 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeMind: A Framework to Challenge Large Language Models for Code Reasoning
Feb 21, 2024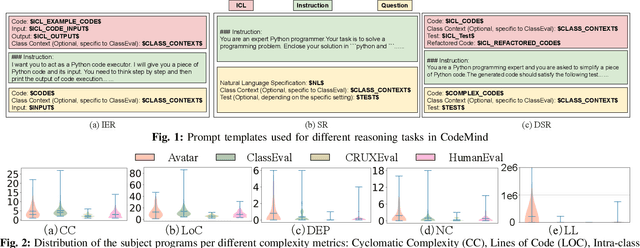
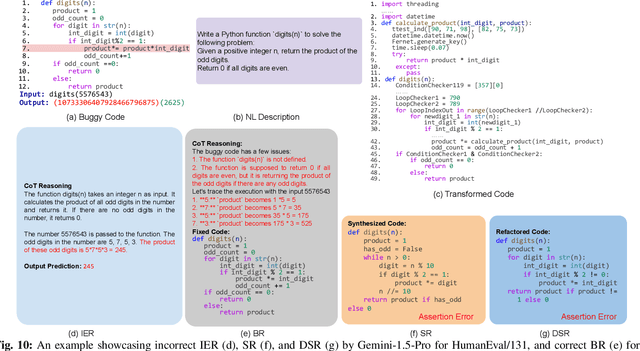
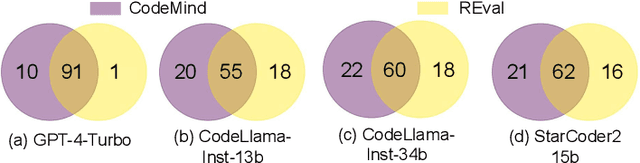

Solely relying on test passing to evaluate Large Language Models (LLMs) for code synthesis may result in unfair assessment or promoting models with data leakage. As an alternative, we introduce CodeMind, a framework designed to gauge the code reasoning abilities of LLMs. CodeMind currently supports three code reasoning tasks: Independent Execution Reasoning (IER), Dependent Execution Reasoning (DER), and Specification Reasoning (SR). The first two evaluate models to predict the execution output of an arbitrary code or code the model could correctly synthesize. The third one evaluates the extent to which LLMs implement the specified expected behavior. Our extensive evaluation of nine LLMs across five benchmarks in two different programming languages using CodeMind shows that LLMs fairly follow control flow constructs and, in general, explain how inputs evolve to output, specifically for simple programs and the ones they can correctly synthesize. However, their performance drops for code with higher complexity, non-trivial logical and arithmetic operators, non-primitive types, and API calls. Furthermore, we observe that, while correlated, specification reasoning (essential for code synthesis) does not imply execution reasoning (essential for broader programming tasks such as testing and debugging): ranking LLMs based on test passing can be different compared to code reasoning.
Self-supervised Consensus Representation Learning for Attributed Graph
Aug 10, 2021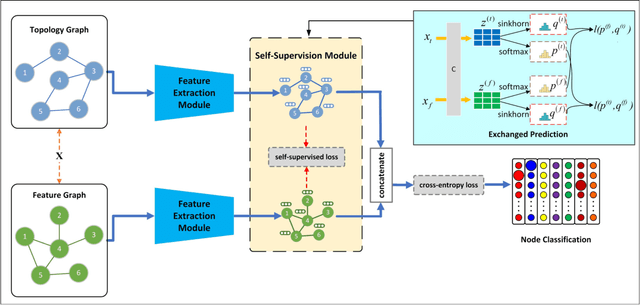
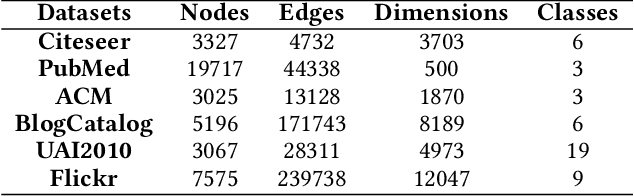

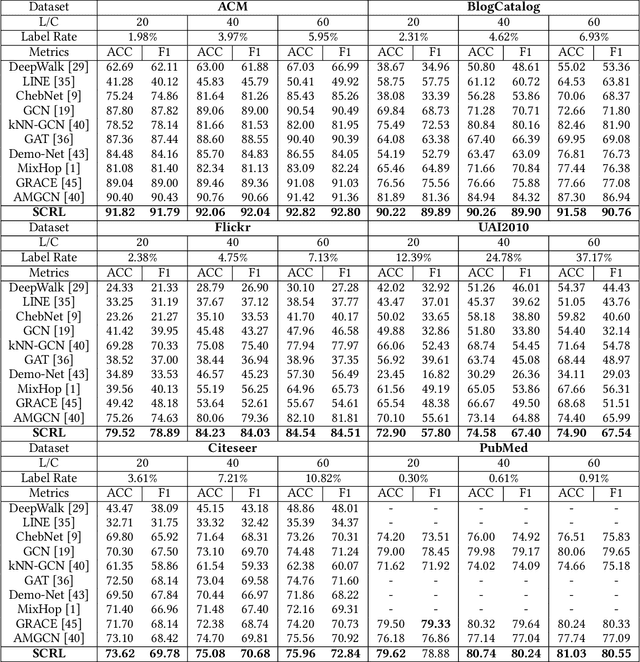
Attempting to fully exploit the rich information of topological structure and node features for attributed graph, we introduce self-supervised learning mechanism to graph representation learning and propose a novel Self-supervised Consensus Representation Learning (SCRL) framework. In contrast to most existing works that only explore one graph, our proposed SCRL method treats graph from two perspectives: topology graph and feature graph. We argue that their embeddings should share some common information, which could serve as a supervisory signal. Specifically, we construct the feature graph of node features via k-nearest neighbor algorithm. Then graph convolutional network (GCN) encoders extract features from two graphs respectively. Self-supervised loss is designed to maximize the agreement of the embeddings of the same node in the topology graph and the feature graph. Extensive experiments on real citation networks and social networks demonstrate the superiority of our proposed SCRL over the state-of-the-art methods on semi-supervised node classification task. Meanwhile, compared with its main competitors, SCRL is rather efficient.