 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEGRL-TKGR: A Causal Enhanced Graph Representation Learning Framework for Improving Temporal Knowledge Graph Extrapolation Reasoning
Aug 15, 2024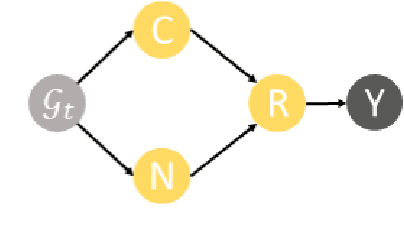
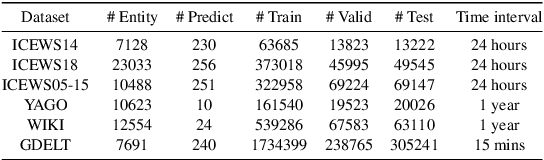
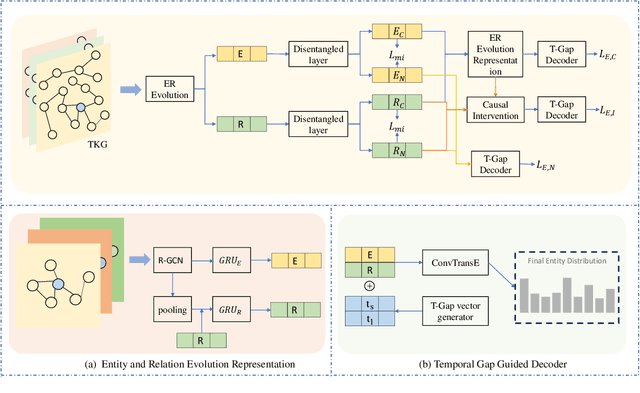
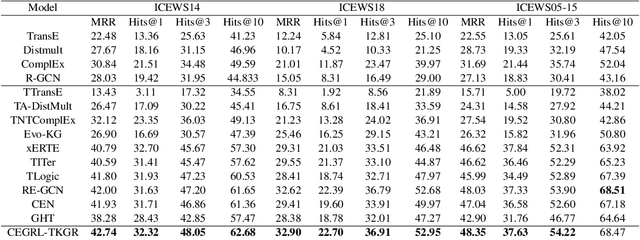
Temporal knowledge graph reasoning (TKGR) is increasingly gaining attention for its ability to extrapolate new events from historical data, thereby enriching the inherently incomplete temporal knowledge graphs. Existing graph-based representation learning frameworks have made significant strides in developing evolving representations for both entities and relational embeddings. Despite these achievements, there's a notable tendency in these models to inadvertently learn biased data representations and mine spurious correlations, consequently failing to discern the causal relationships between events. This often leads to incorrect predictions based on these false correlations. To address this, we propose an innovative causal enhanced graph representation learning framework for TKGR (named CEGRL-TKGR). This framework introduces causal structures in graph-based representation learning to unveil the essential causal relationships between events, ultimately enhancing task performance. Specifically, we first disentangle the evolutionary representations of entities and relations in a temporal graph sequence into two distinct components, namely causal representations and confounding representations. Then, drawing on causal intervention theory, we advocate the utilization of causal representations for predictions, aiming to mitigate the effects of erroneous correlations caused by confounding features, thus achieving more robust and accurate predictions. Finally, extensive experimental results on six benchmark datasets demonstrate the superior performance of our model in the link prediction task.
Generative Oversampling for Imbalanced Data via Majority-Guided VAE
Feb 14, 2023



Learning with imbalanced data is a challenging problem in deep learning. Over-sampling is a widely used technique to re-balance the sampling distribution of training data. However, most existing over-sampling methods only use intra-class information of minority classes to augment the data but ignore the inter-class relationships with the majority ones, which is prone to overfitting, especially when the imbalance ratio is large. To address this issue, we propose a novel over-sampling model, called Majority-Guided VAE~(MGVAE), which generates new minority samples under the guidance of a majority-based prior. In this way, the newly generated minority samples can inherit the diversity and richness of the majority ones, thus mitigating overfitting in downstream tasks. Furthermore, to prevent model collapse under limited data, we first pre-train MGVAE on sufficient majority samples and then fine-tune based on minority samples with Elastic Weight Consolidation(EWC) regularization. Experimental results on benchmark image datasets and real-world tabular data show that MGVAE achieves competitive improvements over other over-sampling methods in downstream classification tasks, demonstrating the effectiveness of our method.
ByPE-VAE: Bayesian Pseudocoresets Exemplar VAE
Jul 30, 2021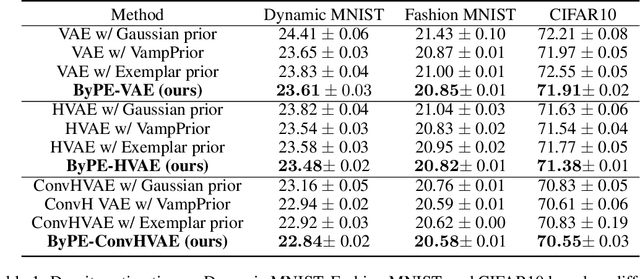
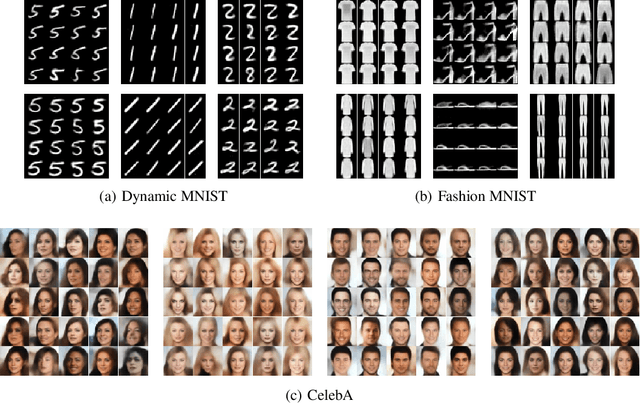


Recent studies show that advanced priors play a major role in deep generative models. Exemplar VAE, as a variant of VAE with an exemplar-based prior, has achieved impressive results. However, due to the nature of model design, an exemplar-based model usually requires vast amounts of data to participate in training, which leads to huge computational complexity. To address this issue, we propose Bayesian Pseudocoresets Exemplar VAE (ByPE-VAE), a new variant of VAE with a prior based on Bayesian pseudocoreset. The proposed prior is conditioned on a small-scale pseudocoreset rather than the whole dataset for reducing the computational cost and avoiding overfitting. Simultaneously, we obtain the optimal pseudocoreset via a stochastic optimization algorithm during VAE training aiming to minimize the Kullback-Leibler divergence between the prior based on the pseudocoreset and that based on the whole dataset. Experimental results show that ByPE-VAE can achieve competitive improvements over the state-of-the-art VAEs in the tasks of density estimation, representation learning, and generative data augmentation. Particularly, on a basic VAE architecture, ByPE-VAE is up to 3 times faster than Exemplar VAE while almost holding the performance. Code is available at our supplementary materials.
Mutual Information Gradient Estimation for Representation Learning
May 03, 2020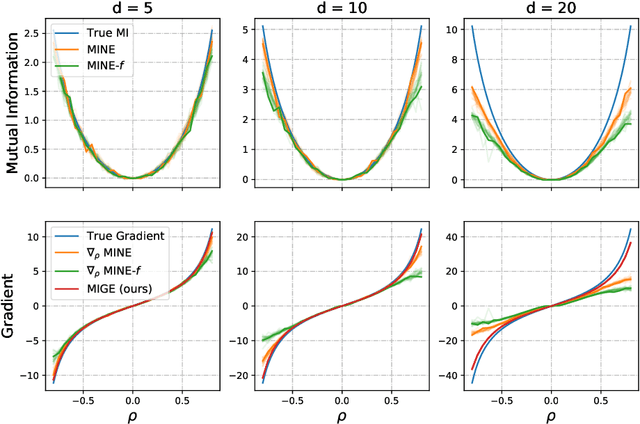
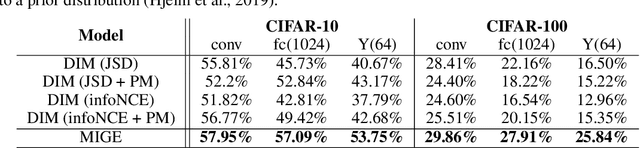
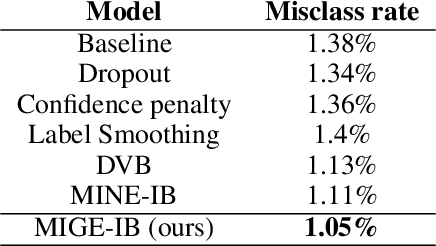
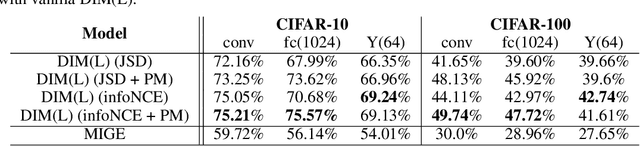
Mutual Information (MI) plays an important role in representation learning. However, MI is unfortunately intractable in continuous and high-dimensional settings. Recent advances establish tractable and scalable MI estimators to discover useful representation. However, most of the existing methods are not capable of providing an accurate estimation of MI with low-variance when the MI is large. We argue that directly estimating the gradients of MI is more appealing for representation learning than estimating MI in itself. To this end, we propose the Mutual Information Gradient Estimator (MIGE) for representation learning based on the score estimation of implicit distributions. MIGE exhibits a tight and smooth gradient estimation of MI in the high-dimensional and large-MI settings. We expand the applications of MIGE in both unsupervised learning of deep representations based on InfoMax and the Information Bottleneck method. Experimental results have indicated significant performance improvement in learning useful representation.
Deep Minimax Probability Machine
Nov 20, 2019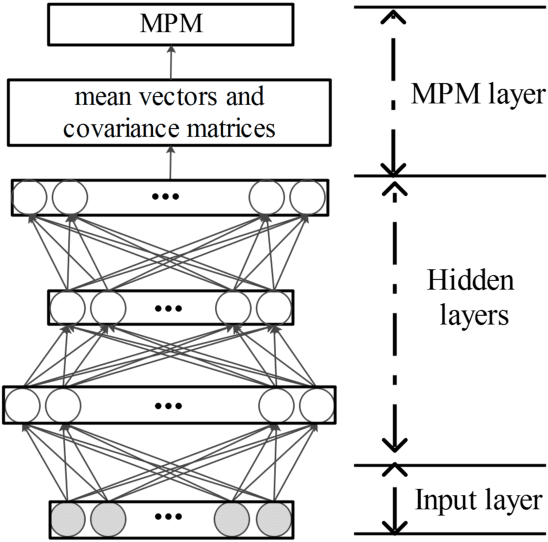
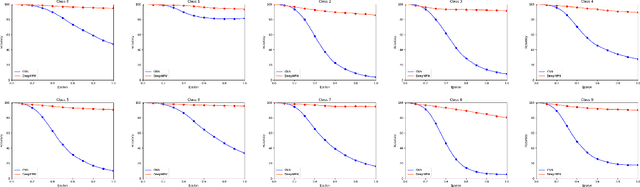
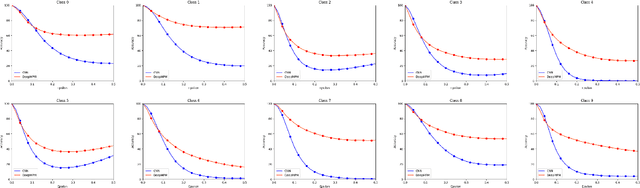
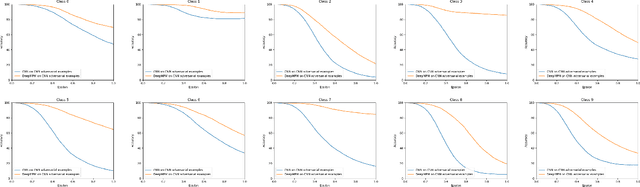
Deep neural networks enjoy a powerful representation and have proven effective in a number of applications. However, recent advances show that deep neural networks are vulnerable to adversarial attacks incurred by the so-called adversarial examples. Although the adversarial example is only slightly different from the input sample, the neural network classifies it as the wrong class. In order to alleviate this problem, we propose the Deep Minimax Probability Machine (DeepMPM), which applies MPM to deep neural networks in an end-to-end fashion. In a worst-case scenario, MPM tries to minimize an upper bound of misclassification probabilities, considering the global information (i.e., mean and covariance information of each class). DeepMPM can be more robust since it learns the worst-case bound on the probability of misclassification of future data. Experiments on two real-world datasets can achieve comparable classification performance with CNN, while can be more robust on adversarial attacks.
Stochastic Sequential Neural Networks with Structured Inference
May 24, 2017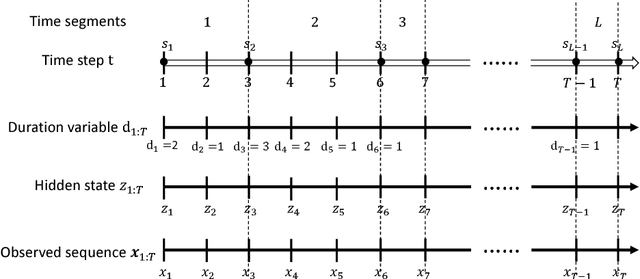

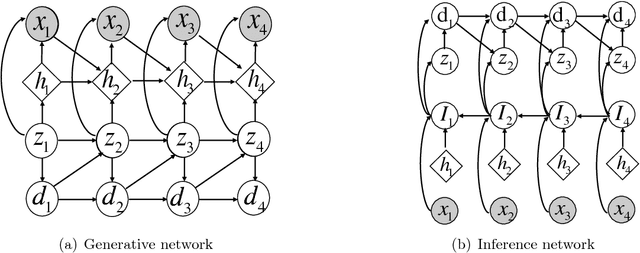
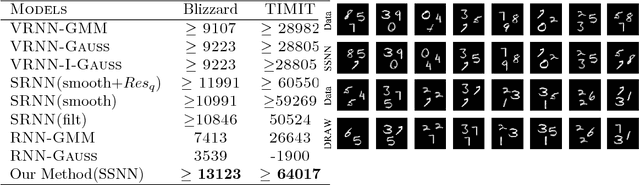
Unsupervised structure learning in high-dimensional time series data has attracted a lot of research interests. For example, segmenting and labelling high dimensional time series can be helpful in behavior understanding and medical diagnosis. Recent advances in generative sequential modeling have suggested to combine recurrent neural networks with state space models (e.g., Hidden Markov Models). This combination can model not only the long term dependency in sequential data, but also the uncertainty included in the hidden states. Inheriting these advantages of stochastic neural sequential models, we propose a structured and stochastic sequential neural network, which models both the long-term dependencies via recurrent neural networks and the uncertainty in the segmentation and labels via discrete random variables. For accurate and efficient inference, we present a bi-directional inference network by reparamterizing the categorical segmentation and labels with the recent proposed Gumbel-Softmax approximation and resort to the Stochastic Gradient Variational Bayes. We evaluate the proposed model in a number of tasks, including speech modeling, automatic segmentation and labeling in behavior understanding, and sequential multi-objects recognition. Experimental results have demonstrated that our proposed model can achieve significant improvement over the state-of-the-art methods.