 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Dynamic Transformer for Efficient Arbitrary-Scale Image Super-Resolution
Aug 16, 2024



Arbitrary-scale super-resolution (ASSR) aims to learn a single model for image super-resolution at arbitrary magnifying scales. Existing ASSR networks typically comprise an off-the-shelf scale-agnostic feature extractor and an arbitrary scale upsampler. These feature extractors often use fixed network architectures to address different ASSR inference tasks, each of which is characterized by an input image and an upsampling scale. However, this overlooks the difficulty variance of super-resolution on different inference scenarios, where simple images or small SR scales could be resolved with less computational effort than difficult images or large SR scales. To tackle this difficulty variability, in this paper, we propose a Task-Aware Dynamic Transformer (TADT) as an input-adaptive feature extractor for efficient image ASSR. Our TADT consists of a multi-scale feature extraction backbone built upon groups of Multi-Scale Transformer Blocks (MSTBs) and a Task-Aware Routing Controller (TARC). The TARC predicts the inference paths within feature extraction backbone, specifically selecting MSTBs based on the input images and SR scales. The prediction of inference path is guided by a new loss function to trade-off the SR accuracy and efficiency. Experiments demonstrate that, when working with three popular arbitrary-scale upsamplers, our TADT achieves state-of-the-art ASSR performance when compared with mainstream feature extractors, but with relatively fewer computational costs. The code will be publicly released.
Mutual Information Gradient Estimation for Representation Learning
May 03, 2020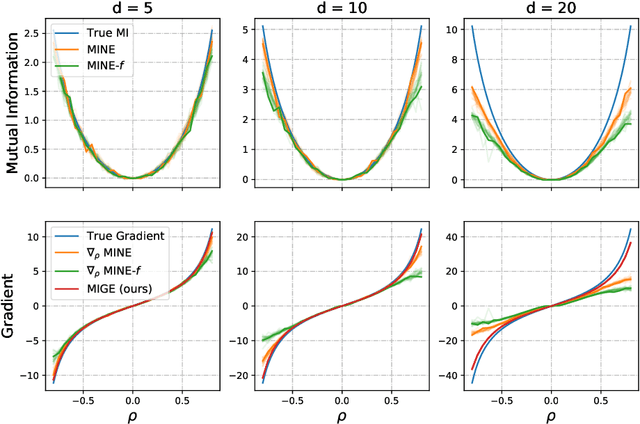
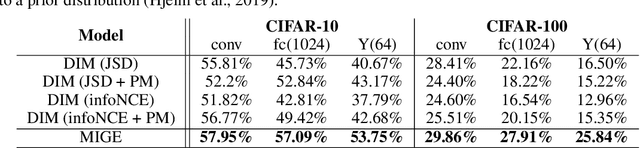
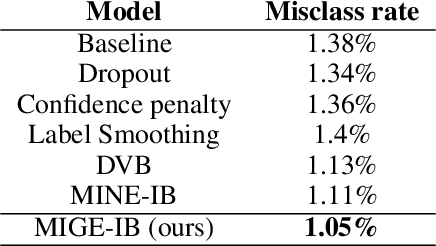
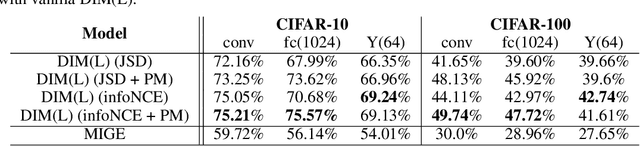
Mutual Information (MI) plays an important role in representation learning. However, MI is unfortunately intractable in continuous and high-dimensional settings. Recent advances establish tractable and scalable MI estimators to discover useful representation. However, most of the existing methods are not capable of providing an accurate estimation of MI with low-variance when the MI is large. We argue that directly estimating the gradients of MI is more appealing for representation learning than estimating MI in itself. To this end, we propose the Mutual Information Gradient Estimator (MIGE) for representation learning based on the score estimation of implicit distributions. MIGE exhibits a tight and smooth gradient estimation of MI in the high-dimensional and large-MI settings. We expand the applications of MIGE in both unsupervised learning of deep representations based on InfoMax and the Information Bottleneck method. Experimental results have indicated significant performance improvement in learning useful representation.