 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing the motion of every joint: 3D human pose and shape estimation with independent tokens
Mar 01, 2023



In this paper we present a novel method to estimate 3D human pose and shape from monocular videos. This task requires directly recovering pixel-alignment 3D human pose and body shape from monocular images or videos, which is challenging due to its inherent ambiguity. To improve precision, existing methods highly rely on the initialized mean pose and shape as prior estimates and parameter regression with an iterative error feedback manner. In addition, video-based approaches model the overall change over the image-level features to temporally enhance the single-frame feature, but fail to capture the rotational motion at the joint level, and cannot guarantee local temporal consistency. To address these issues, we propose a novel Transformer-based model with a design of independent tokens. First, we introduce three types of tokens independent of the image feature: \textit{joint rotation tokens, shape token, and camera token}. By progressively interacting with image features through Transformer layers, these tokens learn to encode the prior knowledge of human 3D joint rotations, body shape, and position information from large-scale data, and are updated to estimate SMPL parameters conditioned on a given image. Second, benefiting from the proposed token-based representation, we further use a temporal model to focus on capturing the rotational temporal information of each joint, which is empirically conducive to preventing large jitters in local parts. Despite being conceptually simple, the proposed method attains superior performances on the 3DPW and Human3.6M datasets. Using ResNet-50 and Transformer architectures, it obtains 42.0 mm error on the PA-MPJPE metric of the challenging 3DPW, outperforming state-of-the-art counterparts by a large margin. Code will be publicly available at https://github.com/yangsenius/INT_HMR_Model
Efficient Single-Image Depth Estimation on Mobile Devices, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022

Various depth estimation models are now widely used on many mobile and IoT devices for image segmentation, bokeh effect rendering, object tracking and many other mobile tasks. Thus, it is very crucial to have efficient and accurate depth estimation models that can run fast on low-power mobile chipsets. In this Mobile AI challenge, the target was to develop deep learning-based single image depth estimation solutions that can show a real-time performance on IoT platforms and smartphones. For this, the participants used a large-scale RGB-to-depth dataset that was collected with the ZED stereo camera capable to generated depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the Raspberry Pi 4 platform, where the developed solutions were able to generate VGA resolution depth maps at up to 27 FPS while achieving high fidelity results. All models developed in the challenge are also compatible with any Android or Linux-based mobile devices, their detailed description is provided in this paper.
TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation
Apr 12, 2022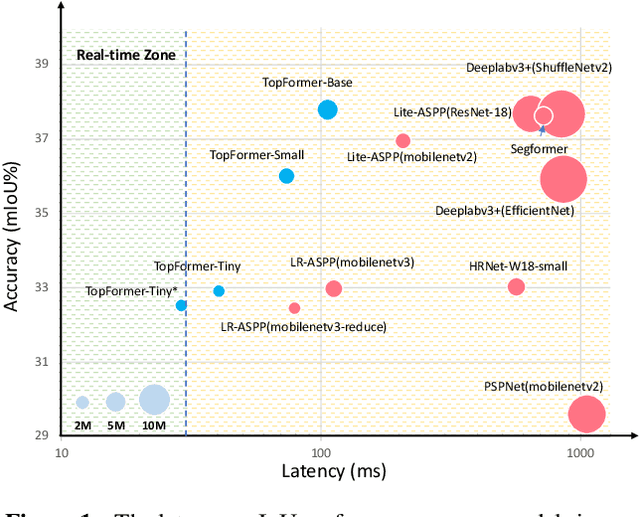
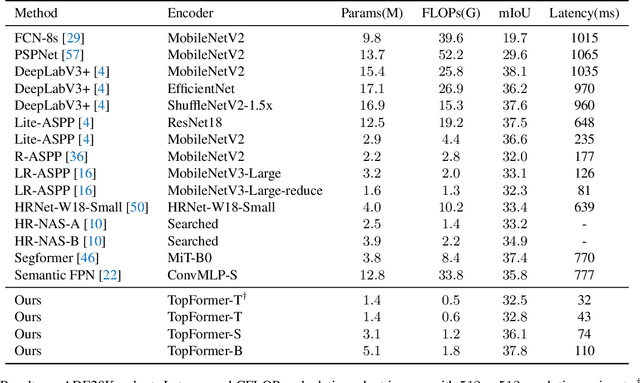
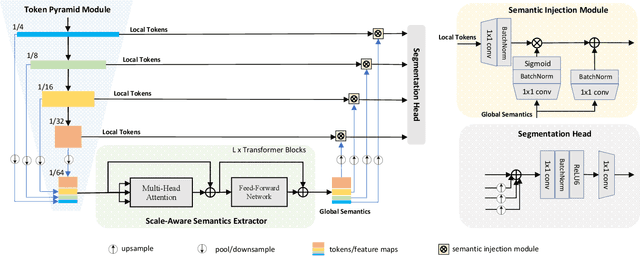
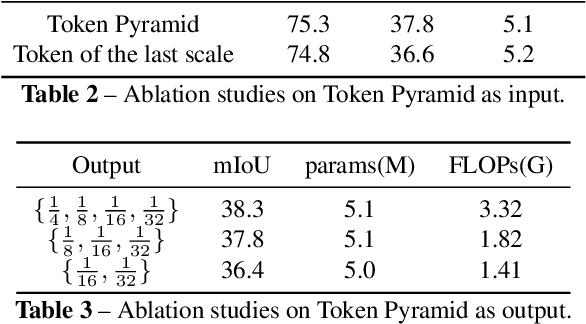
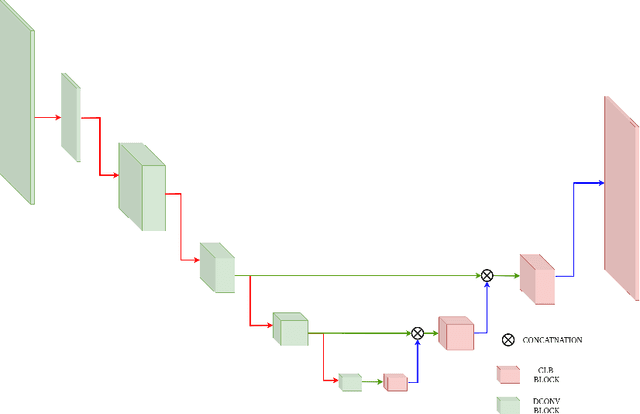
Although vision transformers (ViTs) have achieved great success in computer vision, the heavy computational cost hampers their applications to dense prediction tasks such as semantic segmentation on mobile devices. In this paper, we present a mobile-friendly architecture named \textbf{To}ken \textbf{P}yramid Vision Trans\textbf{former} (\textbf{TopFormer}). The proposed \textbf{TopFormer} takes Tokens from various scales as input to produce scale-aware semantic features, which are then injected into the corresponding tokens to augment the representation. Experimental results demonstrate that our method significantly outperforms CNN- and ViT-based networks across several semantic segmentation datasets and achieves a good trade-off between accuracy and latency. On the ADE20K dataset, TopFormer achieves 5\% higher accuracy in mIoU than MobileNetV3 with lower latency on an ARM-based mobile device. Furthermore, the tiny version of TopFormer achieves real-time inference on an ARM-based mobile device with competitive results. The code and models are available at: https://github.com/hustvl/TopFormer
Sketch Me A Video
Oct 10, 2021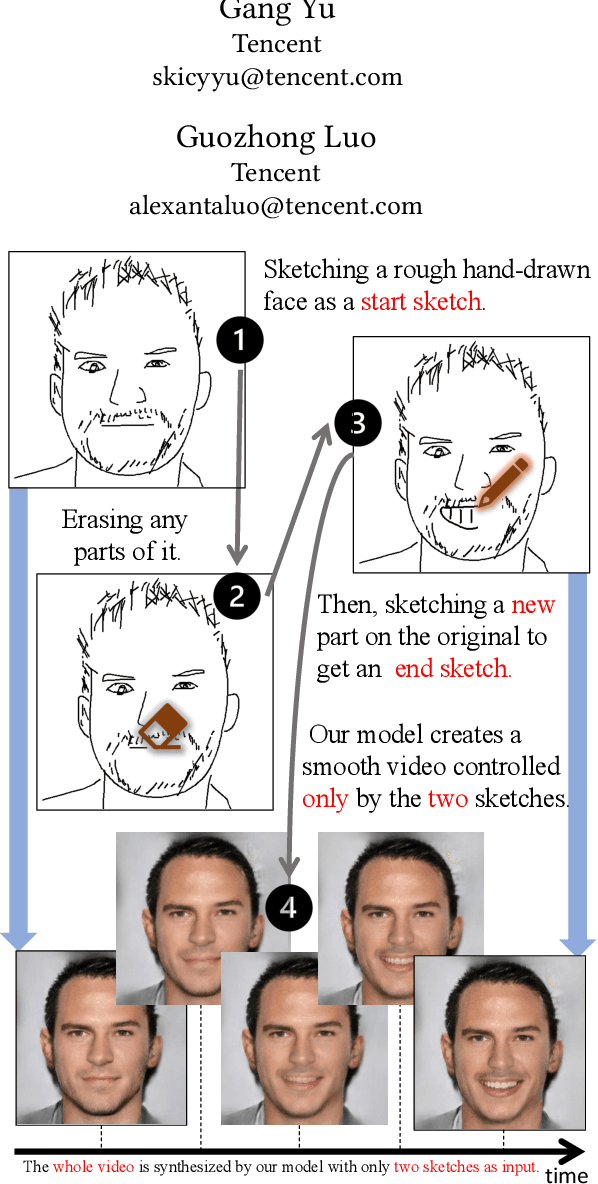

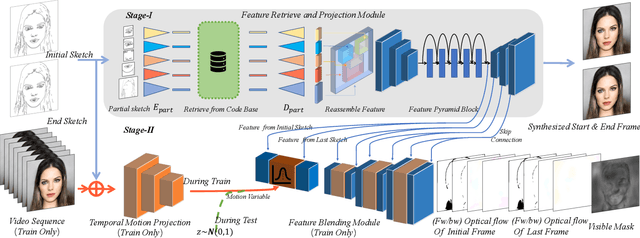

Video creation has been an attractive yet challenging task for artists to explore. With the advancement of deep learning, recent works try to utilize deep convolutional neural networks to synthesize a video with the aid of a guiding video, and have achieved promising results. However, the acquisition of guiding videos, or other forms of guiding temporal information is costly expensive and difficult in reality. Therefore, in this work we introduce a new video synthesis task by employing two rough bad-drwan sketches only as input to create a realistic portrait video. A two-stage Sketch-to-Video model is proposed, which consists of two key novelties: 1) a feature retrieve and projection (FRP) module, which parititions the input sketch into different parts and utilizes these parts for synthesizing a realistic start or end frame and meanwhile generating rich semantic features, is designed to alleviate the sketch out-of-domain problem due to arbitrarily drawn free-form sketch styles by different users. 2) A motion projection followed by feature blending module, which projects a video (used only in training phase) into a motion space modeled by normal distribution and blends the motion variables with semantic features extracted above, is proposed to alleviate the guiding temporal information missing problem in the test phase. Experiments conducted on a combination of CelebAMask-HQ and VoxCeleb2 dataset well validate that, our method can acheive both good quantitative and qualitative results in synthesizing high-quality videos from two rough bad-drawn sketches.
Shuffle Transformer with Feature Alignment for Video Face Parsing
Jun 16, 2021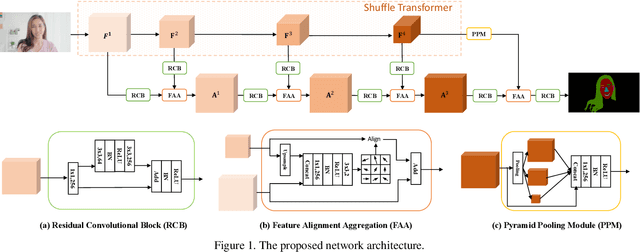

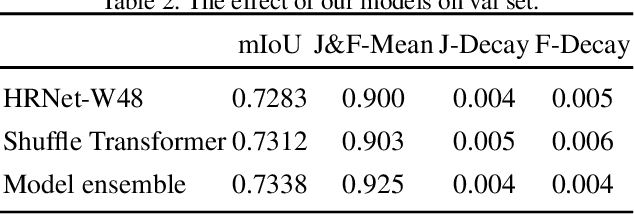
This is a short technical report introducing the solution of the Team TCParser for Short-video Face Parsing Track of The 3rd Person in Context (PIC) Workshop and Challenge at CVPR 2021. In this paper, we introduce a strong backbone which is cross-window based Shuffle Transformer for presenting accurate face parsing representation. To further obtain the finer segmentation results, especially on the edges, we introduce a Feature Alignment Aggregation (FAA) module. It can effectively relieve the feature misalignment issue caused by multi-resolution feature aggregation. Benefiting from the stronger backbone and better feature aggregation, the proposed method achieves 86.9519% score in the Short-video Face Parsing track of the 3rd Person in Context (PIC) Workshop and Challenge, ranked the first place.
Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer
Jun 07, 2021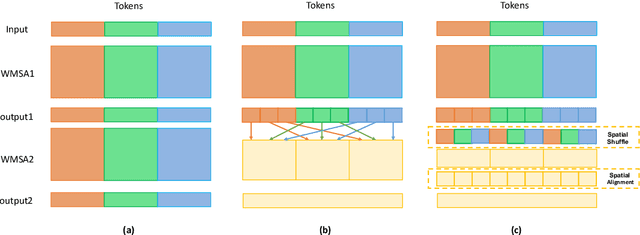
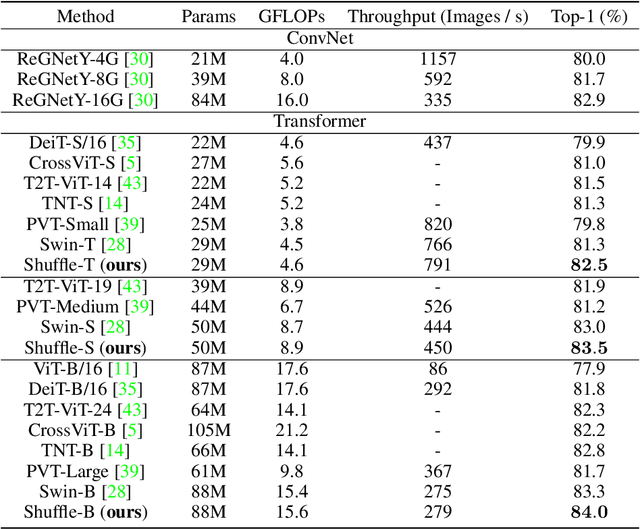

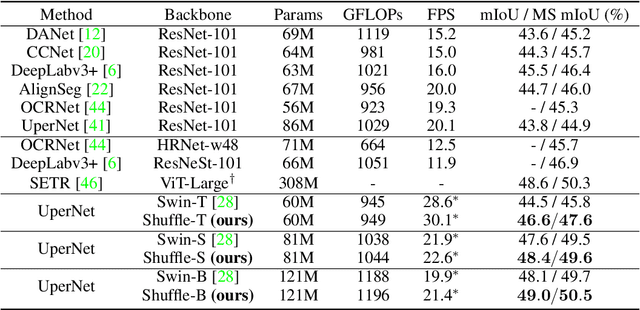
Very recently, Window-based Transformers, which computed self-attention within non-overlapping local windows, demonstrated promising results on image classification, semantic segmentation, and object detection. However, less study has been devoted to the cross-window connection which is the key element to improve the representation ability. In this work, we revisit the spatial shuffle as an efficient way to build connections among windows. As a result, we propose a new vision transformer, named Shuffle Transformer, which is highly efficient and easy to implement by modifying two lines of code. Furthermore, the depth-wise convolution is introduced to complement the spatial shuffle for enhancing neighbor-window connections. The proposed architectures achieve excellent performance on a wide range of visual tasks including image-level classification, object detection, and semantic segmentation. Code will be released for reproduction.
Fast and Accurate Single-Image Depth Estimation on Mobile Devices, Mobile AI 2021 Challenge: Report
May 17, 2021


Depth estimation is an important computer vision problem with many practical applications to mobile devices. While many solutions have been proposed for this task, they are usually very computationally expensive and thus are not applicable for on-device inference. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based depth estimation solutions that can demonstrate a nearly real-time performance on smartphones and IoT platforms. For this, the participants were provided with a new large-scale dataset containing RGB-depth image pairs obtained with a dedicated stereo ZED camera producing high-resolution depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the popular Raspberry Pi 4 platform with a mobile ARM-based Broadcom chipset. The proposed solutions can generate VGA resolution depth maps at up to 10 FPS on the Raspberry Pi 4 while achieving high fidelity results, and are compatible with any Android or Linux-based mobile devices. A detailed description of all models developed in the challenge is provided in this paper.
Multi-Domain Pose Network for Multi-Person Pose Estimation and Tracking
Oct 19, 2018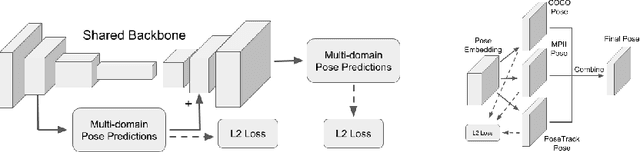


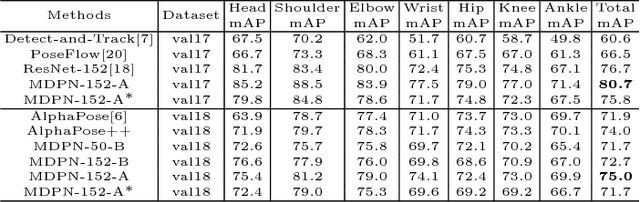
Multi-person human pose estimation and tracking in the wild is important and challenging. For training a powerful model, large-scale training data are crucial. While there are several datasets for human pose estimation, the best practice for training on multi-dataset has not been investigated. In this paper, we present a simple network called Multi-Domain Pose Network (MDPN) to address this problem. By treating the task as multi-domain learning, our methods can learn a better representation for pose prediction. Together with prediction heads fine-tuning and multi-branch combination, it shows significant improvement over baselines and achieves the best performance on PoseTrack ECCV 2018 Challenge without additional datasets other than MPII and COCO.