 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeCNN: Refining Cross-Variable Interaction on Time Point for Time Series Forecasting
Oct 07, 2024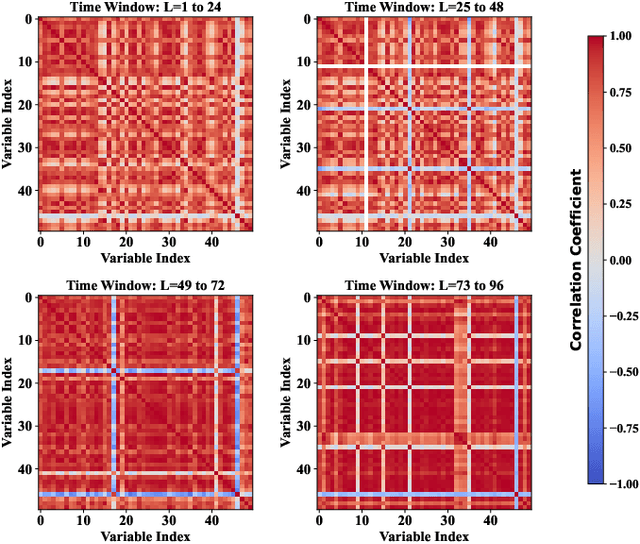
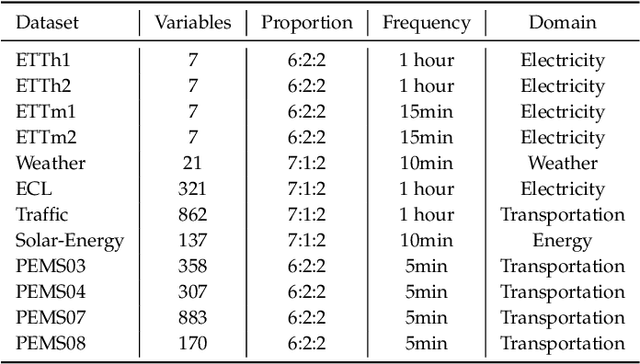
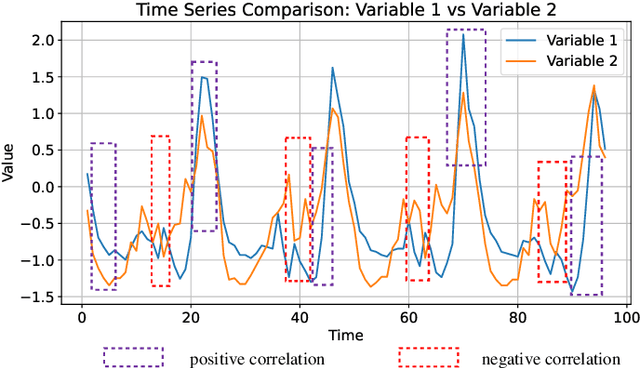
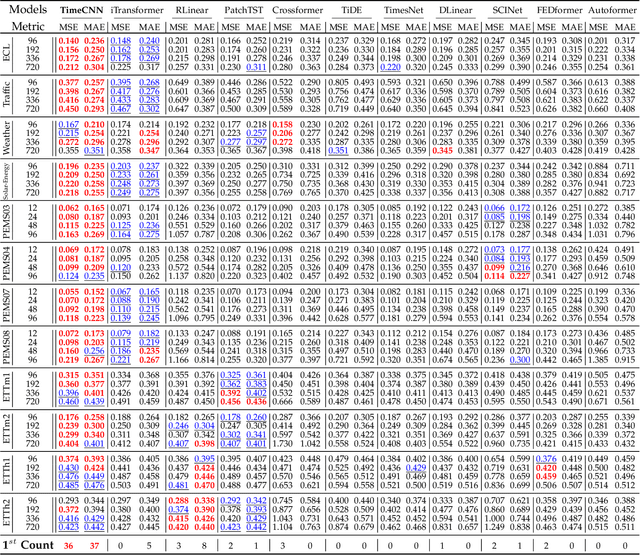
Time series forecasting is extensively applied across diverse domains. Transformer-based models demonstrate significant potential in modeling cross-time and cross-variable interaction. However, we notice that the cross-variable correlation of multivariate time series demonstrates multifaceted (positive and negative correlations) and dynamic progression over time, which is not well captured by existing Transformer-based models. To address this issue, we propose a TimeCNN model to refine cross-variable interactions to enhance time series forecasting. Its key innovation is timepoint-independent, where each time point has an independent convolution kernel, allowing each time point to have its independent model to capture relationships among variables. This approach effectively handles both positive and negative correlations and adapts to the evolving nature of variable relationships over time. Extensive experiments conducted on 12 real-world datasets demonstrate that TimeCNN consistently outperforms state-of-the-art models. Notably, our model achieves significant reductions in computational requirements (approximately 60.46%) and parameter count (about 57.50%), while delivering inference speeds 3 to 4 times faster than the benchmark iTransformer model
MVEB: Self-Supervised Learning with Multi-View Entropy Bottleneck
Mar 28, 2024



Self-supervised learning aims to learn representation that can be effectively generalized to downstream tasks. Many self-supervised approaches regard two views of an image as both the input and the self-supervised signals, assuming that either view contains the same task-relevant information and the shared information is (approximately) sufficient for predicting downstream tasks. Recent studies show that discarding superfluous information not shared between the views can improve generalization. Hence, the ideal representation is sufficient for downstream tasks and contains minimal superfluous information, termed minimal sufficient representation. One can learn this representation by maximizing the mutual information between the representation and the supervised view while eliminating superfluous information. Nevertheless, the computation of mutual information is notoriously intractable. In this work, we propose an objective termed multi-view entropy bottleneck (MVEB) to learn minimal sufficient representation effectively. MVEB simplifies the minimal sufficient learning to maximizing both the agreement between the embeddings of two views and the differential entropy of the embedding distribution. Our experiments confirm that MVEB significantly improves performance. For example, it achieves top-1 accuracy of 76.9\% on ImageNet with a vanilla ResNet-50 backbone on linear evaluation. To the best of our knowledge, this is the new state-of-the-art result with ResNet-50.
Enhancing Multivariate Time Series Forecasting with Mutual Information-driven Cross-Variable and Temporal Modeling
Mar 01, 2024



Recent advancements have underscored the impact of deep learning techniques on multivariate time series forecasting (MTSF). Generally, these techniques are bifurcated into two categories: Channel-independence and Channel-mixing approaches. Although Channel-independence methods typically yield better results, Channel-mixing could theoretically offer improvements by leveraging inter-variable correlations. Nonetheless, we argue that the integration of uncorrelated information in channel-mixing methods could curtail the potential enhancement in MTSF model performance. To substantiate this claim, we introduce the Cross-variable Decorrelation Aware feature Modeling (CDAM) for Channel-mixing approaches, aiming to refine Channel-mixing by minimizing redundant information between channels while enhancing relevant mutual information. Furthermore, we introduce the Temporal correlation Aware Modeling (TAM) to exploit temporal correlations, a step beyond conventional single-step forecasting methods. This strategy maximizes the mutual information between adjacent sub-sequences of both the forecasted and target series. Combining CDAM and TAM, our novel framework significantly surpasses existing models, including those previously considered state-of-the-art, in comprehensive tests.
PDETime: Rethinking Long-Term Multivariate Time Series Forecasting from the perspective of partial differential equations
Feb 25, 2024


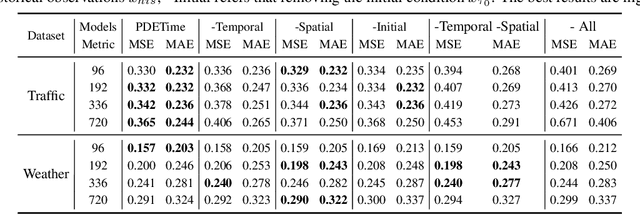
Recent advancements in deep learning have led to the development of various models for long-term multivariate time-series forecasting (LMTF), many of which have shown promising results. Generally, the focus has been on historical-value-based models, which rely on past observations to predict future series. Notably, a new trend has emerged with time-index-based models, offering a more nuanced understanding of the continuous dynamics underlying time series. Unlike these two types of models that aggregate the information of spatial domains or temporal domains, in this paper, we consider multivariate time series as spatiotemporal data regularly sampled from a continuous dynamical system, which can be represented by partial differential equations (PDEs), with the spatial domain being fixed. Building on this perspective, we present PDETime, a novel LMTF model inspired by the principles of Neural PDE solvers, following the encoding-integration-decoding operations. Our extensive experimentation across seven diverse real-world LMTF datasets reveals that PDETime not only adapts effectively to the intrinsic spatiotemporal nature of the data but also sets new benchmarks, achieving state-of-the-art results
Generative Oversampling for Imbalanced Data via Majority-Guided VAE
Feb 14, 2023



Learning with imbalanced data is a challenging problem in deep learning. Over-sampling is a widely used technique to re-balance the sampling distribution of training data. However, most existing over-sampling methods only use intra-class information of minority classes to augment the data but ignore the inter-class relationships with the majority ones, which is prone to overfitting, especially when the imbalance ratio is large. To address this issue, we propose a novel over-sampling model, called Majority-Guided VAE~(MGVAE), which generates new minority samples under the guidance of a majority-based prior. In this way, the newly generated minority samples can inherit the diversity and richness of the majority ones, thus mitigating overfitting in downstream tasks. Furthermore, to prevent model collapse under limited data, we first pre-train MGVAE on sufficient majority samples and then fine-tune based on minority samples with Elastic Weight Consolidation(EWC) regularization. Experimental results on benchmark image datasets and real-world tabular data show that MGVAE achieves competitive improvements over other over-sampling methods in downstream classification tasks, demonstrating the effectiveness of our method.
Structure-Preserving Graph Representation Learning
Sep 02, 2022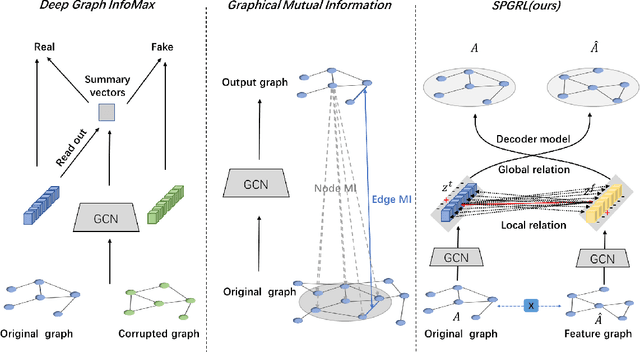

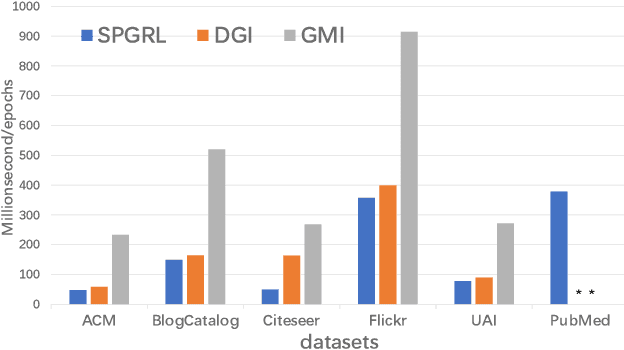
Though graph representation learning (GRL) has made significant progress, it is still a challenge to extract and embed the rich topological structure and feature information in an adequate way. Most existing methods focus on local structure and fail to fully incorporate the global topological structure. To this end, we propose a novel Structure-Preserving Graph Representation Learning (SPGRL) method, to fully capture the structure information of graphs. Specifically, to reduce the uncertainty and misinformation of the original graph, we construct a feature graph as a complementary view via k-Nearest Neighbor method. The feature graph can be used to contrast at node-level to capture the local relation. Besides, we retain the global topological structure information by maximizing the mutual information (MI) of the whole graph and feature embeddings, which is theoretically reduced to exchanging the feature embeddings of the feature and the original graphs to reconstruct themselves. Extensive experiments show that our method has quite superior performance on semi-supervised node classification task and excellent robustness under noise perturbation on graph structure or node features.
Self-Supervision Can Be a Good Few-Shot Learner
Jul 19, 2022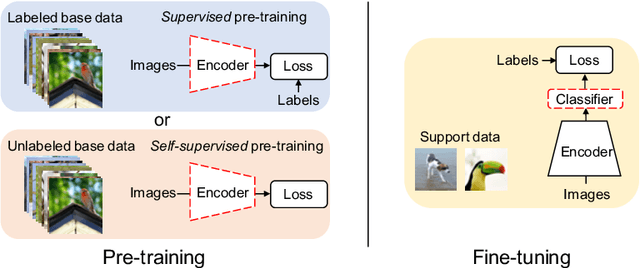
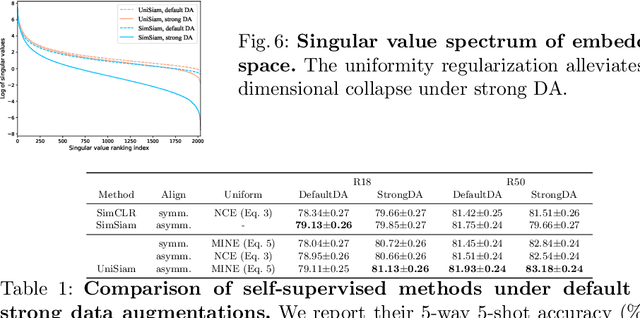
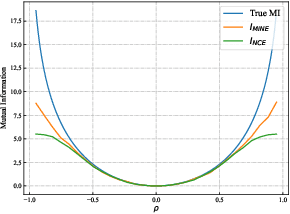
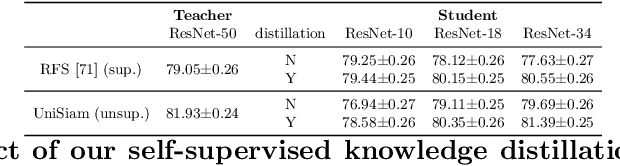
Existing few-shot learning (FSL) methods rely on training with a large labeled dataset, which prevents them from leveraging abundant unlabeled data. From an information-theoretic perspective, we propose an effective unsupervised FSL method, learning representations with self-supervision. Following the InfoMax principle, our method learns comprehensive representations by capturing the intrinsic structure of the data. Specifically, we maximize the mutual information (MI) of instances and their representations with a low-bias MI estimator to perform self-supervised pre-training. Rather than supervised pre-training focusing on the discriminable features of the seen classes, our self-supervised model has less bias toward the seen classes, resulting in better generalization for unseen classes. We explain that supervised pre-training and self-supervised pre-training are actually maximizing different MI objectives. Extensive experiments are further conducted to analyze their FSL performance with various training settings. Surprisingly, the results show that self-supervised pre-training can outperform supervised pre-training under the appropriate conditions. Compared with state-of-the-art FSL methods, our approach achieves comparable performance on widely used FSL benchmarks without any labels of the base classes.
Self-supervised Consensus Representation Learning for Attributed Graph
Aug 10, 2021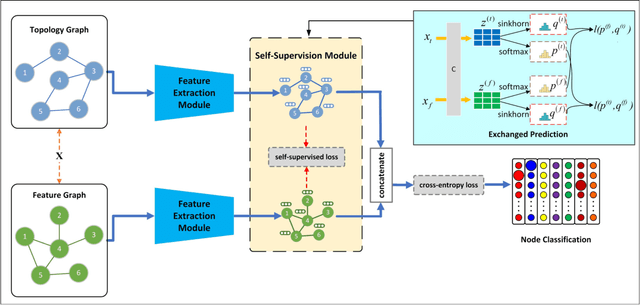
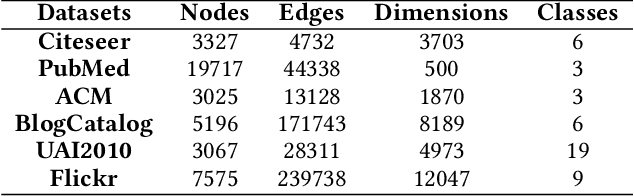

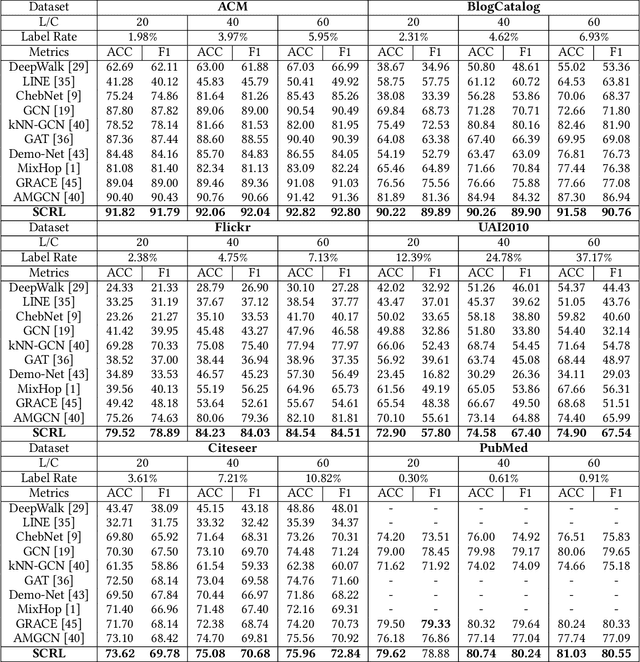
Attempting to fully exploit the rich information of topological structure and node features for attributed graph, we introduce self-supervised learning mechanism to graph representation learning and propose a novel Self-supervised Consensus Representation Learning (SCRL) framework. In contrast to most existing works that only explore one graph, our proposed SCRL method treats graph from two perspectives: topology graph and feature graph. We argue that their embeddings should share some common information, which could serve as a supervisory signal. Specifically, we construct the feature graph of node features via k-nearest neighbor algorithm. Then graph convolutional network (GCN) encoders extract features from two graphs respectively. Self-supervised loss is designed to maximize the agreement of the embeddings of the same node in the topology graph and the feature graph. Extensive experiments on real citation networks and social networks demonstrate the superiority of our proposed SCRL over the state-of-the-art methods on semi-supervised node classification task. Meanwhile, compared with its main competitors, SCRL is rather efficient.
Boosting Few-Shot Classification with View-Learnable Contrastive Learning
Jul 30, 2021



The goal of few-shot classification is to classify new categories with few labeled examples within each class. Nowadays, the excellent performance in handling few-shot classification problems is shown by metric-based meta-learning methods. However, it is very hard for previous methods to discriminate the fine-grained sub-categories in the embedding space without fine-grained labels. This may lead to unsatisfactory generalization to fine-grained subcategories, and thus affects model interpretation. To tackle this problem, we introduce the contrastive loss into few-shot classification for learning latent fine-grained structure in the embedding space. Furthermore, to overcome the drawbacks of random image transformation used in current contrastive learning in producing noisy and inaccurate image pairs (i.e., views), we develop a learning-to-learn algorithm to automatically generate different views of the same image. Extensive experiments on standard few-shot learning benchmarks demonstrate the superiority of our method.
ByPE-VAE: Bayesian Pseudocoresets Exemplar VAE
Jul 30, 2021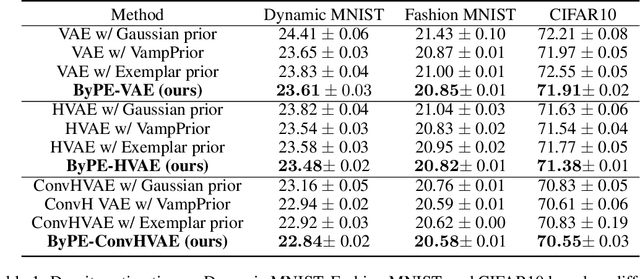
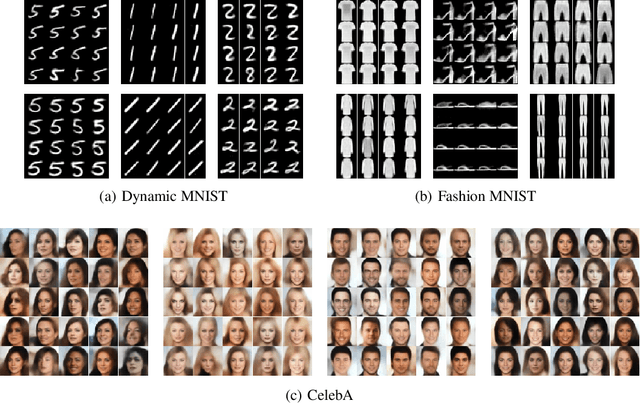


Recent studies show that advanced priors play a major role in deep generative models. Exemplar VAE, as a variant of VAE with an exemplar-based prior, has achieved impressive results. However, due to the nature of model design, an exemplar-based model usually requires vast amounts of data to participate in training, which leads to huge computational complexity. To address this issue, we propose Bayesian Pseudocoresets Exemplar VAE (ByPE-VAE), a new variant of VAE with a prior based on Bayesian pseudocoreset. The proposed prior is conditioned on a small-scale pseudocoreset rather than the whole dataset for reducing the computational cost and avoiding overfitting. Simultaneously, we obtain the optimal pseudocoreset via a stochastic optimization algorithm during VAE training aiming to minimize the Kullback-Leibler divergence between the prior based on the pseudocoreset and that based on the whole dataset. Experimental results show that ByPE-VAE can achieve competitive improvements over the state-of-the-art VAEs in the tasks of density estimation, representation learning, and generative data augmentation. Particularly, on a basic VAE architecture, ByPE-VAE is up to 3 times faster than Exemplar VAE while almost holding the performance. Code is available at our supplementary materials.