 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
DockSmith: Scaling Reliable Coding Environments via an Agentic Docker Builder
Jan 31, 2026Reliable Docker-based environment construction is a dominant bottleneck for scaling execution-grounded training and evaluation of software engineering agents. We introduce DockSmith, a specialized agentic Docker builder designed to address this challenge. DockSmith treats environment construction not only as a preprocessing step, but as a core agentic capability that exercises long-horizon tool use, dependency reasoning, and failure recovery, yielding supervision that transfers beyond Docker building itself. DockSmith is trained on large-scale, execution-grounded Docker-building trajectories produced by a SWE-Factory-style pipeline augmented with a loop-detection controller and a cross-task success memory. Training a 30B-A3B model on these trajectories achieves open-source state-of-the-art performance on Multi-Docker-Eval, with 39.72% Fail-to-Pass and 58.28% Commit Rate. Moreover, DockSmith improves out-of-distribution performance on SWE-bench Verified, SWE-bench Multilingual, and Terminal-Bench 2.0, demonstrating broader agentic benefits of environment construction.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Jan 09, 2026We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary language models: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025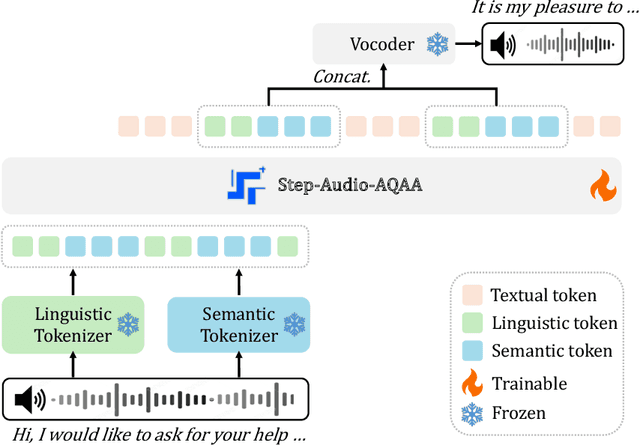
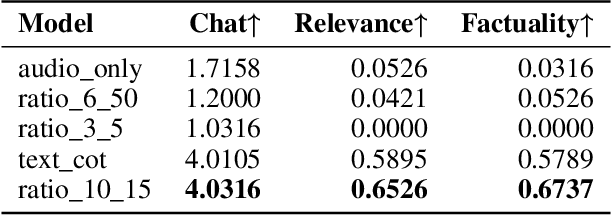
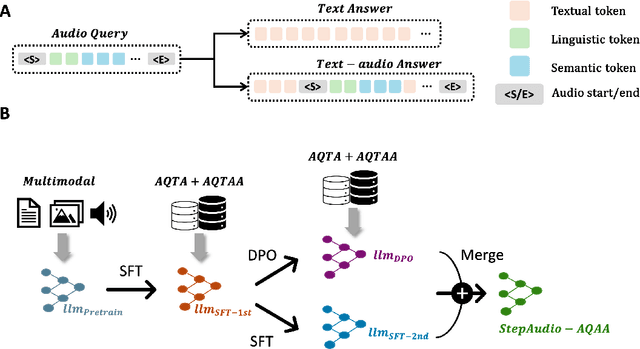

Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
ViStoryBench: Comprehensive Benchmark Suite for Story Visualization
May 30, 2025Story visualization, which aims to generate a sequence of visually coherent images aligning with a given narrative and reference images, has seen significant progress with recent advancements in generative models. To further enhance the performance of story visualization frameworks in real-world scenarios, we introduce a comprehensive evaluation benchmark, ViStoryBench. We collect a diverse dataset encompassing various story types and artistic styles, ensuring models are evaluated across multiple dimensions such as different plots (e.g., comedy, horror) and visual aesthetics (e.g., anime, 3D renderings). ViStoryBench is carefully curated to balance narrative structures and visual elements, featuring stories with single and multiple protagonists to test models' ability to maintain character consistency. Additionally, it includes complex plots and intricate world-building to challenge models in generating accurate visuals. To ensure comprehensive comparisons, our benchmark incorporates a wide range of evaluation metrics assessing critical aspects. This structured and multifaceted framework enables researchers to thoroughly identify both the strengths and weaknesses of different models, fostering targeted improvements.
Advancing Video Self-Supervised Learning via Image Foundation Models
May 25, 2025In the past decade, image foundation models (IFMs) have achieved unprecedented progress. However, the potential of directly using IFMs for video self-supervised representation learning has largely been overlooked. In this study, we propose an advancing video self-supervised learning (AdViSe) approach, aimed at significantly reducing the training overhead of video representation models using pre-trained IFMs. Specifically, we first introduce temporal modeling modules (ResNet3D) to IFMs, constructing a video representation model. We then employ a video self-supervised learning approach, playback rate perception, to train temporal modules while freezing the IFM components. Experiments on UCF101 demonstrate that AdViSe achieves performance comparable to state-of-the-art methods while reducing training time by $3.4\times$ and GPU memory usage by $8.2\times$. This study offers fresh insights into low-cost video self-supervised learning based on pre-trained IFMs. Code is available at https://github.com/JingwWu/advise-video-ssl.
DialogueReason: Rule-Based RL Sparks Dialogue Reasoning in LLMs
May 11, 2025We propose DialogueReason, a reasoning paradigm that uncovers the lost roles in monologue-style reasoning models, aiming to boost diversity and coherency of the reasoning process. Recent advances in RL-based large reasoning models have led to impressive long CoT capabilities and high performance on math and science benchmarks. However, these reasoning models rely mainly on monologue-style reasoning, which often limits reasoning diversity and coherency, frequently recycling fixed strategies or exhibiting unnecessary shifts in attention. Our work consists of an analysis of monologue reasoning patterns and the development of a dialogue-based reasoning approach. We first introduce the Compound-QA task, which concatenates multiple problems into a single prompt to assess both diversity and coherency of reasoning. Our analysis shows that Compound-QA exposes weaknesses in monologue reasoning, evidenced by both quantitative metrics and qualitative reasoning traces. Building on the analysis, we propose a dialogue-based reasoning, named DialogueReason, structured around agents, environment, and interactions. Using PPO with rule-based rewards, we train open-source LLMs (Qwen-QWQ and Qwen-Base) to adopt dialogue reasoning. We evaluate trained models on MATH, AIME, and GPQA datasets, showing that the dialogue reasoning model outperforms monologue models under more complex compound questions. Additionally, we discuss how dialogue-based reasoning helps enhance interpretability, facilitate more intuitive human interaction, and inspire advances in multi-agent system design.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Advancing Auto-Regressive Continuation for Video Frames
Dec 04, 2024



Recent advances in auto-regressive large language models (LLMs) have shown their potential in generating high-quality text, inspiring researchers to apply them to image and video generation. This paper explores the application of LLMs to video continuation, a task essential for building world models and predicting future frames. In this paper, we tackle challenges including preventing degeneration in long-term frame generation and enhancing the quality of generated images. We design a scheme named ARCON, which involves training our model to alternately generate semantic tokens and RGB tokens, enabling the LLM to explicitly learn and predict the high-level structural information of the video. We find high consistency in the RGB images and semantic maps generated without special design. Moreover, we employ an optical flow-based texture stitching method to enhance the visual quality of the generated videos. Quantitative and qualitative experiments in autonomous driving scenarios demonstrate our model can consistently generate long videos.