 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaWorld: Scaling Multi-Agent Video World Model from Single-view Video Data
Jun 01, 2026Video world models are a foundational generative technology for embodied AI and the Metaverse, yet existing approaches are inherently limited to a single agent observing from a single perspective. Extending these models to multi-agent settings introduces two critical challenges: data scarcity (coordinated multi-view recordings are prohibitively expensive to collect for general open-domain scenarios) and world state alignment (independently generated video streams cannot ensure that shared physical environments and events evolve consistently across views). To address these challenges, we propose MetaWorld, a novel framework that scales multi-agent video world models to open-domain environments directly from single-view videos. First, we introduce Monocular World-State Unrolling (MWSU) to explicitly decompose monocular footage into the camera operator's ego-motion and the visible subject's spatial trajectory. This camera-trajectory decomposition naturally extracts synchronized multi-agent motion data within a shared 3D space, completely bypassing the need for multi-camera setups. Second, for precise visual control, we develop the Subject-Aware World Generator to enable appearance-driven simulation conditioned on per-agent identity images. Finally, to ensure both views are grounded in the identical physical reality, we propose World-State Alignment, a per-frame inter-branch cross-attention mechanism inserted at every transformer layer of the video DiT. By jointly synchronizing the denoising process, WSA enforces both static geometric consistency and dynamic motion consistency, encouraging that the shared 3D environment and physical events remain well-aligned across both egocentric views. Extensive experiments demonstrate that MetaWorld achieves superior cross-view consistency and identity fidelity, establishing a highly scalable, physics-driven paradigm for multi-agent video world modeling.
Joint Semantic Token Selection and Prompt Optimization for Interpretable Prompt Learning
May 06, 2026Vision-language models such as CLIP achieve strong visual-textual alignment, but often suffer from overfitting and limited interpretability when adapted through continuous prompt learning. While discrete prompt optimization improves interpretability, it usually depends on large external models, leading to high computational costs and limited scalability. In this paper, we propose Interpretable Prompt Learning (IPL), a hybrid framework that alternates between discrete semantic token selection and continuous prompt optimization. Specifically, IPL formulates semantic token selection as an approximate submodular optimization problem, encouraging tokens that are both human-understandable and semantically diverse. It further adopts an alternating optimization strategy to integrate discrete token selection with continuous prompt tuning, improving interpretability while preserving adaptability to downstream tasks. Our framework is plug-and-play, allowing seamless integration with existing prompt learning methods. Extensive experiments on multiple benchmarks show that IPL consistently improves both interpretability and accuracy across five representative prompt learning methods, providing an effective and scalable extension to existing frameworks.
Distributed Multi-Layer Editing for Rule-Level Knowledge in Large Language Models
Apr 09, 2026Large language models store not only isolated facts but also rules that support reasoning across symbolic expressions, natural language explanations, and concrete instances. Yet most model editing methods are built for fact-level knowledge, assuming that a target edit can be achieved through a localized intervention. This assumption does not hold for rule-level knowledge, where a single rule must remain consistent across multiple interdependent forms. We investigate this problem through a mechanistic study of rule-level knowledge editing. To support this study, we extend the RuleEdit benchmark from 80 to 200 manually verified rules spanning mathematics and physics. Fine-grained causal tracing reveals a form-specific organization of rule knowledge in transformer layers: formulas and descriptions are concentrated in earlier layers, while instances are more associated with middle layers. These results suggest that rule knowledge is not uniformly localized, and therefore cannot be reliably edited by a single-layer or contiguous-block intervention. Based on this insight, we propose Distributed Multi-Layer Editing (DMLE), which applies a shared early-layer update to formulas and descriptions and a separate middle-layer update to instances. While remaining competitive on standard editing metrics, DMLE achieves substantially stronger rule-level editing performance. On average, it improves instance portability and rule understanding by 13.91 and 50.19 percentage points, respectively, over the strongest baseline across GPT-J-6B, Qwen2.5-7B, Qwen2-7B, and LLaMA-3-8B. The code is available at https://github.com/Pepper66/DMLE.
Holistic Optimal Label Selection for Robust Prompt Learning under Partial Labels
Apr 08, 2026Prompt learning has gained significant attention as a parameter-efficient approach for adapting large pre-trained vision-language models to downstream tasks. However, when only partial labels are available, its performance is often limited by label ambiguity and insufficient supervisory information. To address this issue, we propose Holistic Optimal Label Selection (HopS), leveraging the generalization ability of pre-trained feature encoders through two complementary strategies. First, we design a local density-based filter that selects the top frequent labels from the nearest neighbors' candidate sets and uses the softmax scores to identify the most plausible label, capturing structural regularities in the feature space. Second, we introduce a global selection objective based on optimal transport that maps the uniform sampling distribution to the candidate label distributions across a batch. By minimizing the expected transport cost, it can determine the most likely label assignments. These two strategies work together to provide robust label selection from both local and global perspectives. Extensive experiments on eight benchmark datasets show that HopS consistently improves performance under partial supervision and outperforms all baselines. Those results highlight the merit of holistic label selection and offer a practical solution for prompt learning in weakly supervised settings.
AvatarPointillist: AutoRegressive 4D Gaussian Avatarization
Apr 06, 2026We introduce AvatarPointillist, a novel framework for generating dynamic 4D Gaussian avatars from a single portrait image. At the core of our method is a decoder-only Transformer that autoregressively generates a point cloud for 3D Gaussian Splatting. This sequential approach allows for precise, adaptive construction, dynamically adjusting point density and the total number of points based on the subject's complexity. During point generation, the AR model also jointly predicts per-point binding information, enabling realistic animation. After generation, a dedicated Gaussian decoder converts the points into complete, renderable Gaussian attributes. We demonstrate that conditioning the decoder on the latent features from the AR generator enables effective interaction between stages and markedly improves fidelity. Extensive experiments validate that AvatarPointillist produces high-quality, photorealistic, and controllable avatars. We believe this autoregressive formulation represents a new paradigm for avatar generation, and we will release our code inspire future research.
HeadLighter: Disentangling Illumination in Generative 3D Gaussian Heads via Lightstage Captures
Jan 05, 2026Recent 3D-aware head generative models based on 3D Gaussian Splatting achieve real-time, photorealistic and view-consistent head synthesis. However, a fundamental limitation persists: the deep entanglement of illumination and intrinsic appearance prevents controllable relighting. Existing disentanglement methods rely on strong assumptions to enable weakly supervised learning, which restricts their capacity for complex illumination. To address this challenge, we introduce HeadLighter, a novel supervised framework that learns a physically plausible decomposition of appearance and illumination in head generative models. Specifically, we design a dual-branch architecture that separately models lighting-invariant head attributes and physically grounded rendering components. A progressive disentanglement training is employed to gradually inject head appearance priors into the generative architecture, supervised by multi-view images captured under controlled light conditions with a light stage setup. We further introduce a distillation strategy to generate high-quality normals for realistic rendering. Experiments demonstrate that our method preserves high-quality generation and real-time rendering, while simultaneously supporting explicit lighting and viewpoint editing. We will publicly release our code and dataset.
Learning Primitive Embodied World Models: Towards Scalable Robotic Learning
Aug 28, 2025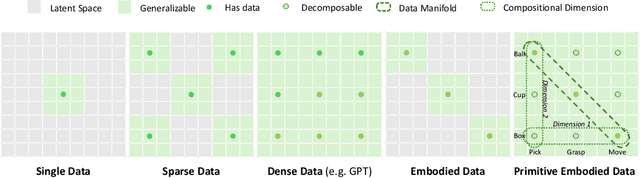



While video-generation-based embodied world models have gained increasing attention, their reliance on large-scale embodied interaction data remains a key bottleneck. The scarcity, difficulty of collection, and high dimensionality of embodied data fundamentally limit the alignment granularity between language and actions and exacerbate the challenge of long-horizon video generation--hindering generative models from achieving a "GPT moment" in the embodied domain. There is a naive observation: the diversity of embodied data far exceeds the relatively small space of possible primitive motions. Based on this insight, we propose a novel paradigm for world modeling--Primitive Embodied World Models (PEWM). By restricting video generation to fixed short horizons, our approach 1) enables fine-grained alignment between linguistic concepts and visual representations of robotic actions, 2) reduces learning complexity, 3) improves data efficiency in embodied data collection, and 4) decreases inference latency. By equipping with a modular Vision-Language Model (VLM) planner and a Start-Goal heatmap Guidance mechanism (SGG), PEWM further enables flexible closed-loop control and supports compositional generalization of primitive-level policies over extended, complex tasks. Our framework leverages the spatiotemporal vision priors in video models and the semantic awareness of VLMs to bridge the gap between fine-grained physical interaction and high-level reasoning, paving the way toward scalable, interpretable, and general-purpose embodied intelligence.
VQ-VLA: Improving Vision-Language-Action Models via Scaling Vector-Quantized Action Tokenizers
Jul 01, 2025In this paper, we introduce an innovative vector quantization based action tokenizer built upon the largest-scale action trajectory dataset to date, leveraging over 100 times more data than previous approaches. This extensive dataset enables our tokenizer to capture rich spatiotemporal dynamics, resulting in a model that not only accelerates inference but also generates smoother and more coherent action outputs. Once trained, the tokenizer can be seamlessly adapted to a wide range of downstream tasks in a zero-shot manner, from short-horizon reactive behaviors to long-horizon planning. A key finding of our work is that the domain gap between synthetic and real action trajectories is marginal, allowing us to effectively utilize a vast amount of synthetic data during training without compromising real-world performance. To validate our approach, we conducted extensive experiments in both simulated environments and on real robotic platforms. The results demonstrate that as the volume of synthetic trajectory data increases, the performance of our tokenizer on downstream tasks improves significantly-most notably, achieving up to a 30% higher success rate on two real-world tasks in long-horizon scenarios. These findings highlight the potential of our action tokenizer as a robust and scalable solution for real-time embodied intelligence systems, paving the way for more efficient and reliable robotic control in diverse application domains.Project website: https://xiaoxiao0406.github.io/vqvla.github.io
MinosEval: Distinguishing Factoid and Non-Factoid for Tailored Open-Ended QA Evaluation with LLMs
Jun 18, 2025Open-ended question answering (QA) is a key task for evaluating the capabilities of large language models (LLMs). Compared to closed-ended QA, it demands longer answer statements, more nuanced reasoning processes, and diverse expressions, making refined and interpretable automatic evaluation both crucial and challenging. Traditional metrics like ROUGE and BERTScore struggle to capture semantic similarities due to different patterns between model responses and reference answers. Current LLM-based evaluation approaches, such as pairwise or listwise comparisons of candidate answers, lack intuitive interpretability. While pointwise scoring of each response provides some descriptions, it fails to adapt across different question contents. Most notably, existing methods overlook the distinction between factoid and non-factoid questions. To address these challenges, we propose \textbf{MinosEval}, a novel evaluation method that first distinguishes open-ended questions and then ranks candidate answers using different evaluation strategies. For factoid questions, it applies an adaptive key-point scoring strategy, while for non-factoid questions, it uses an instance-aware listwise ranking strategy. Experiments on multiple open-ended QA datasets, including self-built ones with more candidate responses to complement community resources, show that MinosEval better aligns with human annotations and offers more interpretable results.
CoMo: Learning Continuous Latent Motion from Internet Videos for Scalable Robot Learning
May 22, 2025Learning latent motion from Internet videos is crucial for building generalist robots. However, existing discrete latent action methods suffer from information loss and struggle with complex and fine-grained dynamics. We propose CoMo, which aims to learn more informative continuous motion representations from diverse, internet-scale videos. CoMo employs a early temporal feature difference mechanism to prevent model collapse and suppress static appearance noise, effectively discouraging shortcut learning problem. Furthermore, guided by the information bottleneck principle, we constrain the latent motion embedding dimensionality to achieve a better balance between retaining sufficient action-relevant information and minimizing the inclusion of action-irrelevant appearance noise. Additionally, we also introduce two new metrics for more robustly and affordably evaluating motion and guiding motion learning methods development: (i) the linear probing MSE of action prediction, and (ii) the cosine similarity between past-to-current and future-to-current motion embeddings. Critically, CoMo exhibits strong zero-shot generalization, enabling it to generate continuous pseudo actions for previously unseen video domains. This capability facilitates unified policy joint learning using pseudo actions derived from various action-less video datasets (such as cross-embodiment videos and, notably, human demonstration videos), potentially augmented with limited labeled robot data. Extensive experiments show that policies co-trained with CoMo pseudo actions achieve superior performance with both diffusion and autoregressive architectures in simulated and real-world settings.