 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMEval-3: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Aug 07, 2025Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-3, a framework for dynamic evaluation of LLMs. LLMEval-3 is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. An 20-month longitudinal study of nearly 50 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-3 offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.
Feature-free regression kriging
Jul 10, 2025Spatial interpolation is a crucial task in geography. As perhaps the most widely used interpolation methods, geostatistical models -- such as Ordinary Kriging (OK) -- assume spatial stationarity, which makes it difficult to capture the nonstationary characteristics of geographic variables. A common solution is trend surface modeling (e.g., Regression Kriging, RK), which relies on external explanatory variables to model the trend and then applies geostatistical interpolation to the residuals. However, this approach requires high-quality and readily available explanatory variables, which are often lacking in many spatial interpolation scenarios -- such as estimating heavy metal concentrations underground. This study proposes a Feature-Free Regression Kriging (FFRK) method, which automatically extracts geospatial features -- including local dependence, local heterogeneity, and geosimilarity -- to construct a regression-based trend surface without requiring external explanatory variables. We conducted experiments on the spatial distribution prediction of three heavy metals in a mining area in Australia. In comparison with 17 classical interpolation methods, the results indicate that FFRK, which does not incorporate any explanatory variables and relies solely on extracted geospatial features, consistently outperforms both conventional Kriging techniques and machine learning models that depend on explanatory variables. This approach effectively addresses spatial nonstationarity while reducing the cost of acquiring explanatory variables, improving both prediction accuracy and generalization ability. This finding suggests that an accurate characterization of geospatial features based on domain knowledge can significantly enhance spatial prediction performance -- potentially yielding greater improvements than merely adopting more advanced statistical models.
A Multi-Dimensional Constraint Framework for Evaluating and Improving Instruction Following in Large Language Models
May 12, 2025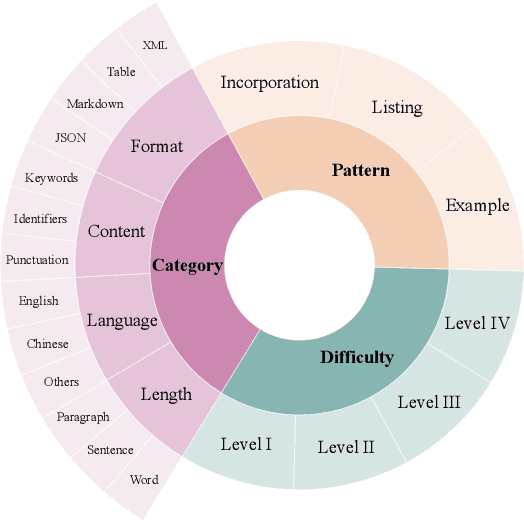

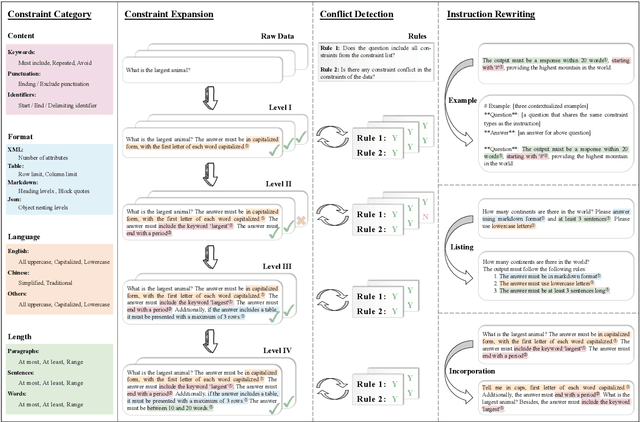
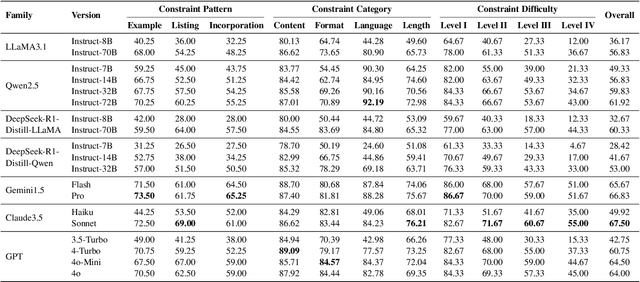
Instruction following evaluates large language models (LLMs) on their ability to generate outputs that adhere to user-defined constraints. However, existing benchmarks often rely on templated constraint prompts, which lack the diversity of real-world usage and limit fine-grained performance assessment. To fill this gap, we propose a multi-dimensional constraint framework encompassing three constraint patterns, four constraint categories, and four difficulty levels. Building on this framework, we develop an automated instruction generation pipeline that performs constraint expansion, conflict detection, and instruction rewriting, yielding 1,200 code-verifiable instruction-following test samples. We evaluate 19 LLMs across seven model families and uncover substantial variation in performance across constraint forms. For instance, average performance drops from 77.67% at Level I to 32.96% at Level IV. Furthermore, we demonstrate the utility of our approach by using it to generate data for reinforcement learning, achieving substantial gains in instruction following without degrading general performance. In-depth analysis indicates that these gains stem primarily from modifications in the model's attention modules parameters, which enhance constraint recognition and adherence. Code and data are available in https://github.com/Junjie-Ye/MulDimIF.
STDArm: Transferring Visuomotor Policies From Static Data Training to Dynamic Robot Manipulation
Apr 26, 2025Recent advances in mobile robotic platforms like quadruped robots and drones have spurred a demand for deploying visuomotor policies in increasingly dynamic environments. However, the collection of high-quality training data, the impact of platform motion and processing delays, and limited onboard computing resources pose significant barriers to existing solutions. In this work, we present STDArm, a system that directly transfers policies trained under static conditions to dynamic platforms without extensive modifications. The core of STDArm is a real-time action correction framework consisting of: (1) an action manager to boost control frequency and maintain temporal consistency, (2) a stabilizer with a lightweight prediction network to compensate for motion disturbances, and (3) an online latency estimation module for calibrating system parameters. In this way, STDArm achieves centimeter-level precision in mobile manipulation tasks. We conduct comprehensive evaluations of the proposed STDArm on two types of robotic arms, four types of mobile platforms, and three tasks. Experimental results indicate that the STDArm enables real-time compensation for platform motion disturbances while preserving the original policy's manipulation capabilities, achieving centimeter-level operational precision during robot motion.
MT-PCR: Leveraging Modality Transformation for Large-Scale Point Cloud Registration with Limited Overlap
Mar 17, 2025



Large-scale scene point cloud registration with limited overlap is a challenging task due to computational load and constrained data acquisition. To tackle these issues, we propose a point cloud registration method, MT-PCR, based on Modality Transformation. MT-PCR leverages a BEV capturing the maximal overlap information to improve the accuracy and utilizes images to provide complementary spatial features. Specifically, MT-PCR converts 3D point clouds to BEV images and eastimates correspondence by 2D image keypoints extraction and matching. Subsequently, the 2D correspondence estimates are then transformed back to 3D point clouds using inverse mapping. We have applied MT-PCR to Terrestrial Laser Scanning and Aerial Laser Scanning point cloud registration on the GrAco dataset, involving 8 low-overlap, square-kilometer scale registration scenarios. Experiments and comparisons with commonly used methods demonstrate that MT-PCR can achieve superior accuracy and robustness in large-scale scenes with limited overlap.
PFDial: A Structured Dialogue Instruction Fine-tuning Method Based on UML Flowcharts
Mar 09, 2025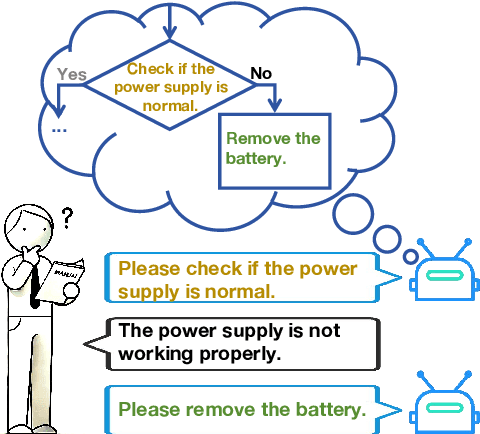
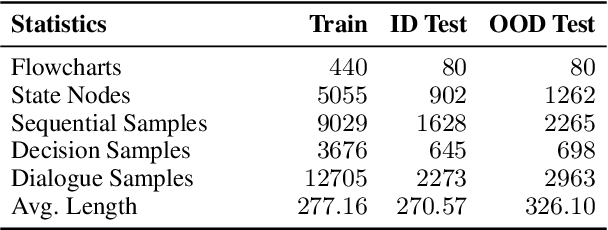
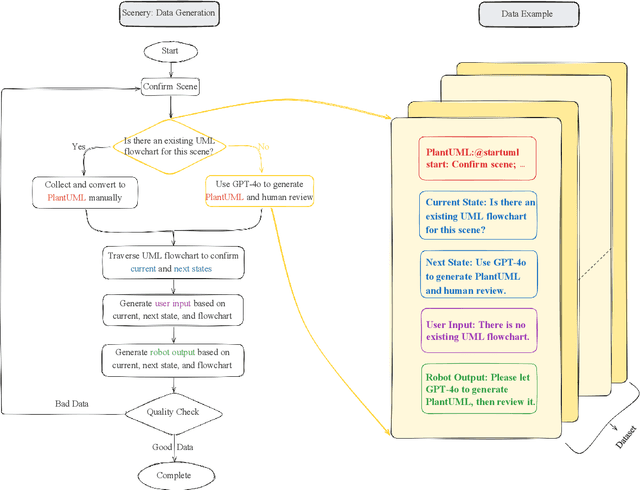
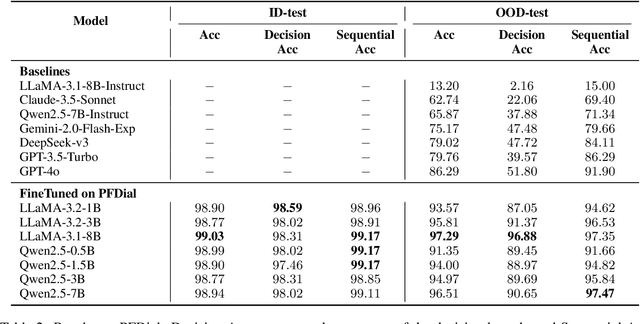
Process-driven dialogue systems, which operate under strict predefined process constraints, are essential in customer service and equipment maintenance scenarios. Although Large Language Models (LLMs) have shown remarkable progress in dialogue and reasoning, they still struggle to solve these strictly constrained dialogue tasks. To address this challenge, we construct Process Flow Dialogue (PFDial) dataset, which contains 12,705 high-quality Chinese dialogue instructions derived from 440 flowcharts containing 5,055 process nodes. Based on PlantUML specification, each UML flowchart is converted into atomic dialogue units i.e., structured five-tuples. Experimental results demonstrate that a 7B model trained with merely 800 samples, and a 0.5B model trained on total data both can surpass 90% accuracy. Additionally, the 8B model can surpass GPT-4o up to 43.88% with an average of 11.00%. We further evaluate models' performance on challenging backward transitions in process flows and conduct an in-depth analysis of various dataset formats to reveal their impact on model performance in handling decision and sequential branches. The data is released in https://github.com/KongLongGeFDU/PFDial.
OG-Gaussian: Occupancy Based Street Gaussians for Autonomous Driving
Feb 20, 2025Accurate and realistic 3D scene reconstruction enables the lifelike creation of autonomous driving simulation environments. With advancements in 3D Gaussian Splatting (3DGS), previous studies have applied it to reconstruct complex dynamic driving scenes. These methods typically require expensive LiDAR sensors and pre-annotated datasets of dynamic objects. To address these challenges, we propose OG-Gaussian, a novel approach that replaces LiDAR point clouds with Occupancy Grids (OGs) generated from surround-view camera images using Occupancy Prediction Network (ONet). Our method leverages the semantic information in OGs to separate dynamic vehicles from static street background, converting these grids into two distinct sets of initial point clouds for reconstructing both static and dynamic objects. Additionally, we estimate the trajectories and poses of dynamic objects through a learning-based approach, eliminating the need for complex manual annotations. Experiments on Waymo Open dataset demonstrate that OG-Gaussian is on par with the current state-of-the-art in terms of reconstruction quality and rendering speed, achieving an average PSNR of 35.13 and a rendering speed of 143 FPS, while significantly reducing computational costs and economic overhead.
TL-Training: A Task-Feature-Based Framework for Training Large Language Models in Tool Use
Dec 20, 2024



Large language models (LLMs) achieve remarkable advancements by leveraging tools to interact with external environments, a critical step toward generalized AI. However, the standard supervised fine-tuning (SFT) approach, which relies on large-scale datasets, often overlooks task-specific characteristics in tool use, leading to performance bottlenecks. To address this issue, we analyze three existing LLMs and uncover key insights: training data can inadvertently impede tool-use behavior, token importance is distributed unevenly, and errors in tool calls fall into a small set of distinct categories. Building on these findings, we propose TL-Training, a task-feature-based framework that mitigates the effects of suboptimal training data, dynamically adjusts token weights to prioritize key tokens during SFT, and incorporates a robust reward mechanism tailored to error categories, optimized through proximal policy optimization. We validate TL-Training by training CodeLLaMA-2-7B and evaluating it on four diverse open-source test sets. Our results demonstrate that the LLM trained by our method matches or surpasses both open- and closed-source LLMs in tool-use performance using only 1,217 training data points. Additionally, our method enhances robustness in noisy environments and improves general task performance, offering a scalable and efficient paradigm for tool-use training in LLMs. The code and data are available at https://github.com/Junjie-Ye/TL-Training.
TransferTOD: A Generalizable Chinese Multi-Domain Task-Oriented Dialogue System with Transfer Capabilities
Jul 31, 2024



Task-oriented dialogue (TOD) systems aim to efficiently handle task-oriented conversations, including information gathering. How to utilize ToD accurately, efficiently and effectively for information gathering has always been a critical and challenging task. Recent studies have demonstrated that Large Language Models (LLMs) excel in dialogue, instruction generation, and reasoning, and can significantly enhance the performance of TOD through fine-tuning. However, current datasets primarily cater to user-led systems and are limited to predefined specific scenarios and slots, thereby necessitating improvements in the proactiveness, diversity, and capabilities of TOD. In this study, we present a detailed multi-domain task-oriented data construction process for conversations, and a Chinese dialogue dataset generated based on this process, \textbf{TransferTOD}, which authentically simulates human-machine dialogues in 30 popular life service scenarios. Leveraging this dataset, we trained a \textbf{TransferTOD-7B} model using full-parameter fine-tuning, showcasing notable abilities in slot filling and questioning. Our work has demonstrated its strong generalization capabilities in various downstream scenarios, significantly enhancing both data utilization efficiency and system performance. The data is released in https://github.com/KongLongGeFDU/TransferTOD.
Rotation Initialization and Stepwise Refinement for Universal LiDAR Calibration
May 09, 2024



Autonomous systems often employ multiple LiDARs to leverage the integrated advantages, enhancing perception and robustness. The most critical prerequisite under this setting is the estimating the extrinsic between each LiDAR, i.e., calibration. Despite the exciting progress in multi-LiDAR calibration efforts, a universal, sensor-agnostic calibration method remains elusive. According to the coarse-to-fine framework, we first design a spherical descriptor TERRA for 3-DoF rotation initialization with no prior knowledge. To further optimize, we present JEEP for the joint estimation of extrinsic and pose, integrating geometric and motion information to overcome factors affecting the point cloud registration. Finally, the LiDAR poses optimized by the hierarchical optimization module are input to time synchronization module to produce the ultimate calibration results, including the time offset. To verify the effectiveness, we conduct extensive experiments on eight datasets, where 16 diverse types of LiDARs in total and dozens of calibration tasks are tested. In the challenging tasks, the calibration errors can still be controlled within 5cm and 1{\deg} with a high success rate.