 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model
Jan 23, 2026Diffusion-based language models (DLLMs) offer non-sequential, block-wise generation and richer data reuse compared to autoregressive (AR) models, but existing code DLLMs still lag behind strong AR baselines under comparable budgets. We revisit this setting in a controlled study and introduce Stable-DiffCoder, a block diffusion code model that reuses the Seed-Coder architecture, data, and training pipeline. To enable efficient knowledge learning and stable training, we incorporate a block diffusion continual pretraining (CPT) stage enhanced by a tailored warmup and block-wise clipped noise schedule. Under the same data and architecture, Stable-DiffCoder overall outperforms its AR counterpart on a broad suite of code benchmarks. Moreover, relying only on the CPT and supervised fine-tuning stages, Stable-DiffCoder achieves stronger performance than a wide range of \~8B ARs and DLLMs, demonstrating that diffusion-based training can improve code modeling quality beyond AR training alone. Moreover, diffusion-based any-order modeling improves structured code modeling for editing and reasoning, and through data augmentation, benefits low-resource coding languages.
MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production
May 19, 2025We present MegaScale-MoE, a production system tailored for the efficient training of large-scale mixture-of-experts (MoE) models. MoE emerges as a promising architecture to scale large language models (LLMs) to unprecedented sizes, thereby enhancing model performance. However, existing MoE training systems experience a degradation in training efficiency, exacerbated by the escalating scale of MoE models and the continuous evolution of hardware. Recognizing the pivotal role of efficient communication in enhancing MoE training, MegaScale-MoE customizes communication-efficient parallelism strategies for attention and FFNs in each MoE layer and adopts a holistic approach to overlap communication with computation at both inter- and intra-operator levels. Additionally, MegaScale-MoE applies communication compression with adjusted communication patterns to lower precision, further improving training efficiency. When training a 352B MoE model on 1,440 NVIDIA Hopper GPUs, MegaScale-MoE achieves a training throughput of 1.41M tokens/s, improving the efficiency by 1.88$\times$ compared to Megatron-LM. We share our operational experience in accelerating MoE training and hope that by offering our insights in system design, this work will motivate future research in MoE systems.
Capturing the motion of every joint: 3D human pose and shape estimation with independent tokens
Mar 01, 2023



In this paper we present a novel method to estimate 3D human pose and shape from monocular videos. This task requires directly recovering pixel-alignment 3D human pose and body shape from monocular images or videos, which is challenging due to its inherent ambiguity. To improve precision, existing methods highly rely on the initialized mean pose and shape as prior estimates and parameter regression with an iterative error feedback manner. In addition, video-based approaches model the overall change over the image-level features to temporally enhance the single-frame feature, but fail to capture the rotational motion at the joint level, and cannot guarantee local temporal consistency. To address these issues, we propose a novel Transformer-based model with a design of independent tokens. First, we introduce three types of tokens independent of the image feature: \textit{joint rotation tokens, shape token, and camera token}. By progressively interacting with image features through Transformer layers, these tokens learn to encode the prior knowledge of human 3D joint rotations, body shape, and position information from large-scale data, and are updated to estimate SMPL parameters conditioned on a given image. Second, benefiting from the proposed token-based representation, we further use a temporal model to focus on capturing the rotational temporal information of each joint, which is empirically conducive to preventing large jitters in local parts. Despite being conceptually simple, the proposed method attains superior performances on the 3DPW and Human3.6M datasets. Using ResNet-50 and Transformer architectures, it obtains 42.0 mm error on the PA-MPJPE metric of the challenging 3DPW, outperforming state-of-the-art counterparts by a large margin. Code will be publicly available at https://github.com/yangsenius/INT_HMR_Model
RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation
Nov 17, 2020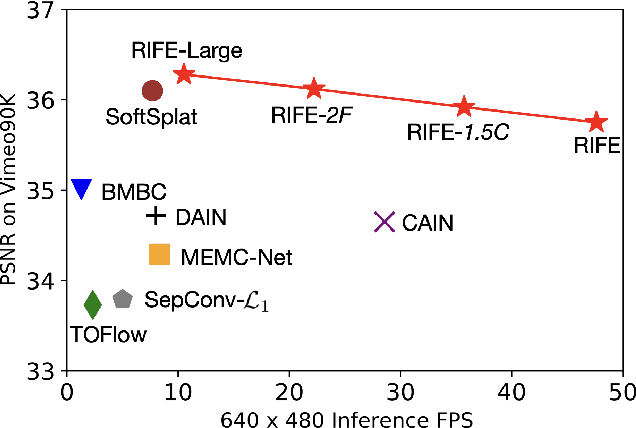

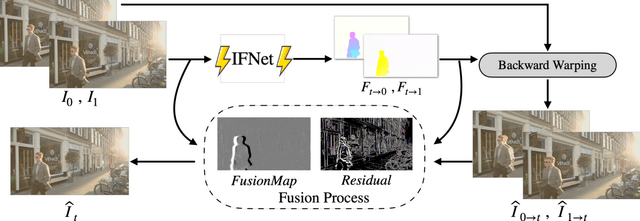
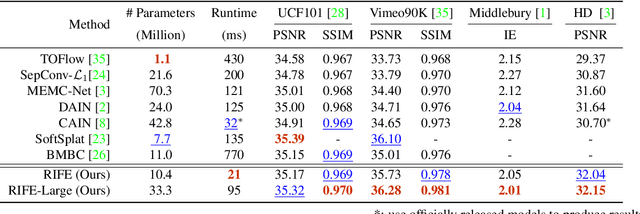
We propose RIFE, a Real-time Intermediate Flow Estimation algorithm for Video Frame Interpolation (VFI). Most existing methods first estimate the bi-directional optical flows and then linearly combine them to approximate intermediate flows, leading to artifacts on motion boundaries. RIFE uses a neural network named IFNet that can directly estimate the intermediate flows from images. With the more precise flows and our simplified fusion process, RIFE can improve interpolation quality and have much better speed. Based on our proposed leakage distillation loss, RIFE can be trained in an end-to-end fashion. Experiments demonstrate that our method is significantly faster than existing VFI methods and can achieve state-of-the-art performance on public benchmarks. The code is available at https://github.com/hzwer/arXiv2020-RIFE.
Single Path One-Shot Neural Architecture Search with Uniform Sampling
Apr 06, 2019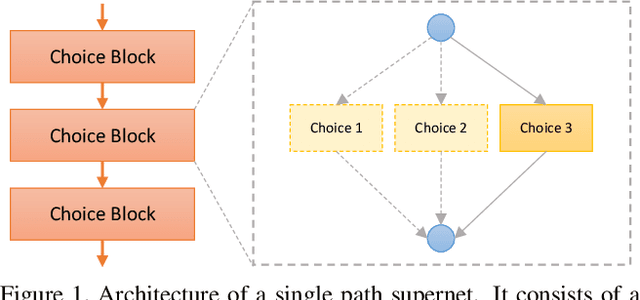
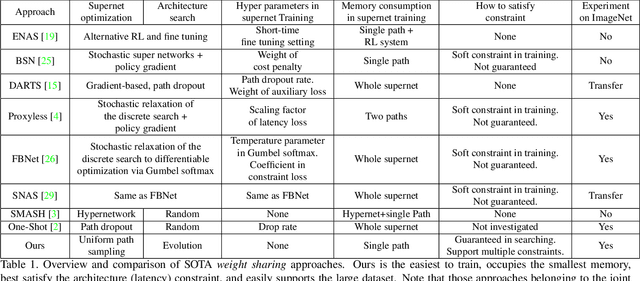
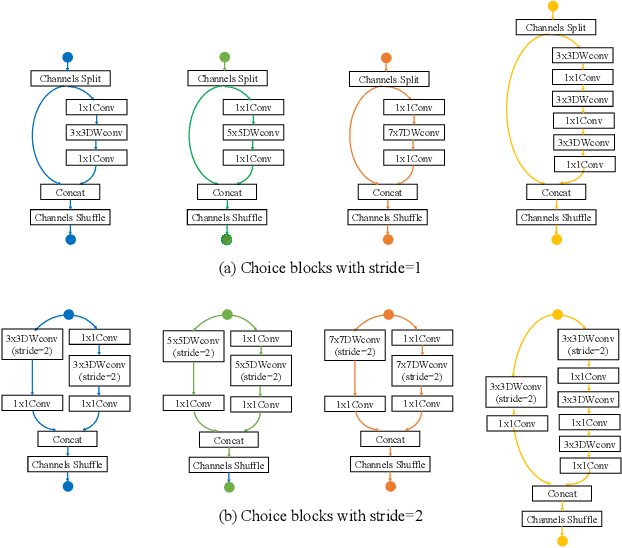
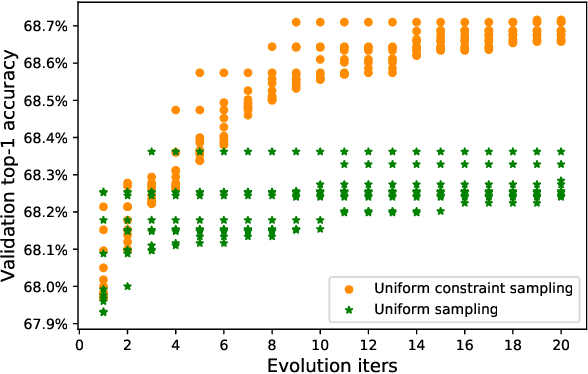
One-shot method is a powerful Neural Architecture Search (NAS) framework, but its training is non-trivial and it is difficult to achieve competitive results on large scale datasets like ImageNet. In this work, we propose a Single Path One-Shot model to address its main challenge in the training. Our central idea is to construct a simplified supernet, Single Path Supernet, which is trained by an uniform path sampling method. All underlying architectures (and their weights) get trained fully and equally. Once we have a trained supernet, we apply an evolutionary algorithm to efficiently search the best-performing architectures without any fine tuning. Comprehensive experiments verify that our approach is flexible and effective. It is easy to train and fast to search. It effortlessly supports complex search spaces (e.g., building blocks, channel, mixed-precision quantization) and different search constraints (e.g., FLOPs, latency). It is thus convenient to use for various needs. It achieves start-of-the-art performance on the large dataset ImageNet.
Learning to Paint with Model-based Deep Reinforcement Learning
Mar 22, 2019


We show how to teach machines to paint like human painters, who can use a few strokes to create fantastic paintings. By combining the neural renderer and model-based Deep Reinforcement Learning (DRL), our agent can decompose texture-rich images into strokes and make long-term plans. For each stroke, the agent directly determines the position and color of the stroke. Excellent visual effect can be achieved using hundreds of strokes. The training process does not require experience of human painting or stroke tracking data.
Stroke-based Character Reconstruction
Oct 17, 2018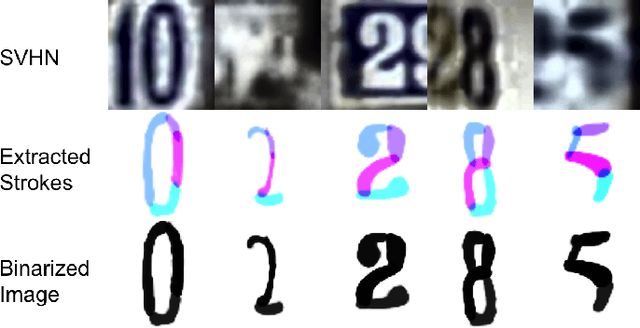
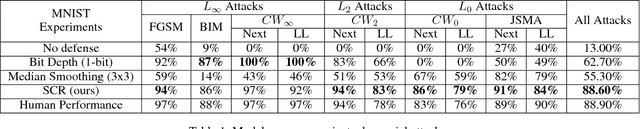
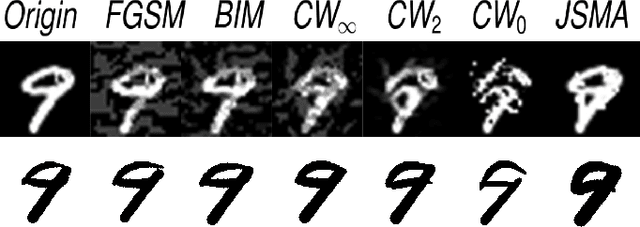
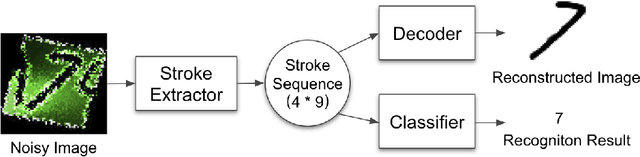
Character reconstruction for noisy character images or character images from real scene is still a challenging problem, due to the bewildering backgrounds, uneven illumination, low resolution and different distortions. We propose a stroke-based character reconstruction(SCR) method that use a weighted quadratic Bezier curve(WQBC) to represent strokes of a character. Only training on our synthetic data, our stroke extractor can achieve excellent reconstruction effect in real scenes. Meanwhile. It can also help achieve great ability in defending adversarial attacks of character recognizers.
Harmonic Adversarial Attack Method
Aug 08, 2018
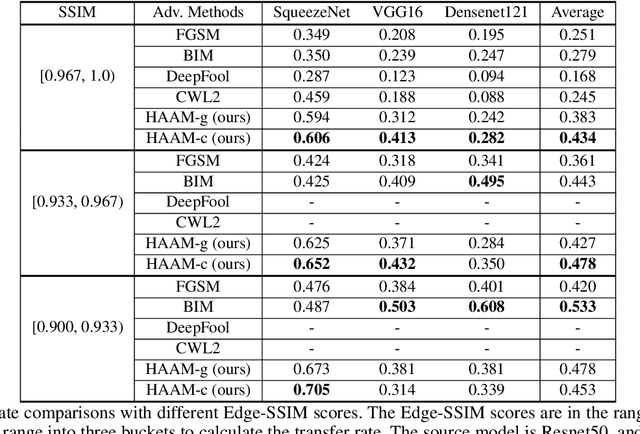

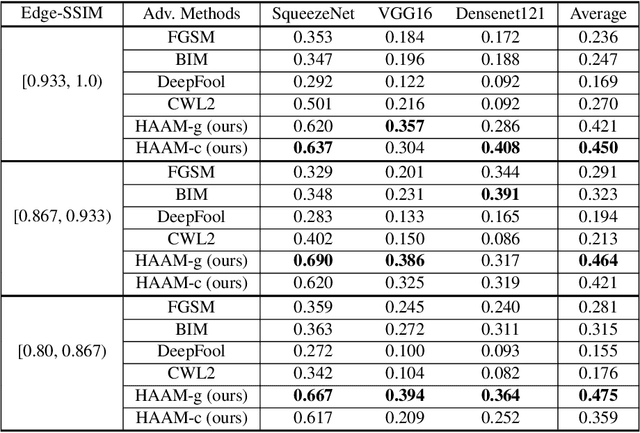
Adversarial attacks find perturbations that can fool models into misclassifying images. Previous works had successes in generating noisy/edge-rich adversarial perturbations, at the cost of degradation of image quality. Such perturbations, even when they are small in scale, are usually easily spottable by human vision. In contrast, we propose Harmonic Adversar- ial Attack Methods (HAAM), that generates edge-free perturbations by using harmonic functions. The property of edge-free guarantees that the generated adversarial images can still preserve visual quality, even when perturbations are of large magnitudes. Experiments also show that adversaries generated by HAAM often have higher rates of success when transferring between models. In addition, we find harmonic perturbations can simulate natural phenomena like natural lighting and shadows. It would then be possible to help find corner cases for given models, as a first step to improving them.