 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAP: Controllable Alignment Prompting for Unlearning in LLMs
Apr 23, 2026Large language models (LLMs) trained on unfiltered corpora inherently risk retaining sensitive information, necessitating selective knowledge unlearning for regulatory compliance and ethical safety. However, existing parameter-modifying methods face fundamental limitations: high computational costs, uncontrollable forgetting boundaries, and strict dependency on model weight access. These constraints render them impractical for closed-source models, yet current non-invasive alternatives remain unsystematic and reliant on empirical experience. To address these challenges, we propose the Controllable Alignment Prompting for Unlearning (CAP) framework, an end-to-end prompt-driven unlearning paradigm. CAP decouples unlearning into a learnable prompt optimization process via reinforcement learning, where a prompt generator collaborates with the LLM to suppress target knowledge while preserving general capabilities selectively. This approach enables reversible knowledge restoration through prompt revocation. Extensive experiments demonstrate that CAP achieves precise, controllable unlearning without updating model parameters, establishing a dynamic alignment mechanism that overcomes the transferability limitations of prior methods.
Neighbourhood Transformer: Switchable Attention for Monophily-Aware Graph Learning
Apr 10, 2026Graph neural networks (GNNs) have been widely adopted in engineering applications such as social network analysis, chemical research and computer vision. However, their efficacy is severely compromised by the inherent homophily assumption, which fails to hold for heterophilic graphs where dissimilar nodes are frequently connected. To address this fundamental limitation in graph learning, we first draw inspiration from the recently discovered monophily property of real-world graphs, and propose Neighbourhood Transformers (NT), a novel paradigm that applies self-attention within every local neighbourhood instead of aggregating messages to the central node as in conventional message-passing GNNs. This design makes NT inherently monophily-aware and theoretically guarantees its expressiveness is no weaker than traditional message-passing frameworks. For practical engineering deployment, we further develop a neighbourhood partitioning strategy equipped with switchable attentions, which reduces the space consumption of NT by over 95% and time consumption by up to 92.67%, significantly expanding its applicability to larger graphs. Extensive experiments on 10 real-world datasets (5 heterophilic and 5 homophilic graphs) show that NT outperforms all current state-of-the-art methods on node classification tasks, demonstrating its superior performance and cross-domain adaptability. The full implementation code of this work is publicly available at https://github.com/cf020031308/MoNT to facilitate reproducibility and industrial adoption.
GraphCogent: Overcoming LLMs' Working Memory Constraints via Multi-Agent Collaboration in Complex Graph Understanding
Aug 17, 2025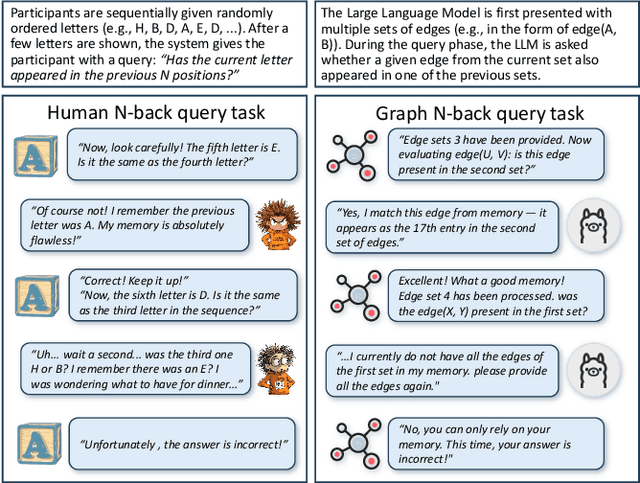
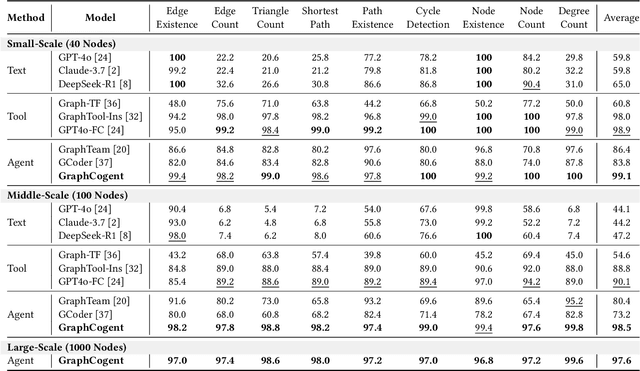
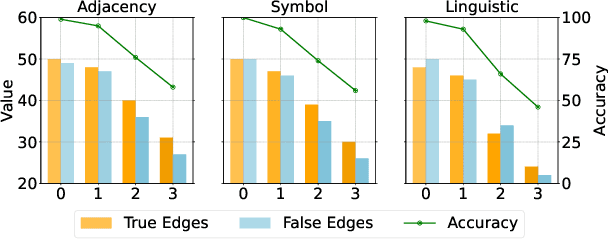

Large language models (LLMs) show promising performance on small-scale graph reasoning tasks but fail when handling real-world graphs with complex queries. This phenomenon stems from LLMs' inability to effectively process complex graph topology and perform multi-step reasoning simultaneously. To address these limitations, we propose GraphCogent, a collaborative agent framework inspired by human Working Memory Model that decomposes graph reasoning into specialized cognitive processes: sense, buffer, and execute. The framework consists of three modules: Sensory Module standardizes diverse graph text representations via subgraph sampling, Buffer Module integrates and indexes graph data across multiple formats, and Execution Module combines tool calling and model generation for efficient reasoning. We also introduce Graph4real, a comprehensive benchmark contains with four domains of real-world graphs (Web, Social, Transportation, and Citation) to evaluate LLMs' graph reasoning capabilities. Our Graph4real covers 21 different graph reasoning tasks, categorized into three types (Structural Querying, Algorithmic Reasoning, and Predictive Modeling tasks), with graph scales that are 10 times larger than existing benchmarks. Experiments show that Llama3.1-8B based GraphCogent achieves a 50% improvement over massive-scale LLMs like DeepSeek-R1 (671B). Compared to state-of-the-art agent-based baseline, our framework outperforms by 20% in accuracy while reducing token usage by 80% for in-toolset tasks and 30% for out-toolset tasks. Code will be available after review.
Graph Entropy Minimization for Semi-supervised Node Classification
May 31, 2023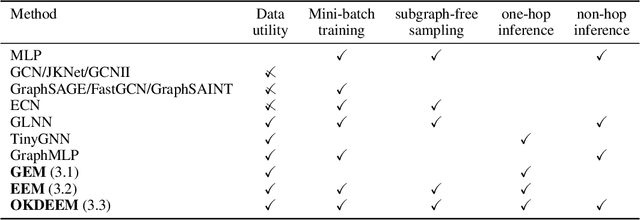
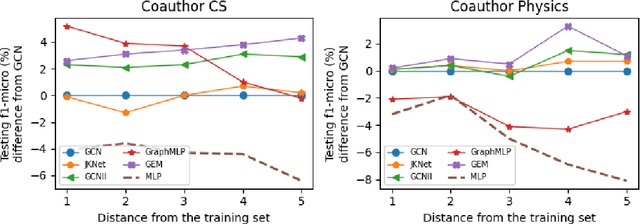
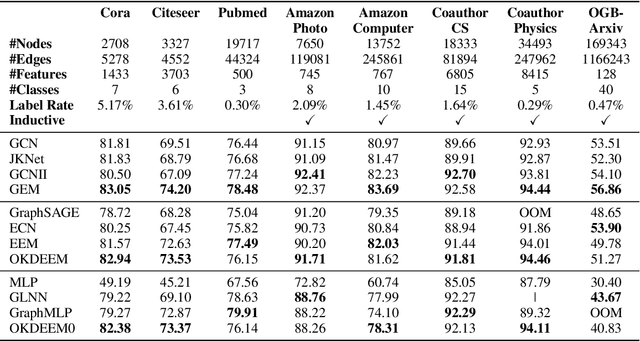
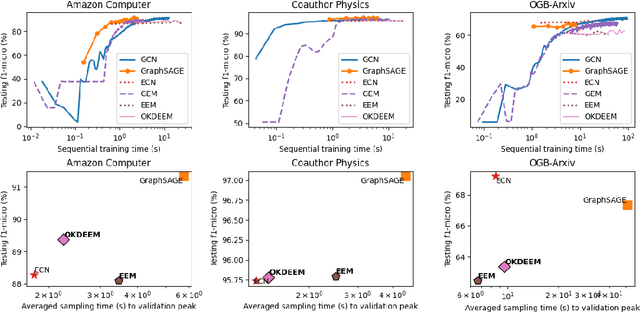
Node classifiers are required to comprehensively reduce prediction errors, training resources, and inference latency in the industry. However, most graph neural networks (GNN) concentrate only on one or two of them. The compromised aspects thus are the shortest boards on the bucket, hindering their practical deployments for industrial-level tasks. This work proposes a novel semi-supervised learning method termed Graph Entropy Minimization (GEM) to resolve the three issues simultaneously. GEM benefits its one-hop aggregation from massive uncategorized nodes, making its prediction accuracy comparable to GNNs with two or more hops message passing. It can be decomposed to support stochastic training with mini-batches of independent edge samples, achieving extremely fast sampling and space-saving training. While its one-hop aggregation is faster in inference than deep GNNs, GEM can be further accelerated to an extreme by deriving a non-hop classifier via online knowledge distillation. Thus, GEM can be a handy choice for latency-restricted and error-sensitive services running on resource-constraint hardware. Code is available at https://github.com/cf020031308/GEM.
Unifying Label-inputted Graph Neural Networks with Deep Equilibrium Models
Nov 19, 2022



For node classification, Graph Neural Networks (GNN) assign predefined labels to graph nodes according to node features propagated along the graph structure. Apart from the traditional end-to-end manner inherited from deep learning, many subsequent works input assigned labels into GNNs to improve their classification performance. Such label-inputted GNNs (LGNN) combine the advantages of learnable feature propagation and long-range label propagation, producing state-of-the-art performance on various benchmarks. However, the theoretical foundations of LGNNs are not well-established, and the combination is with seam because the long-range propagation is memory-consuming for optimization. To this end, this work interprets LGNNs with the theory of Implicit GNN (IGNN), which outputs a fixed state point of iterating its network infinite times and optimizes the infinite-range propagation with constant memory consumption. Besides, previous contributions to LGNNs inspire us to overcome the heavy computation in training IGNN by iterating the network only once but starting from historical states, which are randomly masked in forward-pass to implicitly guarantee the existence and uniqueness of the fixed point. Our improvements to IGNNs are network agnostic: for the first time, they are extended with complex networks and applied to large-scale graphs. Experiments on two synthetic and six real-world datasets verify the advantages of our method in terms of long-range dependencies capturing, label transitions modelling, accuracy, scalability, efficiency, and well-posedness.
Scalable Multi-view Clustering with Graph Filtering
May 18, 2022With the explosive growth of multi-source data, multi-view clustering has attracted great attention in recent years. Most existing multi-view methods operate in raw feature space and heavily depend on the quality of original feature representation. Moreover, they are often designed for feature data and ignore the rich topology structure information. Accordingly, in this paper, we propose a generic framework to cluster both attribute and graph data with heterogeneous features. It is capable of exploring the interplay between feature and structure. Specifically, we first adopt graph filtering technique to eliminate high-frequency noise to achieve a clustering-friendly smooth representation. To handle the scalability challenge, we develop a novel sampling strategy to improve the quality of anchors. Extensive experiments on attribute and graph benchmarks demonstrate the superiority of our approach with respect to state-of-the-art approaches.
Self-supervised Consensus Representation Learning for Attributed Graph
Aug 10, 2021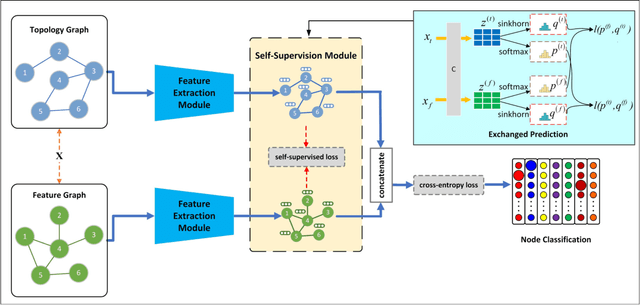

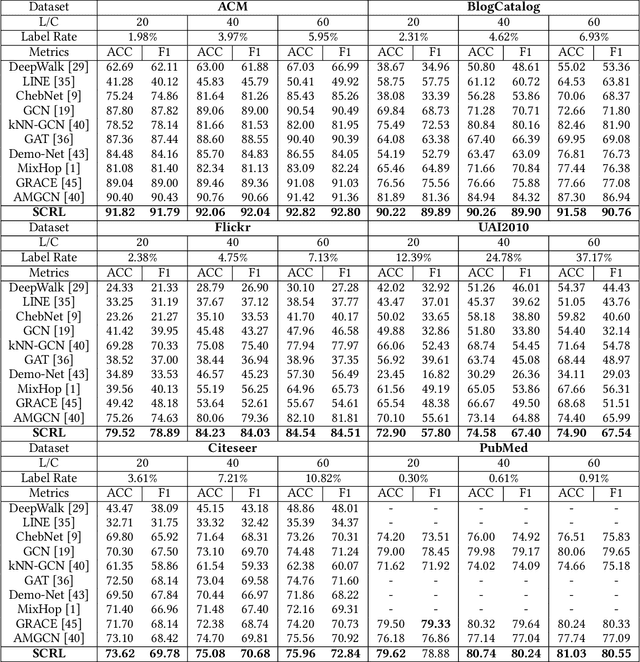
Attempting to fully exploit the rich information of topological structure and node features for attributed graph, we introduce self-supervised learning mechanism to graph representation learning and propose a novel Self-supervised Consensus Representation Learning (SCRL) framework. In contrast to most existing works that only explore one graph, our proposed SCRL method treats graph from two perspectives: topology graph and feature graph. We argue that their embeddings should share some common information, which could serve as a supervisory signal. Specifically, we construct the feature graph of node features via k-nearest neighbor algorithm. Then graph convolutional network (GCN) encoders extract features from two graphs respectively. Self-supervised loss is designed to maximize the agreement of the embeddings of the same node in the topology graph and the feature graph. Extensive experiments on real citation networks and social networks demonstrate the superiority of our proposed SCRL over the state-of-the-art methods on semi-supervised node classification task. Meanwhile, compared with its main competitors, SCRL is rather efficient.
Towards Clustering-friendly Representations: Subspace Clustering via Graph Filtering
Jun 18, 2021
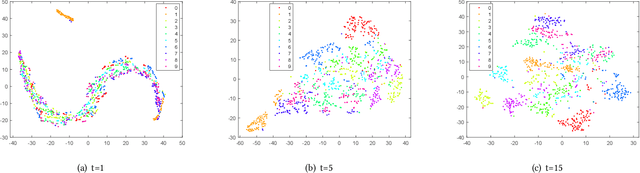
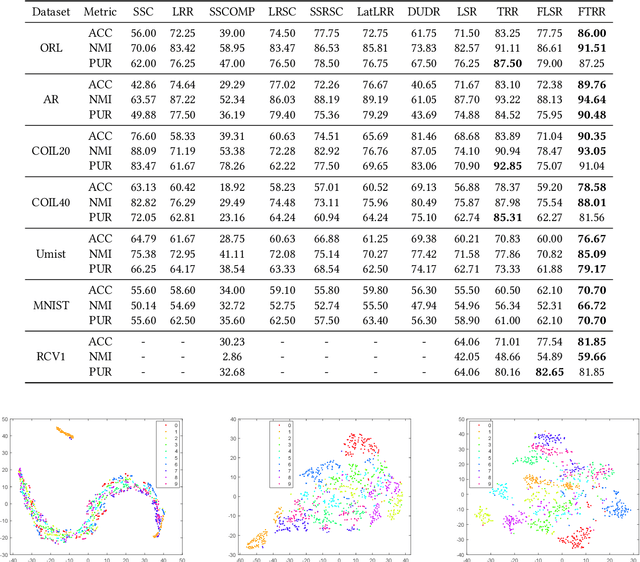

Finding a suitable data representation for a specific task has been shown to be crucial in many applications. The success of subspace clustering depends on the assumption that the data can be separated into different subspaces. However, this simple assumption does not always hold since the raw data might not be separable into subspaces. To recover the ``clustering-friendly'' representation and facilitate the subsequent clustering, we propose a graph filtering approach by which a smooth representation is achieved. Specifically, it injects graph similarity into data features by applying a low-pass filter to extract useful data representations for clustering. Extensive experiments on image and document clustering datasets demonstrate that our method improves upon state-of-the-art subspace clustering techniques. Especially, its comparable performance with deep learning methods emphasizes the effectiveness of the simple graph filtering scheme for many real-world applications. An ablation study shows that graph filtering can remove noise, preserve structure in the image, and increase the separability of classes.
Adversarial Privacy Preserving Graph Embedding against Inference Attack
Aug 30, 2020


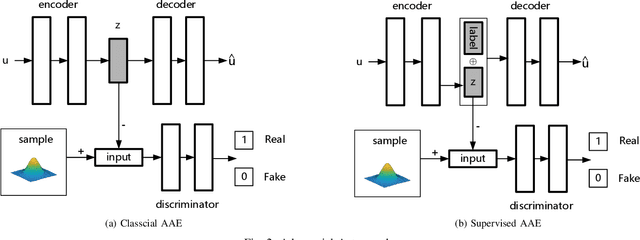
Recently, the surge in popularity of Internet of Things (IoT), mobile devices, social media, etc. has opened up a large source for graph data. Graph embedding has been proved extremely useful to learn low-dimensional feature representations from graph structured data. These feature representations can be used for a variety of prediction tasks from node classification to link prediction. However, existing graph embedding methods do not consider users' privacy to prevent inference attacks. That is, adversaries can infer users' sensitive information by analyzing node representations learned from graph embedding algorithms. In this paper, we propose Adversarial Privacy Graph Embedding (APGE), a graph adversarial training framework that integrates the disentangling and purging mechanisms to remove users' private information from learned node representations. The proposed method preserves the structural information and utility attributes of a graph while concealing users' private attributes from inference attacks. Extensive experiments on real-world graph datasets demonstrate the superior performance of APGE compared to the state-of-the-arts. Our source code can be found at https://github.com/uJ62JHD/Privacy-Preserving-Social-Network-Embedding.
Fine-Grained Image Captioning with Global-Local Discriminative Objective
Jul 21, 2020

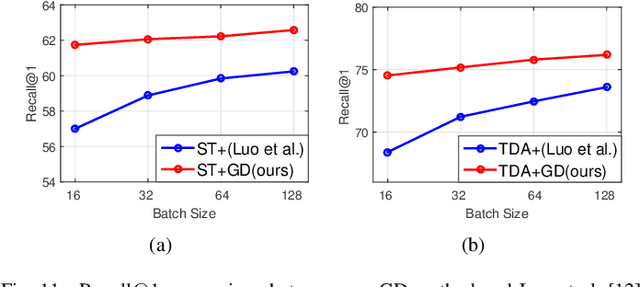
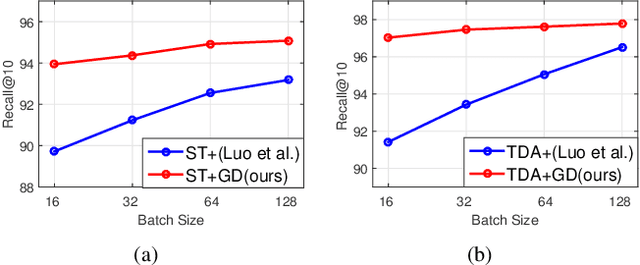
Significant progress has been made in recent years in image captioning, an active topic in the fields of vision and language. However, existing methods tend to yield overly general captions and consist of some of the most frequent words/phrases, resulting in inaccurate and indistinguishable descriptions (see Figure 1). This is primarily due to (i) the conservative characteristic of traditional training objectives that drives the model to generate correct but hardly discriminative captions for similar images and (ii) the uneven word distribution of the ground-truth captions, which encourages generating highly frequent words/phrases while suppressing the less frequent but more concrete ones. In this work, we propose a novel global-local discriminative objective that is formulated on top of a reference model to facilitate generating fine-grained descriptive captions. Specifically, from a global perspective, we design a novel global discriminative constraint that pulls the generated sentence to better discern the corresponding image from all others in the entire dataset. From the local perspective, a local discriminative constraint is proposed to increase attention such that it emphasizes the less frequent but more concrete words/phrases, thus facilitating the generation of captions that better describe the visual details of the given images. We evaluate the proposed method on the widely used MS-COCO dataset, where it outperforms the baseline methods by a sizable margin and achieves competitive performance over existing leading approaches. We also conduct self-retrieval experiments to demonstrate the discriminability of the proposed method.