 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode as Agent Harness
May 18, 2026Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. We frame this shift through the lens of agent harnesses and introduce code as agent harness: a unified view that centers code as the basis for agent infrastructure. To systematically study this perspective, we organize the survey around three connected layers. First, we study the harness interface, where code connects agents to reasoning, action, and environment modeling. Second, we examine harness mechanisms: planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive. Third, we discuss scaling the harness from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification. Across these layers, we summarize representative methods and practical applications of code as agent harness, spanning coding assistants, GUI/OS automation, embodied agents, scientific discovery, personalization and recommendation, DevOps, and enterprise workflows. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight for safety-critical actions, and extensions to multimodal environments. By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
AnyPoC: Universal Proof-of-Concept Test Generation for Scalable LLM-Based Bug Detection
Apr 13, 2026While recent LLM-based agents can identify many candidate bugs in source code, their reports remain static hypotheses that require manual validation, limiting the practicality of automated bug detection. We frame this challenge as a test generation task: given a candidate report, synthesizing an executable proof-of-concept test, or simply a PoC - such as a script, command sequence, or crafted input - to trigger the suspected defect. Automated PoC generation can act as a scalable validation oracle, enabling end-to-end autonomous bug detection by providing concrete execution evidence. However, naive LLM agents are unreliable validators: they are biased toward "success" and may reward-hack by producing plausible but non-functional PoCs or even hallucinated traces. To address this, we present AnyPoC, a general multi-agent framework that (1) analyzes and fact-checks a candidate bug report, (2) iteratively synthesizes and executes a PoC while collecting execution traces, and (3) independently re-executes and scrutinizes the PoC to mitigate hallucination and reward hacking. In addition, AnyPoC also continuously extracts and evolves a PoC knowledge base to handle heterogeneous tasks. AnyPoC operates on candidate bug reports regardless of their source and can be paired with different bug reporters. To demonstrate practicality and generality, we apply AnyPoC, with a simple agentic bug reporter, on 12 critical software systems across diverse languages/domains (many with millions of lines of code) including Firefox, Chromium, LLVM, OpenSSL, SQLite, FFmpeg, and Redis. Compared to the state-of-the-art coding agents, e.g., Claude Code and Codex, AnyPoC produces 1.3x more valid PoCs for true-positive bug reports and rejects 9.8x more false-positive bug reports. To date, AnyPoC has discovered 122 new bugs (105 confirmed, 86 already fixed), with 45 generated PoCs adopted as official regression tests.
VeruSAGE: A Study of Agent-Based Verification for Rust Systems
Dec 20, 2025Large language models (LLMs) have shown impressive capability to understand and develop code. However, their capability to rigorously reason about and prove code correctness remains in question. This paper offers a comprehensive study of LLMs' capability to develop correctness proofs for system software written in Rust. We curate a new system-verification benchmark suite, VeruSAGE-Bench, which consists of 849 proof tasks extracted from eight open-source Verus-verified Rust systems. Furthermore, we design different agent systems to match the strengths and weaknesses of different LLMs (o4-mini, GPT-5, Sonnet 4, and Sonnet 4.5). Our study shows that different tools and agent settings are needed to stimulate the system-verification capability of different types of LLMs. The best LLM-agent combination in our study completes over 80% of system-verification tasks in VeruSAGE-Bench. It also completes over 90% of a set of system proof tasks not part of VeruSAGE-Bench because they had not yet been finished by human experts. This result shows the great potential for LLM-assisted development of verified system software.
Multilingual Routing in Mixture-of-Experts
Oct 06, 2025Mixture-of-Experts (MoE) architectures have become the key to scaling modern LLMs, yet little is understood about how their sparse routing dynamics respond to multilingual data. In this work, we analyze expert routing patterns using parallel multilingual datasets and present highly interpretable layer-wise phenomena. We find that MoE models route tokens in language-specific ways in the early and late decoder layers but exhibit significant cross-lingual routing alignment in middle layers, mirroring parameter-sharing trends observed in dense LLMs. In particular, we reveal a clear, strong correlation between a model's performance in a given language and how similarly its tokens are routed to English in these layers. Extending beyond correlation, we explore inference-time interventions that induce higher cross-lingual routing alignment. We introduce a method that steers the router by promoting middle-layer task experts frequently activated in English, and it successfully increases multilingual performance. These 1-2% gains are remarkably consistent across two evaluation tasks, three models, and 15+ languages, especially given that these simple interventions override routers of extensively trained, state-of-the-art LLMs. In comparison, interventions outside of the middle layers or targeting multilingual-specialized experts only yield performance degradation. Altogether, we present numerous findings that explain how MoEs process non-English text and demonstrate that generalization is limited by the model's ability to leverage language-universal experts in all languages.
A Multi-Dimensional Constraint Framework for Evaluating and Improving Instruction Following in Large Language Models
May 12, 2025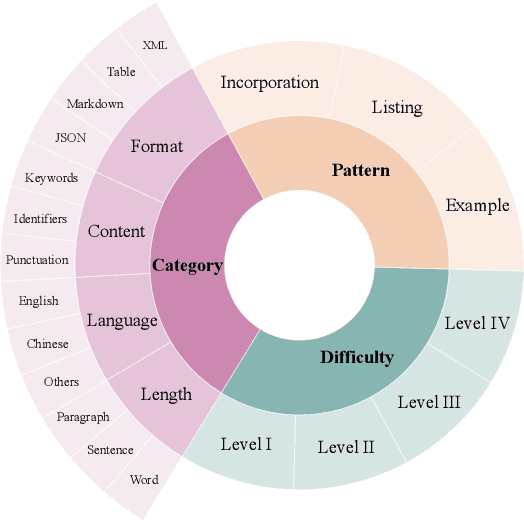

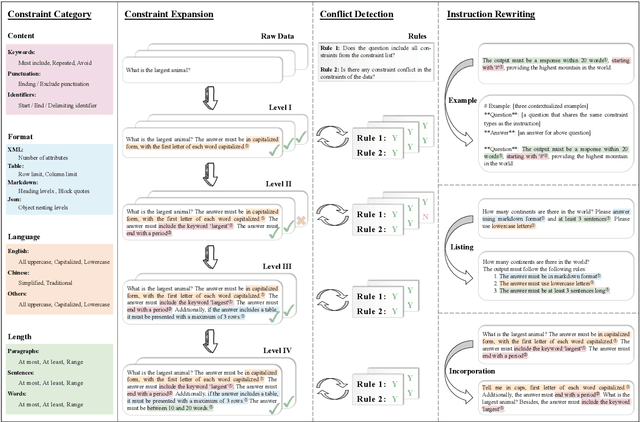
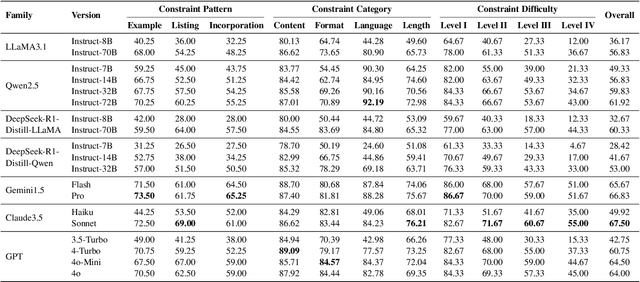
Instruction following evaluates large language models (LLMs) on their ability to generate outputs that adhere to user-defined constraints. However, existing benchmarks often rely on templated constraint prompts, which lack the diversity of real-world usage and limit fine-grained performance assessment. To fill this gap, we propose a multi-dimensional constraint framework encompassing three constraint patterns, four constraint categories, and four difficulty levels. Building on this framework, we develop an automated instruction generation pipeline that performs constraint expansion, conflict detection, and instruction rewriting, yielding 1,200 code-verifiable instruction-following test samples. We evaluate 19 LLMs across seven model families and uncover substantial variation in performance across constraint forms. For instance, average performance drops from 77.67% at Level I to 32.96% at Level IV. Furthermore, we demonstrate the utility of our approach by using it to generate data for reinforcement learning, achieving substantial gains in instruction following without degrading general performance. In-depth analysis indicates that these gains stem primarily from modifications in the model's attention modules parameters, which enhance constraint recognition and adherence. Code and data are available in https://github.com/Junjie-Ye/MulDimIF.
KNighter: Transforming Static Analysis with LLM-Synthesized Checkers
Mar 12, 2025



Static analysis is a powerful technique for bug detection in critical systems like operating system kernels. However, designing and implementing static analyzers is challenging, time-consuming, and typically limited to predefined bug patterns. While large language models (LLMs) have shown promise for static analysis, directly applying them to scan large codebases remains impractical due to computational constraints and contextual limitations. We present KNighter, the first approach that unlocks practical LLM-based static analysis by automatically synthesizing static analyzers from historical bug patterns. Rather than using LLMs to directly analyze massive codebases, our key insight is leveraging LLMs to generate specialized static analyzers guided by historical patch knowledge. KNighter implements this vision through a multi-stage synthesis pipeline that validates checker correctness against original patches and employs an automated refinement process to iteratively reduce false positives. Our evaluation on the Linux kernel demonstrates that KNighter generates high-precision checkers capable of detecting diverse bug patterns overlooked by existing human-written analyzers. To date, KNighter-synthesized checkers have discovered 70 new bugs/vulnerabilities in the Linux kernel, with 56 confirmed and 41 already fixed. 11 of these findings have been assigned CVE numbers. This work establishes an entirely new paradigm for scalable, reliable, and traceable LLM-based static analysis for real-world systems via checker synthesis.
Automated Proof Generation for Rust Code via Self-Evolution
Oct 21, 2024



Ensuring correctness is crucial for code generation. Formal verification offers a definitive assurance of correctness, but demands substantial human effort in proof construction and hence raises a pressing need for automation. The primary obstacle lies in the severe lack of data - there is much less proof than code for LLMs to train upon. In this paper, we introduce SAFE, a novel framework that overcomes the lack of human-written proof to enable automated proof generation of Rust code. SAFE establishes a self-evolving cycle where data synthesis and fine-tuning collaborate to enhance the model capability, leveraging the definitive power of a symbolic verifier in telling correct proof from incorrect ones. SAFE also re-purposes the large number of synthesized incorrect proofs to train the self-debugging capability of the fine-tuned models, empowering them to fix incorrect proofs based on the verifier's feedback. SAFE demonstrates superior efficiency and precision compared to GPT-4o. Through tens of thousands of synthesized proofs and the self-debugging mechanism, we improve the capability of open-source models, initially unacquainted with formal verification, to automatically write proof for Rust code. This advancement leads to a significant improvement in performance, achieving a 70.50% accuracy rate in a benchmark crafted by human experts, a significant leap over GPT-4o's performance of 24.46%.
KernelGPT: Enhanced Kernel Fuzzing via Large Language Models
Dec 31, 2023Bugs in operating system kernels can affect billions of devices and users all over the world. As a result, a large body of research has been focused on kernel fuzzing, i.e., automatically generating syscall (system call) sequences to detect potential kernel bugs or vulnerabilities. Syzkaller, one of the most widely studied kernel fuzzers, aims to generate valid syscall sequences based on predefined specifications written in syzlang, a domain-specific language for defining syscalls, their arguments, and the relationships between them. While there has been existing work trying to automate Syzkaller specification generation, this still remains largely manual work and a large number of important syscalls are still uncovered. In this paper, we propose KernelGPT, the first approach to automatically inferring Syzkaller specifications via Large Language Models (LLMs) for enhanced kernel fuzzing. Our basic insight is that LLMs have seen massive kernel code, documentation, and use cases during pre-training, and thus can automatically distill the necessary information for making valid syscalls. More specifically, KernelGPT leverages an iterative approach to automatically infer all the necessary specification components, and further leverages the validation feedback to repair/refine the initial specifications. Our preliminary results demonstrate that KernelGPT can help Syzkaller achieve higher coverage and find multiple previously unknown bugs. Moreover, we also received a request from the Syzkaller team to upstream specifications inferred by KernelGPT.
White-box Compiler Fuzzing Empowered by Large Language Models
Oct 24, 2023



Compiler correctness is crucial, as miscompilation falsifying the program behaviors can lead to serious consequences. In the literature, fuzzing has been extensively studied to uncover compiler defects. However, compiler fuzzing remains challenging: Existing arts focus on black- and grey-box fuzzing, which generates tests without sufficient understanding of internal compiler behaviors. As such, they often fail to construct programs to exercise conditions of intricate optimizations. Meanwhile, traditional white-box techniques are computationally inapplicable to the giant codebase of compilers. Recent advances demonstrate that Large Language Models (LLMs) excel in code generation/understanding tasks and have achieved state-of-the-art performance in black-box fuzzing. Nonetheless, prompting LLMs with compiler source-code information remains a missing piece of research in compiler testing. To this end, we propose WhiteFox, the first white-box compiler fuzzer using LLMs with source-code information to test compiler optimization. WhiteFox adopts a dual-model framework: (i) an analysis LLM examines the low-level optimization source code and produces requirements on the high-level test programs that can trigger the optimization; (ii) a generation LLM produces test programs based on the summarized requirements. Additionally, optimization-triggering tests are used as feedback to further enhance the test generation on the fly. Our evaluation on four popular compilers shows that WhiteFox can generate high-quality tests to exercise deep optimizations requiring intricate conditions, practicing up to 80 more optimizations than state-of-the-art fuzzers. To date, WhiteFox has found in total 96 bugs, with 80 confirmed as previously unknown and 51 already fixed. Beyond compiler testing, WhiteFox can also be adapted for white-box fuzzing of other complex, real-world software systems in general.