 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment-Aware Adaptive Pruning with Interleaved Inference Orchestration for Vision-Language-Action Models
Jan 31, 2026While Vision-Language-Action (VLA) models hold promise in embodied intelligence, their large parameter counts lead to substantial inference latency that hinders real-time manipulation, motivating parameter sparsification. However, as the environment evolves during VLA execution, the optimal sparsity patterns change accordingly. Static pruning lacks the adaptability required for environment dynamics, whereas fixed-interval dynamic layer pruning suffers from coarse granularity and high retraining overheads. To bridge this gap, we propose EcoVLA, a training-free, plug-and-play adaptive pruning framework that supports orthogonal combination with existing VLA acceleration methods. EcoVLA comprises two components: Environment-aware Adaptive Pruning (EAP) and Interleaved Inference Orchestration ($I^2O$). EAP is a lightweight adaptive channel pruning method that incorporates the temporal consistency of the physical environment to update sparsity patterns. $I^2O$ leverages the FLOPs bubbles inherent in VLA inference to schedule the pruning method in parallel, ensuring negligible impact on latency. Evaluated on diverse VLA models and benchmarks, EcoVLA delivers state-of-the-art performance, achieving up to 1.60$\times$ speedup with only a 0.4% drop in success rate, and further reaches 2.18$\times$ speedup with only a 0.5% degradation when combined with token pruning. We further validate the effectiveness of EcoVLA on real-world robots.
Diminution: On Reducing the Size of Grounding ASP Programs
Aug 12, 2025Answer Set Programming (ASP) is often hindered by the grounding bottleneck: large Herbrand universes generate ground programs so large that solving becomes difficult. Many methods employ ad-hoc heuristics to improve grounding performance, motivating the need for a more formal and generalizable strategy. We introduce the notion of diminution, defined as a selected subset of the Herbrand universe used to generate a reduced ground program before solving. We give a formal definition of diminution, analyze its key properties, and study the complexity of identifying it. We use a specific encoding that enables off-the-shelf ASP solver to evaluate candidate subsets. Our approach integrates seamlessly with existing grounders via domain predicates. In extensive experiments on five benchmarks, applying diminutions selected by our strategy yields significant performance improvements, reducing grounding time by up to 70% on average and decreasing the size of grounding files by up to 85%. These results demonstrate that leveraging diminutions constitutes a robust and general-purpose approach for alleviating the grounding bottleneck in ASP.
\(X\)-evolve: Solution space evolution powered by large language models
Aug 11, 2025



While combining large language models (LLMs) with evolutionary algorithms (EAs) shows promise for solving complex optimization problems, current approaches typically evolve individual solutions, often incurring high LLM call costs. We introduce \(X\)-evolve, a paradigm-shifting method that instead evolves solution spaces \(X\) (sets of individual solutions) - subsets of the overall search space \(S\). In \(X\)-evolve, LLMs generate tunable programs wherein certain code snippets, designated as parameters, define a tunable solution space. A score-based search algorithm then efficiently explores this parametrically defined space, guided by feedback from objective function scores. This strategy enables broader and more efficient exploration, which can potentially accelerate convergence at a much lower search cost, requiring up to two orders of magnitude fewer LLM calls than prior leading methods. We demonstrate \(X\)-evolve's efficacy across three distinct hard optimization problems. For the cap set problem, we discover a larger partial admissible set, establishing a new tighter asymptotic lower bound for the cap set constant (\(C \ge 2.2203\)). In information theory, we uncover a larger independent set for the 15-vertex cycle graph (\(\mathcal{C}_{15}^{\boxtimes 5}\), size 19,946), thereby raising the known lower bound on its Shannon capacity. Furthermore, for the NP-hard online bin packing problem, we generate heuristics that consistently outperform standard strategies across established benchmarks. By evolving solution spaces, our method considerably improves search effectiveness, making it possible to tackle high-dimensional problems that were previously computationally prohibitive.
SpatialSplat: Efficient Semantic 3D from Sparse Unposed Images
May 29, 2025A major breakthrough in 3D reconstruction is the feedforward paradigm to generate pixel-wise 3D points or Gaussian primitives from sparse, unposed images. To further incorporate semantics while avoiding the significant memory and storage costs of high-dimensional semantic features, existing methods extend this paradigm by associating each primitive with a compressed semantic feature vector. However, these methods have two major limitations: (a) the naively compressed feature compromises expressiveness, affecting the model's ability to capture fine-grained semantics, and (b) the pixel-wise primitive prediction introduces redundancy in overlapping areas, causing unnecessary memory overhead. To this end, we introduce \textbf{SpatialSplat}, a feedforward framework that produces redundancy-aware Gaussians and capitalizes on a dual-field semantic representation. Particularly, with the insight that primitives within the same instance exhibit high semantic consistency, we decompose the semantic representation into a coarse feature field that encodes uncompressed semantics with minimal primitives, and a fine-grained yet low-dimensional feature field that captures detailed inter-instance relationships. Moreover, we propose a selective Gaussian mechanism, which retains only essential Gaussians in the scene, effectively eliminating redundant primitives. Our proposed Spatialsplat learns accurate semantic information and detailed instances prior with more compact 3D Gaussians, making semantic 3D reconstruction more applicable. We conduct extensive experiments to evaluate our method, demonstrating a remarkable 60\% reduction in scene representation parameters while achieving superior performance over state-of-the-art methods. The code will be made available for future investigation.
ElectricSight: 3D Hazard Monitoring for Power Lines Using Low-Cost Sensors
May 10, 2025Protecting power transmission lines from potential hazards involves critical tasks, one of which is the accurate measurement of distances between power lines and potential threats, such as large cranes. The challenge with this task is that the current sensor-based methods face challenges in balancing accuracy and cost in distance measurement. A common practice is to install cameras on transmission towers, which, however, struggle to measure true 3D distances due to the lack of depth information. Although 3D lasers can provide accurate depth data, their high cost makes large-scale deployment impractical. To address this challenge, we present ElectricSight, a system designed for 3D distance measurement and monitoring of potential hazards to power transmission lines. This work's key innovations lie in both the overall system framework and a monocular depth estimation method. Specifically, the system framework combines real-time images with environmental point cloud priors, enabling cost-effective and precise 3D distance measurements. As a core component of the system, the monocular depth estimation method enhances the performance by integrating 3D point cloud data into image-based estimates, improving both the accuracy and reliability of the system. To assess ElectricSight's performance, we conducted tests with data from a real-world power transmission scenario. The experimental results demonstrate that ElectricSight achieves an average accuracy of 1.08 m for distance measurements and an early warning accuracy of 92%.
STDArm: Transferring Visuomotor Policies From Static Data Training to Dynamic Robot Manipulation
Apr 26, 2025Recent advances in mobile robotic platforms like quadruped robots and drones have spurred a demand for deploying visuomotor policies in increasingly dynamic environments. However, the collection of high-quality training data, the impact of platform motion and processing delays, and limited onboard computing resources pose significant barriers to existing solutions. In this work, we present STDArm, a system that directly transfers policies trained under static conditions to dynamic platforms without extensive modifications. The core of STDArm is a real-time action correction framework consisting of: (1) an action manager to boost control frequency and maintain temporal consistency, (2) a stabilizer with a lightweight prediction network to compensate for motion disturbances, and (3) an online latency estimation module for calibrating system parameters. In this way, STDArm achieves centimeter-level precision in mobile manipulation tasks. We conduct comprehensive evaluations of the proposed STDArm on two types of robotic arms, four types of mobile platforms, and three tasks. Experimental results indicate that the STDArm enables real-time compensation for platform motion disturbances while preserving the original policy's manipulation capabilities, achieving centimeter-level operational precision during robot motion.
Research on Navigation Methods Based on LLMs
Apr 22, 2025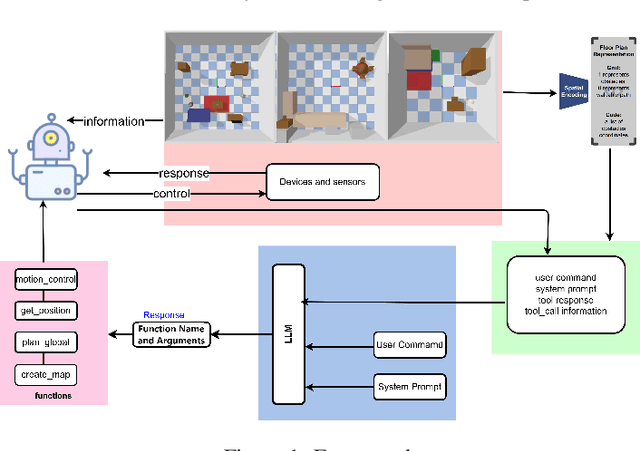



In recent years, the field of indoor navigation has witnessed groundbreaking advancements through the integration of Large Language Models (LLMs). Traditional navigation approaches relying on pre-built maps or reinforcement learning exhibit limitations such as poor generalization and limited adaptability to dynamic environments. In contrast, LLMs offer a novel paradigm for complex indoor navigation tasks by leveraging their exceptional semantic comprehension, reasoning capabilities, and zero-shot generalization properties. We propose an LLM-based navigation framework that leverages function calling capabilities, positioning the LLM as the central controller. Our methodology involves modular decomposition of conventional navigation functions into reusable LLM tools with expandable configurations. This is complemented by a systematically designed, transferable system prompt template and interaction workflow that can be easily adapted across different implementations. Experimental validation in PyBullet simulation environments across diverse scenarios demonstrates the substantial potential and effectiveness of our approach, particularly in achieving context-aware navigation through dynamic tool composition.
Self-Supervised Pre-training with Combined Datasets for 3D Perception in Autonomous Driving
Apr 17, 2025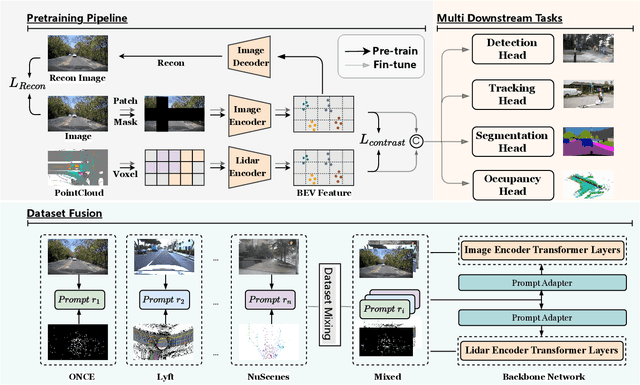

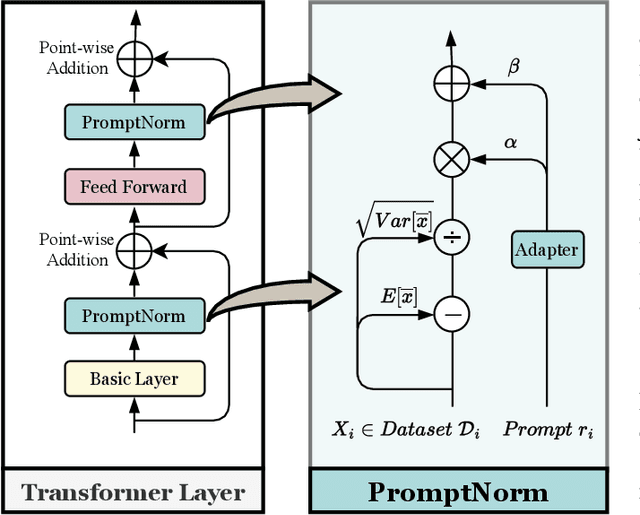

The significant achievements of pre-trained models leveraging large volumes of data in the field of NLP and 2D vision inspire us to explore the potential of extensive data pre-training for 3D perception in autonomous driving. Toward this goal, this paper proposes to utilize massive unlabeled data from heterogeneous datasets to pre-train 3D perception models. We introduce a self-supervised pre-training framework that learns effective 3D representations from scratch on unlabeled data, combined with a prompt adapter based domain adaptation strategy to reduce dataset bias. The approach significantly improves model performance on downstream tasks such as 3D object detection, BEV segmentation, 3D object tracking, and occupancy prediction, and shows steady performance increase as the training data volume scales up, demonstrating the potential of continually benefit 3D perception models for autonomous driving. We will release the source code to inspire further investigations in the community.
CAFE-AD: Cross-Scenario Adaptive Feature Enhancement for Trajectory Planning in Autonomous Driving
Apr 09, 2025Imitation learning based planning tasks on the nuPlan dataset have gained great interest due to their potential to generate human-like driving behaviors. However, open-loop training on the nuPlan dataset tends to cause causal confusion during closed-loop testing, and the dataset also presents a long-tail distribution of scenarios. These issues introduce challenges for imitation learning. To tackle these problems, we introduce CAFE-AD, a Cross-Scenario Adaptive Feature Enhancement for Trajectory Planning in Autonomous Driving method, designed to enhance feature representation across various scenario types. We develop an adaptive feature pruning module that ranks feature importance to capture the most relevant information while reducing the interference of noisy information during training. Moreover, we propose a cross-scenario feature interpolation module that enhances scenario information to introduce diversity, enabling the network to alleviate over-fitting in dominant scenarios. We evaluate our method CAFE-AD on the challenging public nuPlan Test14-Hard closed-loop simulation benchmark. The results demonstrate that CAFE-AD outperforms state-of-the-art methods including rule-based and hybrid planners, and exhibits the potential in mitigating the impact of long-tail distribution within the dataset. Additionally, we further validate its effectiveness in real-world environments. The code and models will be made available at https://github.com/AlniyatRui/CAFE-AD.
GraspCoT: Integrating Physical Property Reasoning for 6-DoF Grasping under Flexible Language Instructions
Mar 20, 2025Flexible instruction-guided 6-DoF grasping is a significant yet challenging task for real-world robotic systems. Existing methods utilize the contextual understanding capabilities of the large language models (LLMs) to establish mappings between expressions and targets, allowing robots to comprehend users' intentions in the instructions. However, the LLM's knowledge about objects' physical properties remains underexplored despite its tight relevance to grasping. In this work, we propose GraspCoT, a 6-DoF grasp detection framework that integrates a Chain-of-Thought (CoT) reasoning mechanism oriented to physical properties, guided by auxiliary question-answering (QA) tasks. Particularly, we design a set of QA templates to enable hierarchical reasoning that includes three stages: target parsing, physical property analysis, and grasp action selection. Moreover, GraspCoT presents a unified multimodal LLM architecture, which encodes multi-view observations of 3D scenes into 3D-aware visual tokens, and then jointly embeds these visual tokens with CoT-derived textual tokens within LLMs to generate grasp pose predictions. Furthermore, we present IntentGrasp, a large-scale benchmark that fills the gap in public datasets for multi-object grasp detection under diverse and indirect verbal commands. Extensive experiments on IntentGrasp demonstrate the superiority of our method, with additional validation in real-world robotic applications confirming its practicality. Codes and data will be released.