 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSGField: A Unified Scene Representation Integrating Motion, Semantics, and Geometry for Robotic Manipulation
Oct 21, 2024Combining accurate geometry with rich semantics has been proven to be highly effective for language-guided robotic manipulation. Existing methods for dynamic scenes either fail to update in real-time or rely on additional depth sensors for simple scene editing, limiting their applicability in real-world. In this paper, we introduce MSGField, a representation that uses a collection of 2D Gaussians for high-quality reconstruction, further enhanced with attributes to encode semantic and motion information. Specially, we represent the motion field compactly by decomposing each primitive's motion into a combination of a limited set of motion bases. Leveraging the differentiable real-time rendering of Gaussian splatting, we can quickly optimize object motion, even for complex non-rigid motions, with image supervision from only two camera views. Additionally, we designed a pipeline that utilizes object priors to efficiently obtain well-defined semantics. In our challenging dataset, which includes flexible and extremely small objects, our method achieve a success rate of 79.2% in static and 63.3% in dynamic environments for language-guided manipulation. For specified object grasping, we achieve a success rate of 90%, on par with point cloud-based methods. Code and dataset will be released at:https://shengyu724.github.io/MSGField.github.io.
DGRC: An Effective Fine-tuning Framework for Distractor Generation in Chinese Multi-choice Reading Comprehension
May 29, 2024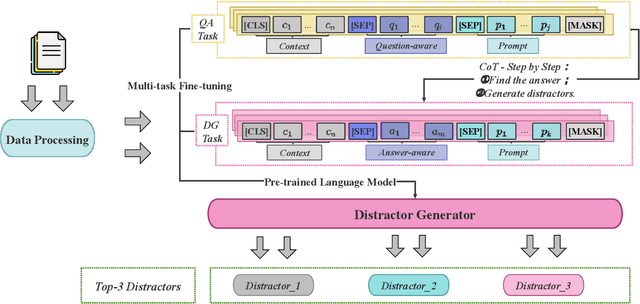
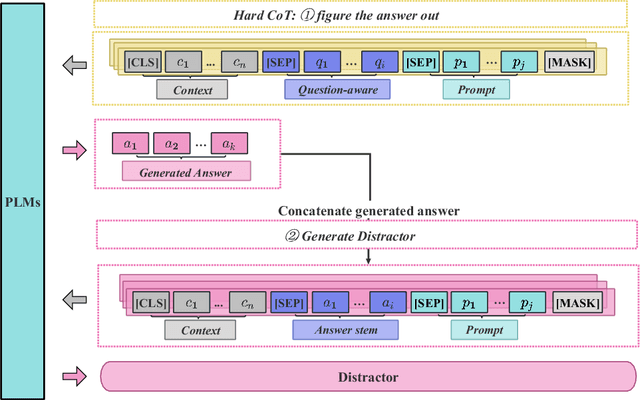
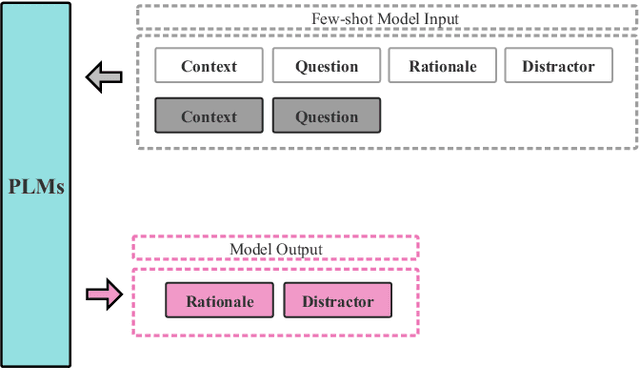
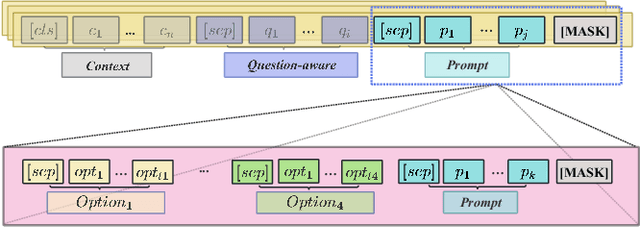
When evaluating a learner's knowledge proficiency, the multiple-choice question is an efficient and widely used format in standardized tests. Nevertheless, generating these questions, particularly plausible distractors (incorrect options), poses a considerable challenge. Generally, the distractor generation can be classified into cloze-style distractor generation (CDG) and natural questions distractor generation (NQDG). In contrast to the CDG, utilizing pre-trained language models (PLMs) for NQDG presents three primary challenges: (1) PLMs are typically trained to generate ``correct'' content, like answers, while rarely trained to generate ``plausible" content, like distractors; (2) PLMs often struggle to produce content that aligns well with specific knowledge and the style of exams; (3) NQDG necessitates the model to produce longer, context-sensitive, and question-relevant distractors. In this study, we introduce a fine-tuning framework named DGRC for NQDG in Chinese multi-choice reading comprehension from authentic examinations. DGRC comprises three major components: hard chain-of-thought, multi-task learning, and generation mask patterns. The experiment results demonstrate that DGRC significantly enhances generation performance, achieving a more than 2.5-fold improvement in BLEU scores.