 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Plan to Action: How Well Do Agents Follow the Plan?
Apr 13, 2026Agents aspire to eliminate the need for task-specific prompt crafting through autonomous reason-act-observe loops. Still, they are commonly instructed to follow a task-specific plan for guidance, e.g., to resolve software issues following phases for navigation, reproduction, patch, and validation. Unfortunately, it is unknown to what extent agents actually follow such instructed plans. Without such an analysis, determining the extent agents comply with a given plan, it is impossible to assess whether a solution was reached through correct strategic reasoning or through other means, e.g., data contamination or overfitting to a benchmark. This paper presents the first extensive, systematic analysis of plan compliance in programming agents, examining 16,991 trajectories from SWE-agent across four LLMs on SWE-bench Verified and SWE-bench Pro under eight plan variations. Without an explicit plan, agents fall back on workflows internalized during training, which are often incomplete, overfit, or inconsistently applied. Providing the standard plan improves issue resolution, and we observe that periodic plan reminders can mitigate plan violations and improve task success. A subpar plan hurts performance even more than no plan at all. Surprisingly, augmenting a plan with additional task-relevant phases in the early stage can degrade performance, particularly when these phases do not align with the model's internal problem-solving strategy. These findings highlight a research gap: fine-tuning paradigms that teach models to follow instructed plans, rather than encoding task-specific plans in them. This requires teaching models to reason and act adaptively, rather than memorizing workflows.
ReCodeAgent: A Multi-Agent Workflow for Language-agnostic Translation and Validation of Large-scale Repositories
Apr 08, 2026Most repository-level code translation and validation techniques have been evaluated on a single source-target programming language (PL) pair, owing to the complex engineering effort required to adapt new PL pairs. Programming agents can enable PL-agnosticism in repository-level code translation and validation: they can synthesize code across many PLs and autonomously use existing tools specific to each PL's analysis. However, state-of-the-art has yet to offer a fully autonomous agentic approach for repository-level code translation and validation of large-scale programs. This paper proposes ReCodeAgent, an autonomous multi-agent approach for language-agnostic repository-level code translation and validation. Users only need to provide the project in the source PL and specify the target PL for ReCodeAgent to automatically translate and validate the entire repository. ReCodeAgent is the first technique to achieve high translation success rates across many PLs. We compare the effectiveness of ReCodeAgent with four alternative neuro-symbolic and agentic approaches to translate 118 real-world projects, with 1,975 LoC and 43 translation units for each project, on average. The projects cover 6 PLs (C, Go, Java, JavaScript, Python, and Rust) and 4 PL pairs (C-Rust, Go-Rust, Java-Python, Python-JavaScript). Our results demonstrate that ReCodeAgent consistently outperforms prior techniques on translation correctness, improving test pass rate by 60.8% on ground-truth tests, with an average cost of $15.3. We also perform process-centric analysis of ReCodeAgent trajectories to confirm its procedural efficiency. Finally, we investigate how the design choices (a multi-agent vs. single-agent architecture) influence ReCodeAgent performance: on average, the test pass rate drops by 40.4%, and trajectories become 28% longer and persistently inefficient.
SPARC: Scenario Planning and Reasoning for Automated C Unit Test Generation
Feb 18, 2026Automated unit test generation for C remains a formidable challenge due to the semantic gap between high-level program intent and the rigid syntactic constraints of pointer arithmetic and manual memory management. While Large Language Models (LLMs) exhibit strong generative capabilities, direct intent-to-code synthesis frequently suffers from the leap-to-code failure mode, where models prematurely emit code without grounding in program structure, constraints, and semantics. This will result in non-compilable tests, hallucinated function signatures, low branch coverage, and semantically irrelevant assertions that cannot properly capture bugs. We introduce SPARC, a neuro-symbolic, scenario-based framework that bridges this gap through four stages: (1) Control Flow Graph (CFG) analysis, (2) an Operation Map that grounds LLM reasoning in validated utility helpers, (3) Path-targeted test synthesis, and (4) an iterative, self-correction validation loop using compiler and runtime feedback. We evaluate SPARC on 59 real-world and algorithmic subjects, where it outperforms the vanilla prompt generation baseline by 31.36% in line coverage, 26.01% in branch coverage, and 20.78% in mutation score, matching or exceeding the symbolic execution tool KLEE on complex subjects. SPARC retains 94.3% of tests through iterative repair and produces code with significantly higher developer-rated readability and maintainability. By aligning LLM reasoning with program structure, SPARC provides a scalable path for industrial-grade testing of legacy C codebases.
MatchFixAgent: Language-Agnostic Autonomous Repository-Level Code Translation Validation and Repair
Sep 19, 2025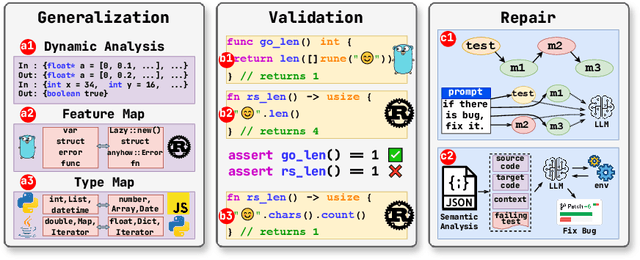



Code translation transforms source code from one programming language (PL) to another. Validating the functional equivalence of translation and repairing, if necessary, are critical steps in code translation. Existing automated validation and repair approaches struggle to generalize to many PLs due to high engineering overhead, and they rely on existing and often inadequate test suites, which results in false claims of equivalence and ineffective translation repair. We develop MatchFixAgent, a large language model (LLM)-based, PL-agnostic framework for equivalence validation and repair of translations. MatchFixAgent features a multi-agent architecture that divides equivalence validation into several sub-tasks to ensure thorough and consistent semantic analysis of the translation. Then it feeds this analysis to test agent to write and execute tests. Upon observing a test failure, the repair agent attempts to fix the translation bug. The final (in)equivalence decision is made by the verdict agent, considering semantic analyses and test execution results. We compare MatchFixAgent's validation and repair results with four repository-level code translation techniques. We use 2,219 translation pairs from their artifacts, which cover 6 PL pairs, and are collected from 24 GitHub projects totaling over 900K lines of code. Our results demonstrate that MatchFixAgent produces (in)equivalence verdicts for 99.2% of translation pairs, with the same equivalence validation result as prior work on 72.8% of them. When MatchFixAgent's result disagrees with prior work, we find that 60.7% of the time MatchFixAgent's result is actually correct. In addition, we show that MatchFixAgent can repair 50.6% of inequivalent translation, compared to prior work's 18.5%. This demonstrates that MatchFixAgent is far more adaptable to many PL pairs than prior work, while producing highly accurate validation results.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
Repository-Level Compositional Code Translation and Validation
Oct 31, 2024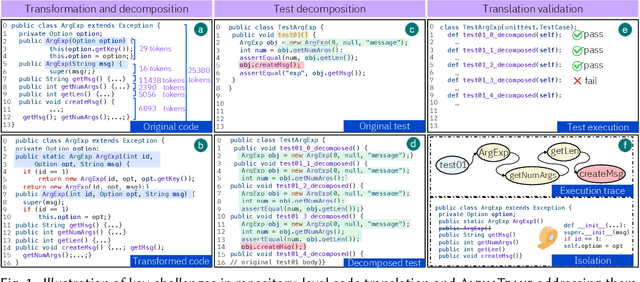
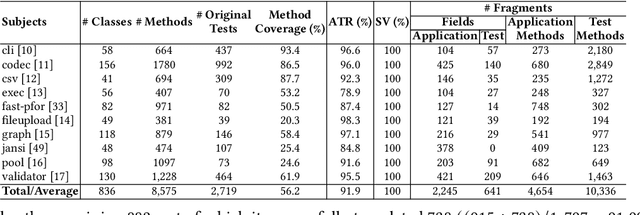
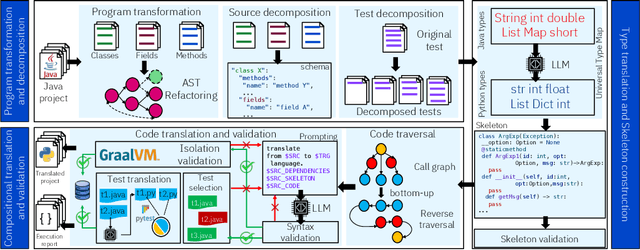
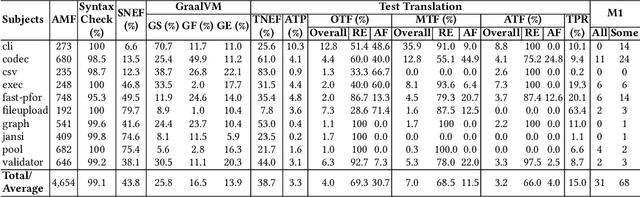
Code translation transforms programs from one programming language (PL) to another. Several rule-based transpilers have been designed to automate code translation between different pairs of PLs. However, the rules can become obsolete as the PLs evolve and cannot generalize to other PLs. Recent studies have explored the automation of code translation using Large Language Models (LLMs). One key observation is that such techniques may work well for crafted benchmarks but fail to generalize to the scale and complexity of real-world projects with dependencies, custom types, PL-specific features, etc. We propose AlphaTrans, a neuro-symbolic approach to automate repository-level code translation. AlphaTrans translates both source and test code, and employs multiple levels of validation to ensure the translation preserves the functionality of the source program. To break down the problem for LLMs, AlphaTrans leverages program analysis to decompose the program into fragments and translates them in the reverse call order. We leveraged AlphaTrans to translate ten real-world open-source projects consisting of <836, 8575, 2719> classes, methods, and tests. AlphaTrans translated the entire repository of these projects consisting of 6899 source code fragments. 99.1% of the translated code fragments are syntactically correct, and AlphaTrans validates the translations' runtime behavior and functional correctness for 25.8%. On average, the integrated translation and validation take 36 hours to translate a project, showing its scalability in practice. For the syntactically or semantically incorrect translations, AlphaTrans generates a report including existing translation, stack trace, test errors, or assertion failures. We provided these artifacts to two developers to fix the translation bugs in four projects. They were able to fix the issues in 20.1 hours on average and achieve all passing tests.
CodeMind: A Framework to Challenge Large Language Models for Code Reasoning
Feb 21, 2024
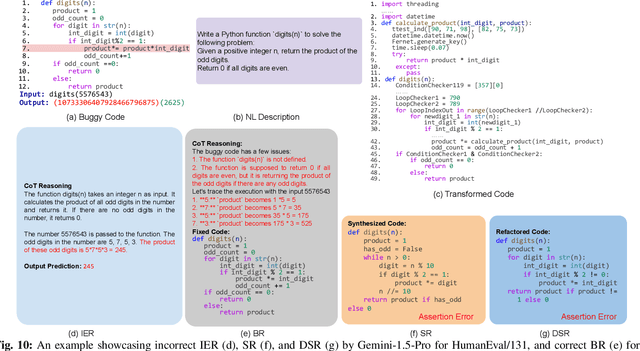
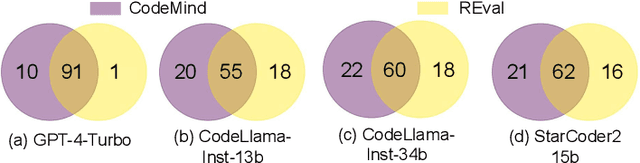

Solely relying on test passing to evaluate Large Language Models (LLMs) for code synthesis may result in unfair assessment or promoting models with data leakage. As an alternative, we introduce CodeMind, a framework designed to gauge the code reasoning abilities of LLMs. CodeMind currently supports three code reasoning tasks: Independent Execution Reasoning (IER), Dependent Execution Reasoning (DER), and Specification Reasoning (SR). The first two evaluate models to predict the execution output of an arbitrary code or code the model could correctly synthesize. The third one evaluates the extent to which LLMs implement the specified expected behavior. Our extensive evaluation of nine LLMs across five benchmarks in two different programming languages using CodeMind shows that LLMs fairly follow control flow constructs and, in general, explain how inputs evolve to output, specifically for simple programs and the ones they can correctly synthesize. However, their performance drops for code with higher complexity, non-trivial logical and arithmetic operators, non-primitive types, and API calls. Furthermore, we observe that, while correlated, specification reasoning (essential for code synthesis) does not imply execution reasoning (essential for broader programming tasks such as testing and debugging): ranking LLMs based on test passing can be different compared to code reasoning.
White-box Compiler Fuzzing Empowered by Large Language Models
Oct 24, 2023



Compiler correctness is crucial, as miscompilation falsifying the program behaviors can lead to serious consequences. In the literature, fuzzing has been extensively studied to uncover compiler defects. However, compiler fuzzing remains challenging: Existing arts focus on black- and grey-box fuzzing, which generates tests without sufficient understanding of internal compiler behaviors. As such, they often fail to construct programs to exercise conditions of intricate optimizations. Meanwhile, traditional white-box techniques are computationally inapplicable to the giant codebase of compilers. Recent advances demonstrate that Large Language Models (LLMs) excel in code generation/understanding tasks and have achieved state-of-the-art performance in black-box fuzzing. Nonetheless, prompting LLMs with compiler source-code information remains a missing piece of research in compiler testing. To this end, we propose WhiteFox, the first white-box compiler fuzzer using LLMs with source-code information to test compiler optimization. WhiteFox adopts a dual-model framework: (i) an analysis LLM examines the low-level optimization source code and produces requirements on the high-level test programs that can trigger the optimization; (ii) a generation LLM produces test programs based on the summarized requirements. Additionally, optimization-triggering tests are used as feedback to further enhance the test generation on the fly. Our evaluation on four popular compilers shows that WhiteFox can generate high-quality tests to exercise deep optimizations requiring intricate conditions, practicing up to 80 more optimizations than state-of-the-art fuzzers. To date, WhiteFox has found in total 96 bugs, with 80 confirmed as previously unknown and 51 already fixed. Beyond compiler testing, WhiteFox can also be adapted for white-box fuzzing of other complex, real-world software systems in general.
Automated Bug Generation in the era of Large Language Models
Oct 03, 2023



Bugs are essential in software engineering; many research studies in the past decades have been proposed to detect, localize, and repair bugs in software systems. Effectiveness evaluation of such techniques requires complex bugs, i.e., those that are hard to detect through testing and hard to repair through debugging. From the classic software engineering point of view, a hard-to-repair bug differs from the correct code in multiple locations, making it hard to localize and repair. Hard-to-detect bugs, on the other hand, manifest themselves under specific test inputs and reachability conditions. These two objectives, i.e., generating hard-to-detect and hard-to-repair bugs, are mostly aligned; a bug generation technique can change multiple statements to be covered only under a specific set of inputs. However, these two objectives are conflicting for learning-based techniques: A bug should have a similar code representation to the correct code in the training data to challenge a bug prediction model to distinguish them. The hard-to-repair bug definition remains the same but with a caveat: the more a bug differs from the original code (at multiple locations), the more distant their representations are and easier to be detected. We propose BugFarm, to transform arbitrary code into multiple complex bugs. BugFarm leverages LLMs to mutate code in multiple locations (hard-to-repair). To ensure that multiple modifications do not notably change the code representation, BugFarm analyzes the attention of the underlying model and instructs LLMs to only change the least attended locations (hard-to-detect). Our comprehensive evaluation of 320k+ bugs from over 2.5M mutants generated by BugFarm and two alternative approaches demonstrates our superiority in generating bugs that are hard to detect by learning-based bug prediction approaches and hard to repair by SOTA learning-based program repair technique.
LeTI: Learning to Generate from Textual Interactions
May 17, 2023



Finetuning pre-trained language models (LMs) enhances the models' capabilities. Prior techniques fine-tune a pre-trained LM on input-output pairs (e.g., instruction fine-tuning), or with numerical rewards that gauge the quality of its outputs (e.g., reinforcement learning from human feedback). We explore LMs' potential to learn from textual interactions (LeTI) that not only check their correctness with binary labels, but also pinpoint and explain errors in their outputs through textual feedback. Our investigation focuses on the code generation task, where the model produces code pieces in response to natural language instructions. This setting invites a natural and scalable way to acquire the textual feedback: the error messages and stack traces from code execution using a Python interpreter. LeTI iteratively fine-tunes the model, using the LM objective, on a concatenation of natural language instructions, LM-generated programs, and textual feedback, which is only provided when the generated program fails to solve the task. Prepended to this fine-tuning text, a binary reward token is used to differentiate correct and buggy solutions. On MBPP, a code generation dataset, LeTI substantially improves the performance of two base LMs of different scales. LeTI requires no ground-truth outputs for training and even outperforms a fine-tuned baseline that does. LeTI's strong performance generalizes to other datasets. Trained on MBPP, it achieves comparable or better performance than the base LMs on unseen problems in HumanEval. Furthermore, compared to binary feedback, we observe that textual feedback leads to improved generation quality and sample efficiency, achieving the same performance with fewer than half of the gradient steps. LeTI is equally applicable in natural language tasks when they can be formulated as code generation, which we empirically verified on event argument extraction.