github.io/yolic.github.io
QueryPose: Sparse Multi-Person Pose Regression via Spatial-Aware Part-Level Query
Dec 15, 2022



We propose a sparse end-to-end multi-person pose regression framework, termed QueryPose, which can directly predict multi-person keypoint sequences from the input image. The existing end-to-end methods rely on dense representations to preserve the spatial detail and structure for precise keypoint localization. However, the dense paradigm introduces complex and redundant post-processes during inference. In our framework, each human instance is encoded by several learnable spatial-aware part-level queries associated with an instance-level query. First, we propose the Spatial Part Embedding Generation Module (SPEGM) that considers the local spatial attention mechanism to generate several spatial-sensitive part embeddings, which contain spatial details and structural information for enhancing the part-level queries. Second, we introduce the Selective Iteration Module (SIM) to adaptively update the sparse part-level queries via the generated spatial-sensitive part embeddings stage-by-stage. Based on the two proposed modules, the part-level queries are able to fully encode the spatial details and structural information for precise keypoint regression. With the bipartite matching, QueryPose avoids the hand-designed post-processes and surpasses the existing dense end-to-end methods with 73.6 AP on MS COCO mini-val set and 72.7 AP on CrowdPose test set. Code is available at https://github.com/buptxyb666/QueryPose.
AdaptivePose++: A Powerful Single-Stage Network for Multi-Person Pose Regression
Oct 08, 2022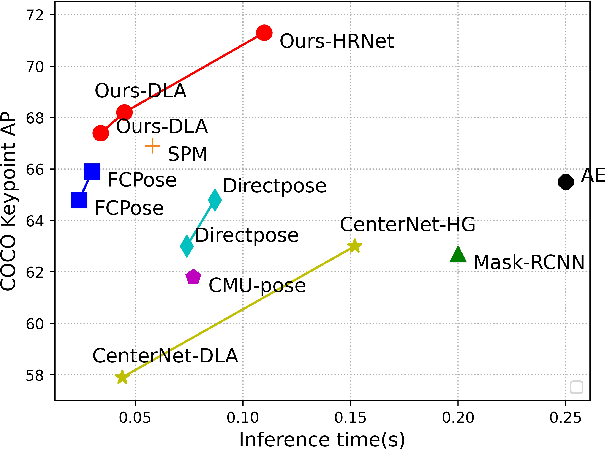

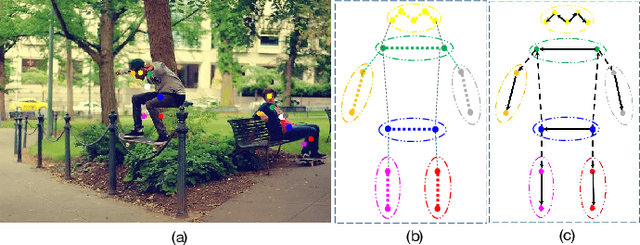
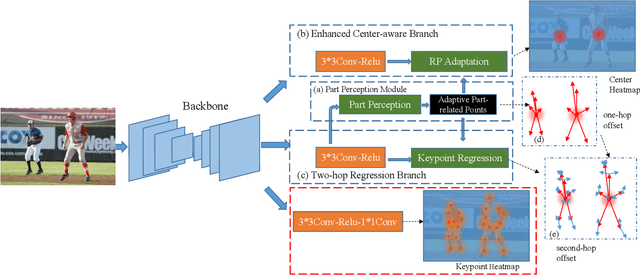
Multi-person pose estimation generally follows top-down and bottom-up paradigms. Both of them use an extra stage ($\boldsymbol{e.g.,}$ human detection in top-down paradigm or grouping process in bottom-up paradigm) to build the relationship between the human instance and corresponding keypoints, thus leading to the high computation cost and redundant two-stage pipeline. To address the above issue, we propose to represent the human parts as adaptive points and introduce a fine-grained body representation method. The novel body representation is able to sufficiently encode the diverse pose information and effectively model the relationship between the human instance and corresponding keypoints in a single-forward pass. With the proposed body representation, we further deliver a compact single-stage multi-person pose regression network, termed as AdaptivePose. During inference, our proposed network only needs a single-step decode operation to form the multi-person pose without complex post-processes and refinements. We employ AdaptivePose for both 2D/3D multi-person pose estimation tasks to verify the effectiveness of AdaptivePose. Without any bells and whistles, we achieve the most competitive performance on MS COCO and CrowdPose in terms of accuracy and speed. Furthermore, the outstanding performance on MuCo-3DHP and MuPoTS-3D further demonstrates the effectiveness and generalizability on 3D scenes. Code is available at https://github.com/buptxyb666/AdaptivePose.
Mask and Reason: Pre-Training Knowledge Graph Transformers for Complex Logical Queries
Aug 16, 2022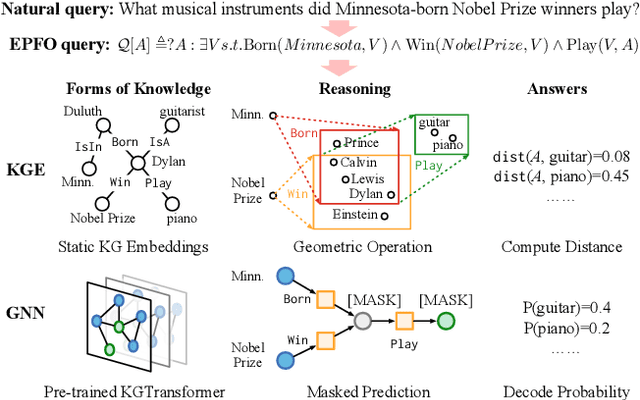
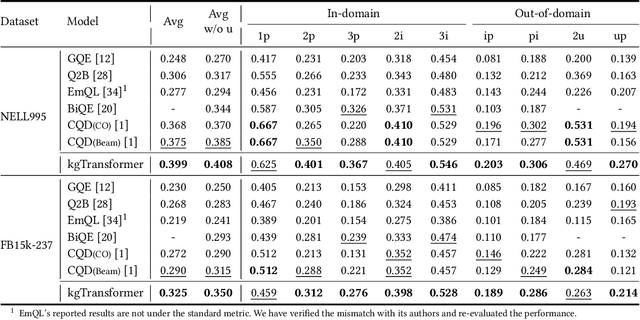
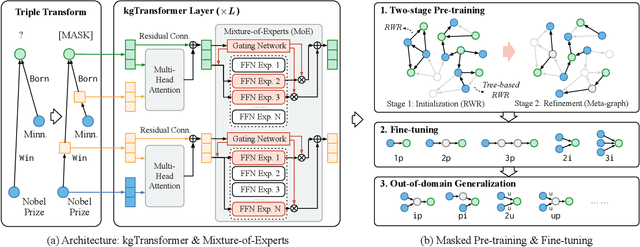
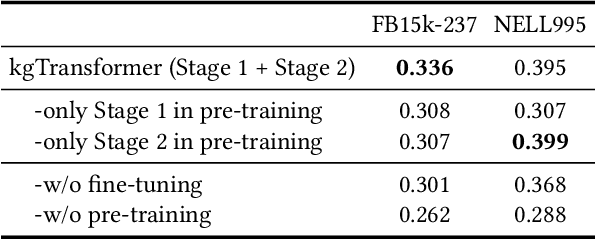
Knowledge graph (KG) embeddings have been a mainstream approach for reasoning over incomplete KGs. However, limited by their inherently shallow and static architectures, they can hardly deal with the rising focus on complex logical queries, which comprise logical operators, imputed edges, multiple source entities, and unknown intermediate entities. In this work, we present the Knowledge Graph Transformer (kgTransformer) with masked pre-training and fine-tuning strategies. We design a KG triple transformation method to enable Transformer to handle KGs, which is further strengthened by the Mixture-of-Experts (MoE) sparse activation. We then formulate the complex logical queries as masked prediction and introduce a two-stage masked pre-training strategy to improve transferability and generalizability. Extensive experiments on two benchmarks demonstrate that kgTransformer can consistently outperform both KG embedding-based baselines and advanced encoders on nine in-domain and out-of-domain reasoning tasks. Additionally, kgTransformer can reason with explainability via providing the full reasoning paths to interpret given answers.
Weakly Supervised Person Search with Region Siamese Networks
Sep 13, 2021

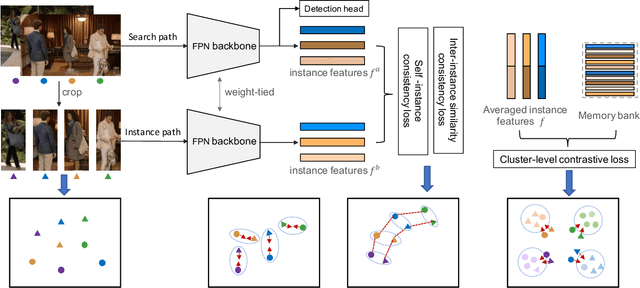
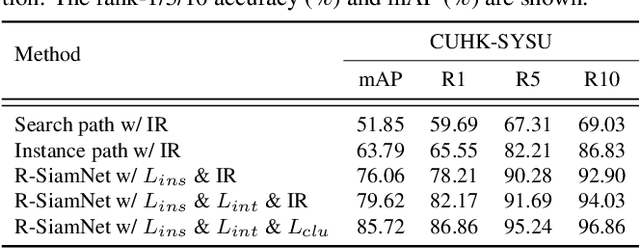
Supervised learning is dominant in person search, but it requires elaborate labeling of bounding boxes and identities. Large-scale labeled training data is often difficult to collect, especially for person identities. A natural question is whether a good person search model can be trained without the need of identity supervision. In this paper, we present a weakly supervised setting where only bounding box annotations are available. Based on this new setting, we provide an effective baseline model termed Region Siamese Networks (R-SiamNets). Towards learning useful representations for recognition in the absence of identity labels, we supervise the R-SiamNet with instance-level consistency loss and cluster-level contrastive loss. For instance-level consistency learning, the R-SiamNet is constrained to extract consistent features from each person region with or without out-of-region context. For cluster-level contrastive learning, we enforce the aggregation of closest instances and the separation of dissimilar ones in feature space. Extensive experiments validate the utility of our weakly supervised method. Our model achieves the rank-1 of 87.1% and mAP of 86.0% on CUHK-SYSU benchmark, which surpasses several fully supervised methods, such as OIM and MGTS, by a clear margin. More promising performance can be reached by incorporating extra training data. We hope this work could encourage the future research in this field.
Memory Based Video Scene Parsing
Sep 01, 2021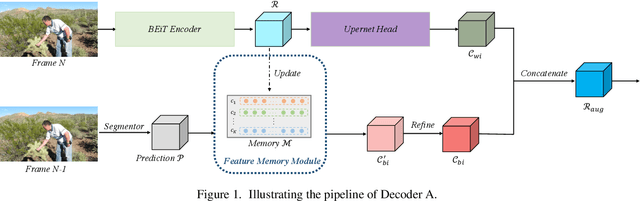
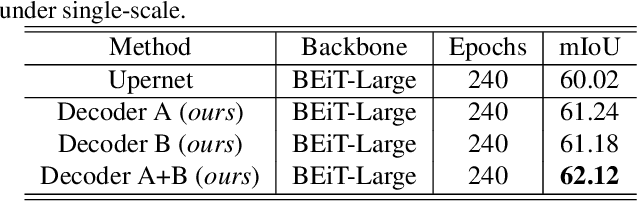
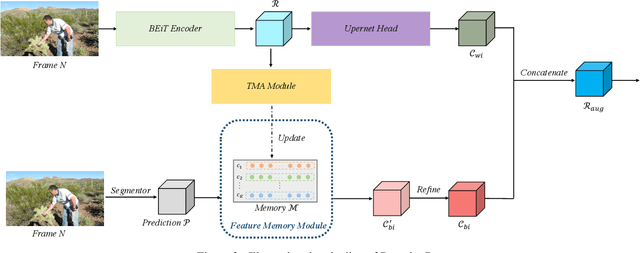

Video scene parsing is a long-standing challenging task in computer vision, aiming to assign pre-defined semantic labels to pixels of all frames in a given video. Compared with image semantic segmentation, this task pays more attention on studying how to adopt the temporal information to obtain higher predictive accuracy. In this report, we introduce our solution for the 1st Video Scene Parsing in the Wild Challenge, which achieves a mIoU of 57.44 and obtained the 2nd place (our team name is CharlesBLWX).
OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Models
Mar 23, 2021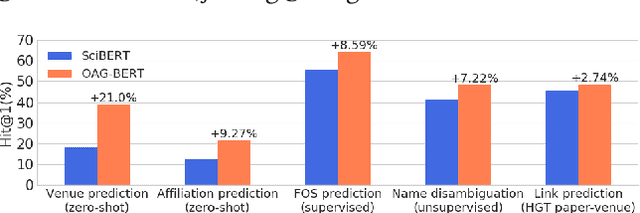
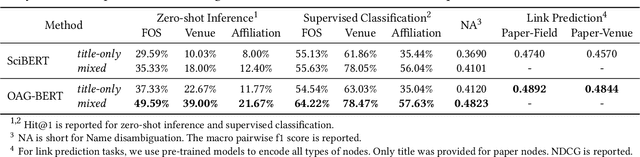
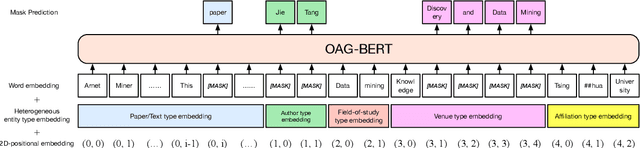
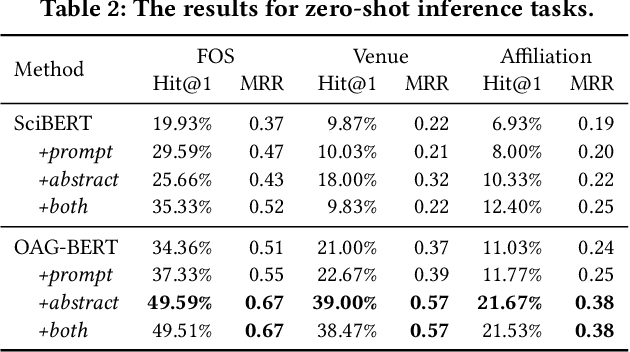
To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations and paper tagging in the AMiner system. It is also available to the public through the CogDL package.
Towards Good Practices for Multi-Person Pose Estimation
Oct 28, 2019



Multi-Person Pose Estimation is an interesting yet challenging task in computer vision. In this paper, we conduct a series of refinements with the MSPN and PoseFix Networks, and empirically evaluate their impact on the final model performance through ablation studies. By taking all the refinements, we achieve 78.7 on the COCO test-dev dataset and 76.3 on the COCO test-challenge dataset.
Towards Good Practices for Video Object Segmentation
Sep 30, 2019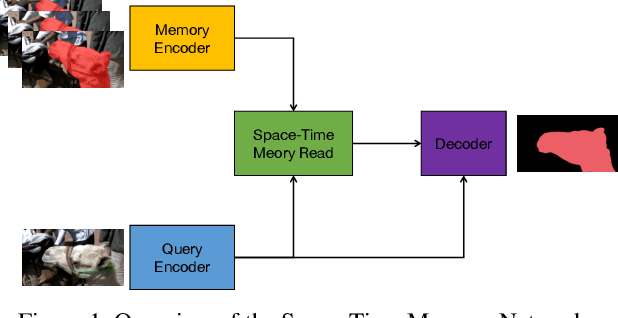

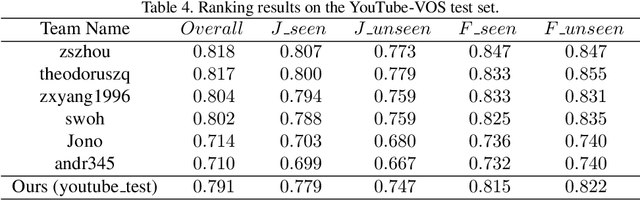
Semi-supervised video object segmentation is an interesting yet challenging task in machine learning. In this work, we conduct a series of refinements with the propagation-based video object segmentation method and empirically evaluate their impact on the final model performance through ablation study. By taking all the refinements, we improve the space-time memory networks to achieve a Overall of 79.1 on the Youtube-VOS Challenge 2019.