 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Depth Anything: Consistent Depth Estimation for Super-Long Videos
Jan 21, 2025Depth Anything has achieved remarkable success in monocular depth estimation with strong generalization ability. However, it suffers from temporal inconsistency in videos, hindering its practical applications. Various methods have been proposed to alleviate this issue by leveraging video generation models or introducing priors from optical flow and camera poses. Nonetheless, these methods are only applicable to short videos (< 10 seconds) and require a trade-off between quality and computational efficiency. We propose Video Depth Anything for high-quality, consistent depth estimation in super-long videos (over several minutes) without sacrificing efficiency. We base our model on Depth Anything V2 and replace its head with an efficient spatial-temporal head. We design a straightforward yet effective temporal consistency loss by constraining the temporal depth gradient, eliminating the need for additional geometric priors. The model is trained on a joint dataset of video depth and unlabeled images, similar to Depth Anything V2. Moreover, a novel key-frame-based strategy is developed for long video inference. Experiments show that our model can be applied to arbitrarily long videos without compromising quality, consistency, or generalization ability. Comprehensive evaluations on multiple video benchmarks demonstrate that our approach sets a new state-of-the-art in zero-shot video depth estimation. We offer models of different scales to support a range of scenarios, with our smallest model capable of real-time performance at 30 FPS.
MonoPlane: Exploiting Monocular Geometric Cues for Generalizable 3D Plane Reconstruction
Nov 02, 2024
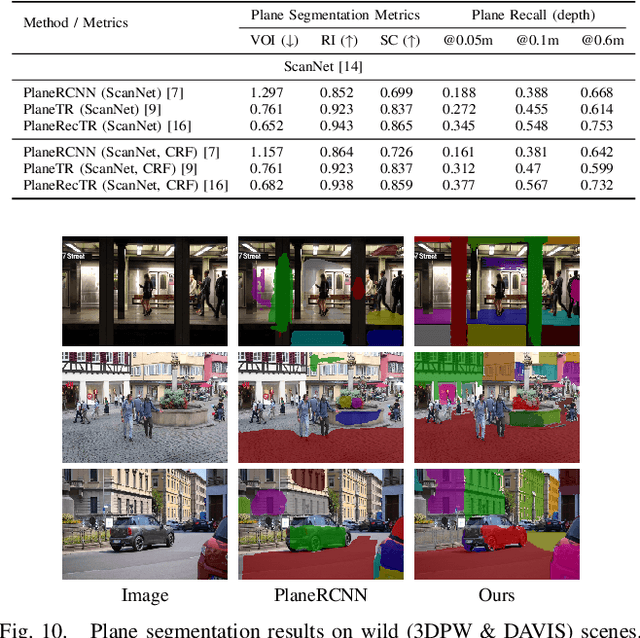


This paper presents a generalizable 3D plane detection and reconstruction framework named MonoPlane. Unlike previous robust estimator-based works (which require multiple images or RGB-D input) and learning-based works (which suffer from domain shift), MonoPlane combines the best of two worlds and establishes a plane reconstruction pipeline based on monocular geometric cues, resulting in accurate, robust and scalable 3D plane detection and reconstruction in the wild. Specifically, we first leverage large-scale pre-trained neural networks to obtain the depth and surface normals from a single image. These monocular geometric cues are then incorporated into a proximity-guided RANSAC framework to sequentially fit each plane instance. We exploit effective 3D point proximity and model such proximity via a graph within RANSAC to guide the plane fitting from noisy monocular depths, followed by image-level multi-plane joint optimization to improve the consistency among all plane instances. We further design a simple but effective pipeline to extend this single-view solution to sparse-view 3D plane reconstruction. Extensive experiments on a list of datasets demonstrate our superior zero-shot generalizability over baselines, achieving state-of-the-art plane reconstruction performance in a transferring setting. Our code is available at https://github.com/thuzhaowang/MonoPlane .
Lazy Visual Localization via Motion Averaging
Jul 19, 2023



Visual (re)localization is critical for various applications in computer vision and robotics. Its goal is to estimate the 6 degrees of freedom (DoF) camera pose for each query image, based on a set of posed database images. Currently, all leading solutions are structure-based that either explicitly construct 3D metric maps from the database with structure-from-motion, or implicitly encode the 3D information with scene coordinate regression models. On the contrary, visual localization without reconstructing the scene in 3D offers clear benefits. It makes deployment more convenient by reducing database pre-processing time, releasing storage requirements, and remaining unaffected by imperfect reconstruction, etc. In this technical report, we demonstrate that it is possible to achieve high localization accuracy without reconstructing the scene from the database. The key to achieving this owes to a tailored motion averaging over database-query pairs. Experiments show that our visual localization proposal, LazyLoc, achieves comparable performance against state-of-the-art structure-based methods. Furthermore, we showcase the versatility of LazyLoc, which can be easily extended to handle complex configurations such as multi-query co-localization and camera rigs.
ParticleSfM: Exploiting Dense Point Trajectories for Localizing Moving Cameras in the Wild
Jul 19, 2022
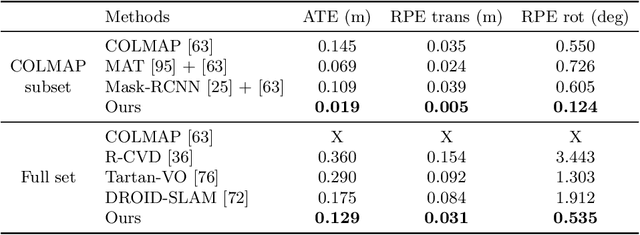
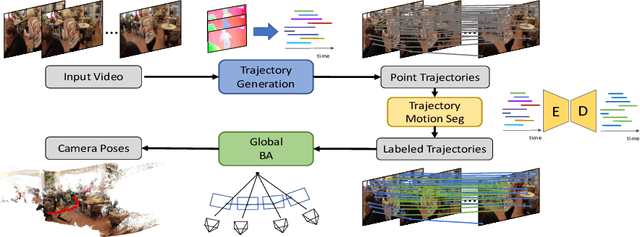
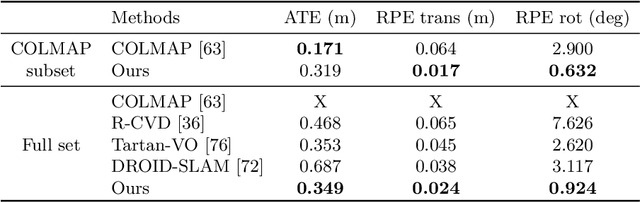
Estimating the pose of a moving camera from monocular video is a challenging problem, especially due to the presence of moving objects in dynamic environments, where the performance of existing camera pose estimation methods are susceptible to pixels that are not geometrically consistent. To tackle this challenge, we present a robust dense indirect structure-from-motion method for videos that is based on dense correspondence initialized from pairwise optical flow. Our key idea is to optimize long-range video correspondence as dense point trajectories and use it to learn robust estimation of motion segmentation. A novel neural network architecture is proposed for processing irregular point trajectory data. Camera poses are then estimated and optimized with global bundle adjustment over the portion of long-range point trajectories that are classified as static. Experiments on MPI Sintel dataset show that our system produces significantly more accurate camera trajectories compared to existing state-of-the-art methods. In addition, our method is able to retain reasonable accuracy of camera poses on fully static scenes, which consistently outperforms strong state-of-the-art dense correspondence based methods with end-to-end deep learning, demonstrating the potential of dense indirect methods based on optical flow and point trajectories. As the point trajectory representation is general, we further present results and comparisons on in-the-wild monocular videos with complex motion of dynamic objects. Code is available at https://github.com/bytedance/particle-sfm.
A Confidence-based Iterative Solver of Depths and Surface Normals for Deep Multi-view Stereo
Jan 19, 2022
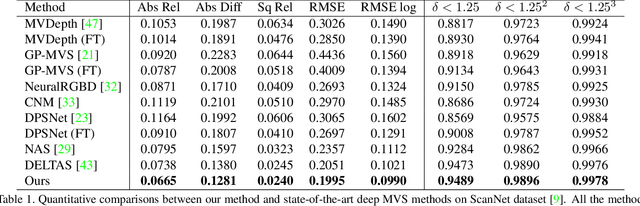
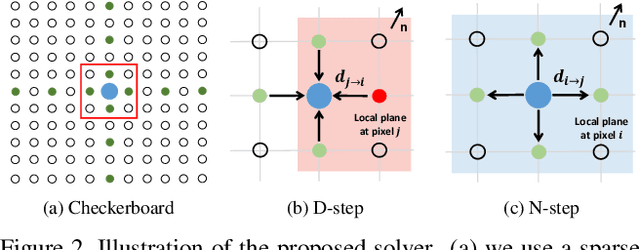
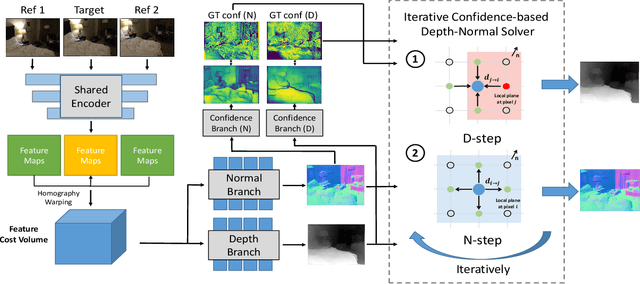
In this paper, we introduce a deep multi-view stereo (MVS) system that jointly predicts depths, surface normals and per-view confidence maps. The key to our approach is a novel solver that iteratively solves for per-view depth map and normal map by optimizing an energy potential based on the locally planar assumption. Specifically, the algorithm updates depth map by propagating from neighboring pixels with slanted planes, and updates normal map with local probabilistic plane fitting. Both two steps are monitored by a customized confidence map. This solver is not only effective as a post-processing tool for plane-based depth refinement and completion, but also differentiable such that it can be efficiently integrated into deep learning pipelines. Our multi-view stereo system employs multiple optimization steps of the solver over the initial prediction of depths and surface normals. The whole system can be trained end-to-end, decoupling the challenging problem of matching pixels within poorly textured regions from the cost-volume based neural network. Experimental results on ScanNet and RGB-D Scenes V2 demonstrate state-of-the-art performance of the proposed deep MVS system on multi-view depth estimation, with our proposed solver consistently improving the depth quality over both conventional and deep learning based MVS pipelines. Code is available at https://github.com/thuzhaowang/idn-solver.
GPO: Global Plane Optimization for Fast and Accurate Monocular SLAM Initialization
May 24, 2020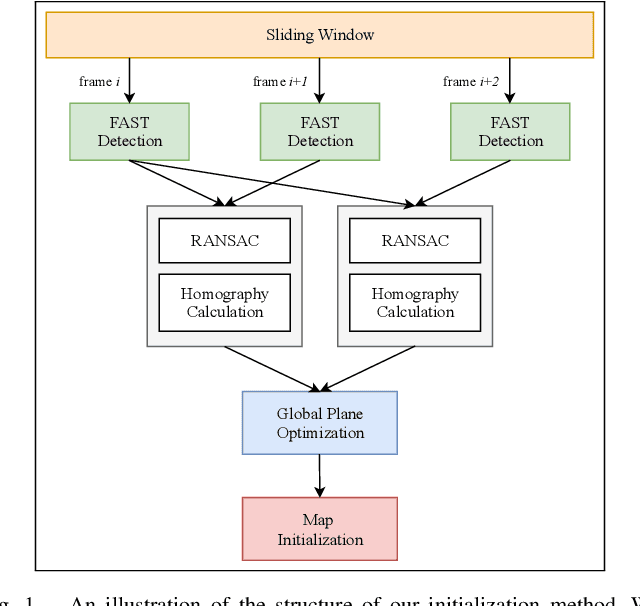
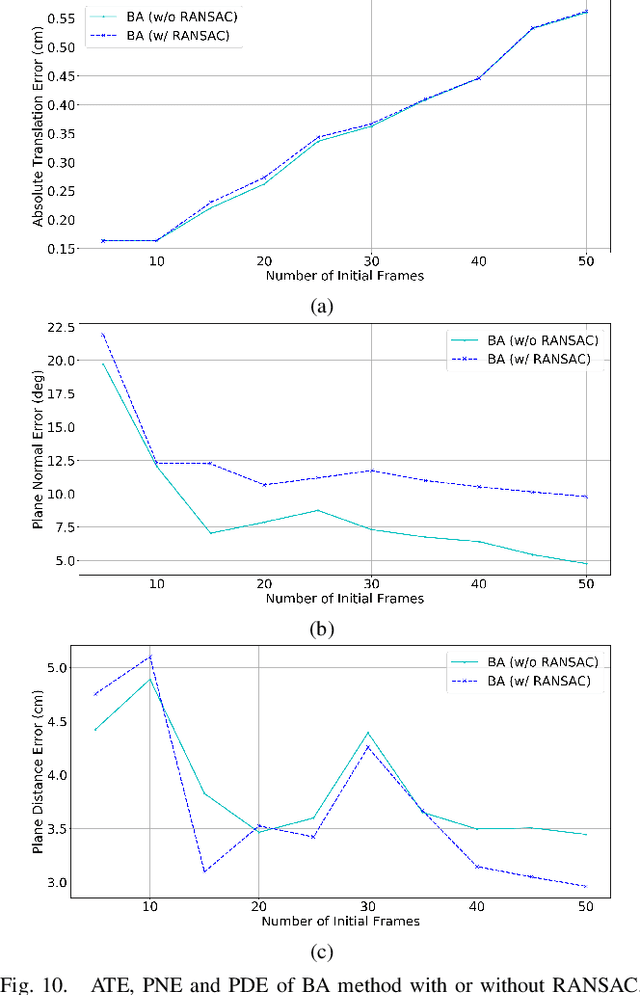
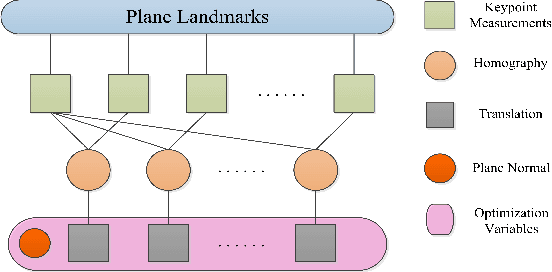

Initialization is essential to monocular Simultaneous Localization and Mapping (SLAM) problems. This paper focuses on a novel initialization method for monocular SLAM based on planar features. The algorithm starts by homography estimation in a sliding window. It then proceeds to a global plane optimization (GPO) to obtain camera poses and the plane normal. 3D points can be recovered using planar constraints without triangulation. The proposed method fully exploits the plane information from multiple frames and avoids the ambiguities in homography decomposition. We validate our algorithm on the collected chessboard dataset against baseline implementations and present extensive analysis. Experimental results show that our method outperforms the fine-tuned baselines in both accuracy and real-time.
Towards Good Practices for Video Object Segmentation
Sep 30, 2019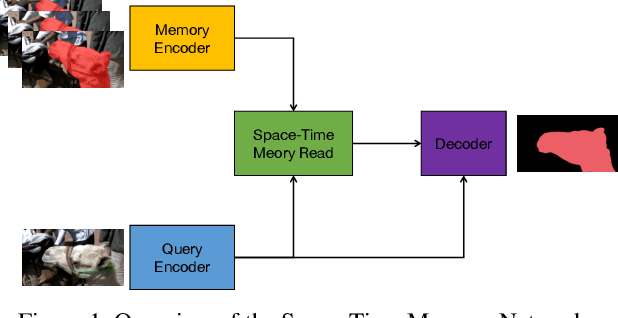

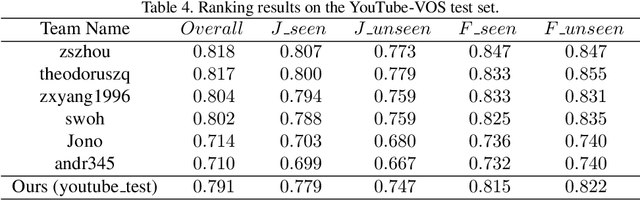
Semi-supervised video object segmentation is an interesting yet challenging task in machine learning. In this work, we conduct a series of refinements with the propagation-based video object segmentation method and empirically evaluate their impact on the final model performance through ablation study. By taking all the refinements, we improve the space-time memory networks to achieve a Overall of 79.1 on the Youtube-VOS Challenge 2019.
An Empirical Study of Propagation-based Methods for Video Object Segmentation
Jul 30, 2019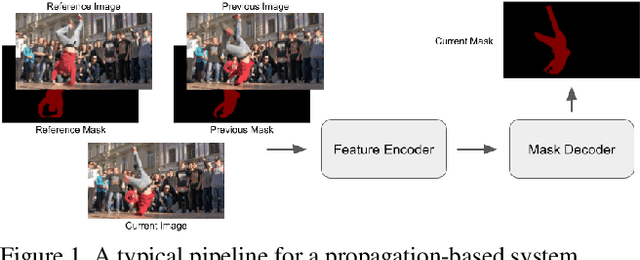
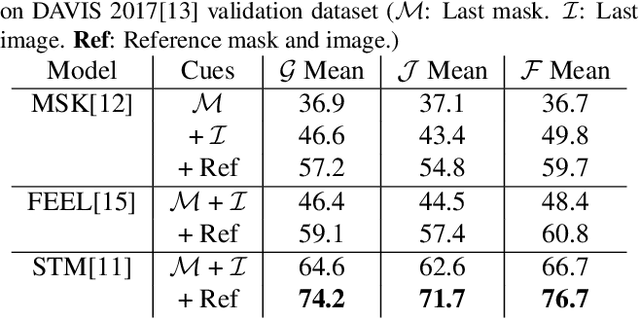
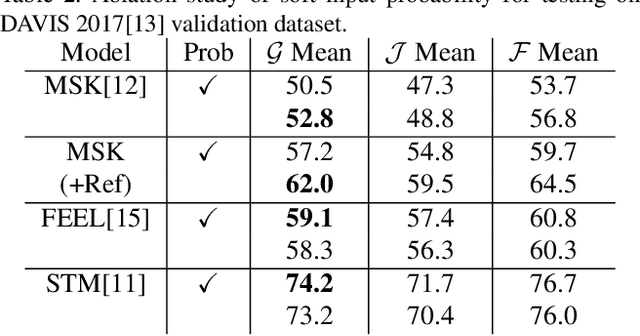
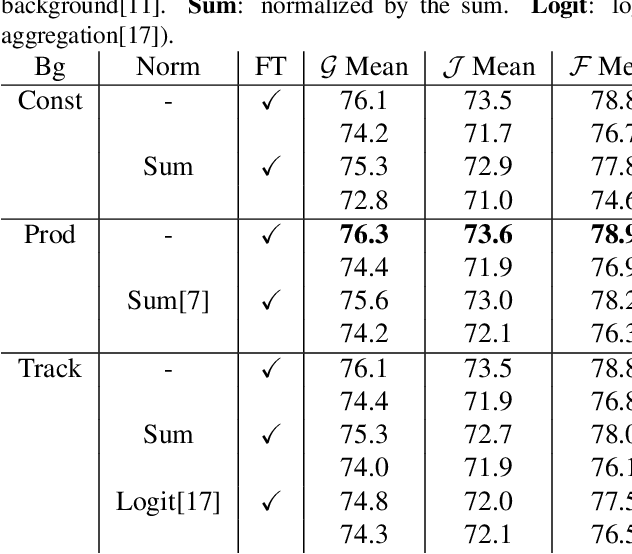
While propagation-based approaches have achieved state-of-the-art performance for video object segmentation, the literature lacks a fair comparison of different methods using the same settings. In this paper, we carry out an empirical study for propagation-based methods. We view these approaches from a unified perspective and conduct detailed ablation study for core methods, input cues, multi-object combination and training strategies. With careful designs, our improved end-to-end memory networks achieve a global mean of 76.1 on DAVIS 2017 val set.
Multi-Domain Pose Network for Multi-Person Pose Estimation and Tracking
Oct 19, 2018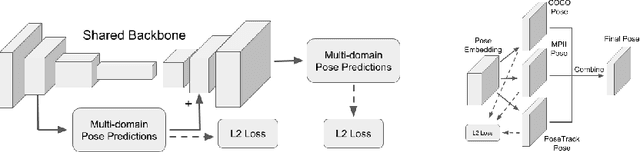


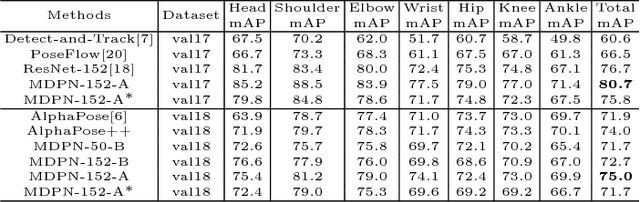
Multi-person human pose estimation and tracking in the wild is important and challenging. For training a powerful model, large-scale training data are crucial. While there are several datasets for human pose estimation, the best practice for training on multi-dataset has not been investigated. In this paper, we present a simple network called Multi-Domain Pose Network (MDPN) to address this problem. By treating the task as multi-domain learning, our methods can learn a better representation for pose prediction. Together with prediction heads fine-tuning and multi-branch combination, it shows significant improvement over baselines and achieves the best performance on PoseTrack ECCV 2018 Challenge without additional datasets other than MPII and COCO.
Interactive Hand Pose Estimation: Boosting accuracy in localizing extended finger joints
Jul 25, 2018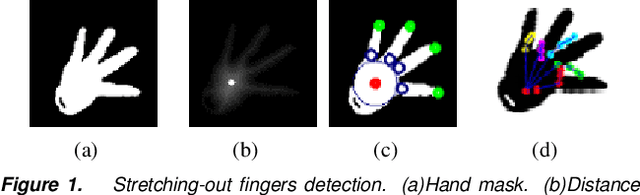
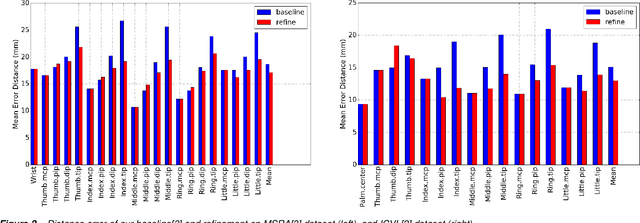
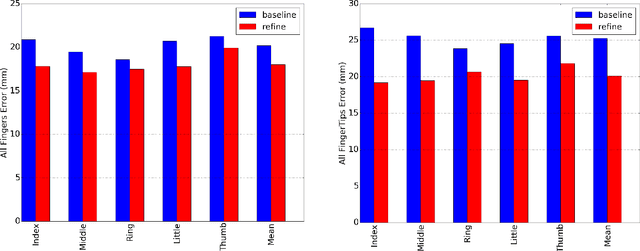
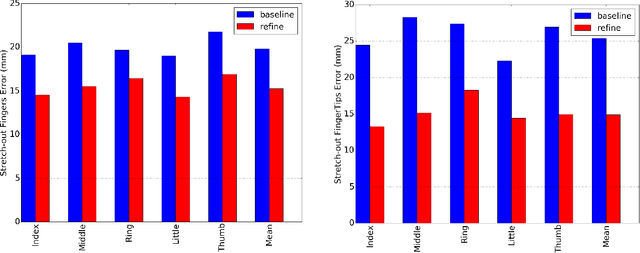
Accurate 3D hand pose estimation plays an important role in Human Machine Interaction (HMI). In the reality of HMI, joints in fingers stretching out, especially corresponding fingertips, are much more important than other joints. We propose a novel method to refine stretching-out finger joint locations after obtaining rough hand pose estimation. It first detects which fingers are stretching out, then neighbor pixels of certain joint vote for its new location based on random forests. The algorithm is tested on two public datasets: MSRA15 and ICVL. After the refinement stage of stretching-out fingers, errors of predicted HMI finger joint locations are significantly reduced. Mean error of all fingertips reduces around 5mm (relatively more than 20%). Stretching-out fingertip locations are even more precise, which in MSRA15 reduces 10.51mm (relatively 41.4%).
* Original publication available on https://doi.org/10.2352/ISSN.2470-1173.2018.2.VIPC-251