 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccTENS: 3D Occupancy World Model via Temporal Next-Scale Prediction
Sep 04, 2025In this paper, we propose OccTENS, a generative occupancy world model that enables controllable, high-fidelity long-term occupancy generation while maintaining computational efficiency. Different from visual generation, the occupancy world model must capture the fine-grained 3D geometry and dynamic evolution of the 3D scenes, posing great challenges for the generative models. Recent approaches based on autoregression (AR) have demonstrated the potential to predict vehicle movement and future occupancy scenes simultaneously from historical observations, but they typically suffer from \textbf{inefficiency}, \textbf{temporal degradation} in long-term generation and \textbf{lack of controllability}. To holistically address these issues, we reformulate the occupancy world model as a temporal next-scale prediction (TENS) task, which decomposes the temporal sequence modeling problem into the modeling of spatial scale-by-scale generation and temporal scene-by-scene prediction. With a \textbf{TensFormer}, OccTENS can effectively manage the temporal causality and spatial relationships of occupancy sequences in a flexible and scalable way. To enhance the pose controllability, we further propose a holistic pose aggregation strategy, which features a unified sequence modeling for occupancy and ego-motion. Experiments show that OccTENS outperforms the state-of-the-art method with both higher occupancy quality and faster inference time.
MGVQ: Could VQ-VAE Beat VAE? A Generalizable Tokenizer with Multi-group Quantization
Jul 10, 2025



Vector Quantized Variational Autoencoders (VQ-VAEs) are fundamental models that compress continuous visual data into discrete tokens. Existing methods have tried to improve the quantization strategy for better reconstruction quality, however, there still exists a large gap between VQ-VAEs and VAEs. To narrow this gap, we propose \NickName, a novel method to augment the representation capability of discrete codebooks, facilitating easier optimization for codebooks and minimizing information loss, thereby enhancing reconstruction quality. Specifically, we propose to retain the latent dimension to preserve encoded features and incorporate a set of sub-codebooks for quantization. Furthermore, we construct comprehensive zero-shot benchmarks featuring resolutions of 512p and 2k to evaluate the reconstruction performance of existing methods rigorously. \NickName~achieves the \textbf{state-of-the-art performance on both ImageNet and $8$ zero-shot benchmarks} across all VQ-VAEs. Notably, compared with SD-VAE, we outperform them on ImageNet significantly, with rFID $\textbf{0.49}$ v.s. $\textbf{0.91}$, and achieve superior PSNR on all zero-shot benchmarks. These results highlight the superiority of \NickName~in reconstruction and pave the way for preserving fidelity in HD image processing tasks. Code will be publicly available at https://github.com/MKJia/MGVQ.
DrivingWorld: Constructing World Model for Autonomous Driving via Video GPT
Dec 30, 2024



Recent successes in autoregressive (AR) generation models, such as the GPT series in natural language processing, have motivated efforts to replicate this success in visual tasks. Some works attempt to extend this approach to autonomous driving by building video-based world models capable of generating realistic future video sequences and predicting ego states. However, prior works tend to produce unsatisfactory results, as the classic GPT framework is designed to handle 1D contextual information, such as text, and lacks the inherent ability to model the spatial and temporal dynamics essential for video generation. In this paper, we present DrivingWorld, a GPT-style world model for autonomous driving, featuring several spatial-temporal fusion mechanisms. This design enables effective modeling of both spatial and temporal dynamics, facilitating high-fidelity, long-duration video generation. Specifically, we propose a next-state prediction strategy to model temporal coherence between consecutive frames and apply a next-token prediction strategy to capture spatial information within each frame. To further enhance generalization ability, we propose a novel masking strategy and reweighting strategy for token prediction to mitigate long-term drifting issues and enable precise control. Our work demonstrates the ability to produce high-fidelity and consistent video clips of over 40 seconds in duration, which is over 2 times longer than state-of-the-art driving world models. Experiments show that, in contrast to prior works, our method achieves superior visual quality and significantly more accurate controllable future video generation. Our code is available at https://github.com/YvanYin/DrivingWorld.
DrivingWorld: ConstructingWorld Model for Autonomous Driving via Video GPT
Dec 27, 2024Recent successes in autoregressive (AR) generation models, such as the GPT series in natural language processing, have motivated efforts to replicate this success in visual tasks. Some works attempt to extend this approach to autonomous driving by building video-based world models capable of generating realistic future video sequences and predicting ego states. However, prior works tend to produce unsatisfactory results, as the classic GPT framework is designed to handle 1D contextual information, such as text, and lacks the inherent ability to model the spatial and temporal dynamics essential for video generation. In this paper, we present DrivingWorld, a GPT-style world model for autonomous driving, featuring several spatial-temporal fusion mechanisms. This design enables effective modeling of both spatial and temporal dynamics, facilitating high-fidelity, long-duration video generation. Specifically, we propose a next-state prediction strategy to model temporal coherence between consecutive frames and apply a next-token prediction strategy to capture spatial information within each frame. To further enhance generalization ability, we propose a novel masking strategy and reweighting strategy for token prediction to mitigate long-term drifting issues and enable precise control. Our work demonstrates the ability to produce high-fidelity and consistent video clips of over 40 seconds in duration, which is over 2 times longer than state-of-the-art driving world models. Experiments show that, in contrast to prior works, our method achieves superior visual quality and significantly more accurate controllable future video generation. Our code is available at https://github.com/YvanYin/DrivingWorld.
Boost 3D Reconstruction using Diffusion-based Monocular Camera Calibration
Nov 26, 2024



In this paper, we present DM-Calib, a diffusion-based approach for estimating pinhole camera intrinsic parameters from a single input image. Monocular camera calibration is essential for many 3D vision tasks. However, most existing methods depend on handcrafted assumptions or are constrained by limited training data, resulting in poor generalization across diverse real-world images. Recent advancements in stable diffusion models, trained on massive data, have shown the ability to generate high-quality images with varied characteristics. Emerging evidence indicates that these models implicitly capture the relationship between camera focal length and image content. Building on this insight, we explore how to leverage the powerful priors of diffusion models for monocular pinhole camera calibration. Specifically, we introduce a new image-based representation, termed Camera Image, which losslessly encodes the numerical camera intrinsics and integrates seamlessly with the diffusion framework. Using this representation, we reformulate the problem of estimating camera intrinsics as the generation of a dense Camera Image conditioned on an input image. By fine-tuning a stable diffusion model to generate a Camera Image from a single RGB input, we can extract camera intrinsics via a RANSAC operation. We further demonstrate that our monocular calibration method enhances performance across various 3D tasks, including zero-shot metric depth estimation, 3D metrology, pose estimation and sparse-view reconstruction. Extensive experiments on multiple public datasets show that our approach significantly outperforms baselines and provides broad benefits to 3D vision tasks. Code is available at https://github.com/JunyuanDeng/DM-Calib.
Task-Aware Dynamic Transformer for Efficient Arbitrary-Scale Image Super-Resolution
Aug 16, 2024



Arbitrary-scale super-resolution (ASSR) aims to learn a single model for image super-resolution at arbitrary magnifying scales. Existing ASSR networks typically comprise an off-the-shelf scale-agnostic feature extractor and an arbitrary scale upsampler. These feature extractors often use fixed network architectures to address different ASSR inference tasks, each of which is characterized by an input image and an upsampling scale. However, this overlooks the difficulty variance of super-resolution on different inference scenarios, where simple images or small SR scales could be resolved with less computational effort than difficult images or large SR scales. To tackle this difficulty variability, in this paper, we propose a Task-Aware Dynamic Transformer (TADT) as an input-adaptive feature extractor for efficient image ASSR. Our TADT consists of a multi-scale feature extraction backbone built upon groups of Multi-Scale Transformer Blocks (MSTBs) and a Task-Aware Routing Controller (TARC). The TARC predicts the inference paths within feature extraction backbone, specifically selecting MSTBs based on the input images and SR scales. The prediction of inference path is guided by a new loss function to trade-off the SR accuracy and efficiency. Experiments demonstrate that, when working with three popular arbitrary-scale upsamplers, our TADT achieves state-of-the-art ASSR performance when compared with mainstream feature extractors, but with relatively fewer computational costs. The code will be publicly released.
Scale-Adaptive Feature Aggregation for Efficient Space-Time Video Super-Resolution
Oct 26, 2023The Space-Time Video Super-Resolution (STVSR) task aims to enhance the visual quality of videos, by simultaneously performing video frame interpolation (VFI) and video super-resolution (VSR). However, facing the challenge of the additional temporal dimension and scale inconsistency, most existing STVSR methods are complex and inflexible in dynamically modeling different motion amplitudes. In this work, we find that choosing an appropriate processing scale achieves remarkable benefits in flow-based feature propagation. We propose a novel Scale-Adaptive Feature Aggregation (SAFA) network that adaptively selects sub-networks with different processing scales for individual samples. Experiments on four public STVSR benchmarks demonstrate that SAFA achieves state-of-the-art performance. Our SAFA network outperforms recent state-of-the-art methods such as TMNet and VideoINR by an average improvement of over 0.5dB on PSNR, while requiring less than half the number of parameters and only 1/3 computational costs.
Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Constraints
Oct 09, 2023



Text-driven 3D indoor scene generation could be useful for gaming, film industry, and AR/VR applications. However, existing methods cannot faithfully capture the room layout, nor do they allow flexible editing of individual objects in the room. To address these problems, we present Ctrl-Room, which is able to generate convincing 3D rooms with designer-style layouts and high-fidelity textures from just a text prompt. Moreover, Ctrl-Room enables versatile interactive editing operations such as resizing or moving individual furniture items. Our key insight is to separate the modeling of layouts and appearance. %how to model the room that takes into account both scene texture and geometry at the same time. To this end, Our proposed method consists of two stages, a `Layout Generation Stage' and an `Appearance Generation Stage'. The `Layout Generation Stage' trains a text-conditional diffusion model to learn the layout distribution with our holistic scene code parameterization. Next, the `Appearance Generation Stage' employs a fine-tuned ControlNet to produce a vivid panoramic image of the room guided by the 3D scene layout and text prompt. In this way, we achieve a high-quality 3D room with convincing layouts and lively textures. Benefiting from the scene code parameterization, we can easily edit the generated room model through our mask-guided editing module, without expensive editing-specific training. Extensive experiments on the Structured3D dataset demonstrate that our method outperforms existing methods in producing more reasonable, view-consistent, and editable 3D rooms from natural language prompts.
A Dynamic Multi-Scale Voxel Flow Network for Video Prediction
Mar 24, 2023The performance of video prediction has been greatly boosted by advanced deep neural networks. However, most of the current methods suffer from large model sizes and require extra inputs, e.g., semantic/depth maps, for promising performance. For efficiency consideration, in this paper, we propose a Dynamic Multi-scale Voxel Flow Network (DMVFN) to achieve better video prediction performance at lower computational costs with only RGB images, than previous methods. The core of our DMVFN is a differentiable routing module that can effectively perceive the motion scales of video frames. Once trained, our DMVFN selects adaptive sub-networks for different inputs at the inference stage. Experiments on several benchmarks demonstrate that our DMVFN is an order of magnitude faster than Deep Voxel Flow and surpasses the state-of-the-art iterative-based OPT on generated image quality. Our code and demo are available at https://huxiaotaostasy.github.io/DMVFN/.
Semi-Cycled Generative Adversarial Networks for Real-World Face Super-Resolution
May 08, 2022
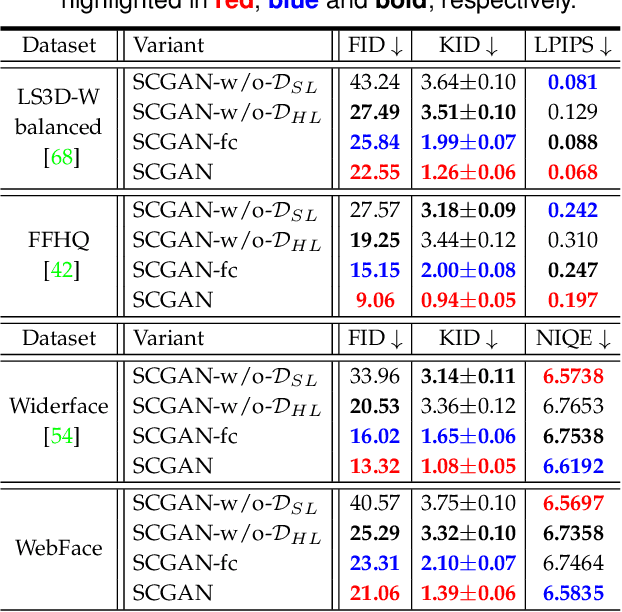

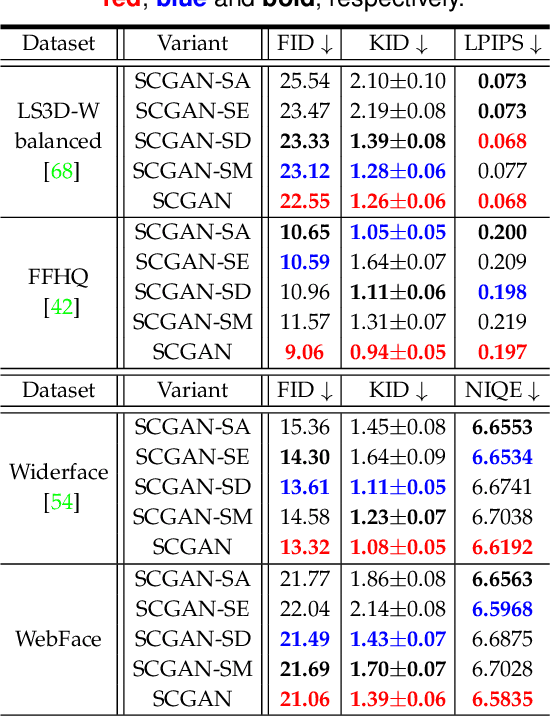
Real-world face super-resolution (SR) is a highly ill-posed image restoration task. The fully-cycled Cycle-GAN architecture is widely employed to achieve promising performance on face SR, but prone to produce artifacts upon challenging cases in real-world scenarios, since joint participation in the same degradation branch will impact final performance due to huge domain gap between real-world and synthetic LR ones obtained by generators. To better exploit the powerful generative capability of GAN for real-world face SR, in this paper, we establish two independent degradation branches in the forward and backward cycle-consistent reconstruction processes, respectively, while the two processes share the same restoration branch. Our Semi-Cycled Generative Adversarial Networks (SCGAN) is able to alleviate the adverse effects of the domain gap between the real-world LR face images and the synthetic LR ones, and to achieve accurate and robust face SR performance by the shared restoration branch regularized by both the forward and backward cycle-consistent learning processes. Experiments on two synthetic and two real-world datasets demonstrate that, our SCGAN outperforms the state-of-the-art methods on recovering the face structures/details and quantitative metrics for real-world face SR. The code will be publicly released at https://github.com/HaoHou-98/SCGAN.