 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinT3R: Window-Based Streaming Reconstruction with Camera Token Pool
Sep 05, 2025We present WinT3R, a feed-forward reconstruction model capable of online prediction of precise camera poses and high-quality point maps. Previous methods suffer from a trade-off between reconstruction quality and real-time performance. To address this, we first introduce a sliding window mechanism that ensures sufficient information exchange among frames within the window, thereby improving the quality of geometric predictions without large computation. In addition, we leverage a compact representation of cameras and maintain a global camera token pool, which enhances the reliability of camera pose estimation without sacrificing efficiency. These designs enable WinT3R to achieve state-of-the-art performance in terms of online reconstruction quality, camera pose estimation, and reconstruction speed, as validated by extensive experiments on diverse datasets. Code and model are publicly available at https://github.com/LiZizun/WinT3R.
Learning Primitive Embodied World Models: Towards Scalable Robotic Learning
Aug 28, 2025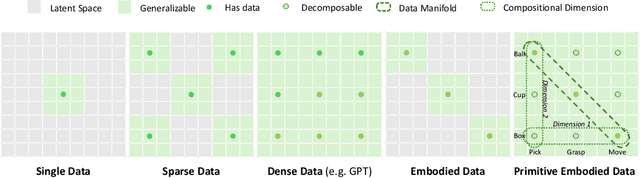



While video-generation-based embodied world models have gained increasing attention, their reliance on large-scale embodied interaction data remains a key bottleneck. The scarcity, difficulty of collection, and high dimensionality of embodied data fundamentally limit the alignment granularity between language and actions and exacerbate the challenge of long-horizon video generation--hindering generative models from achieving a "GPT moment" in the embodied domain. There is a naive observation: the diversity of embodied data far exceeds the relatively small space of possible primitive motions. Based on this insight, we propose a novel paradigm for world modeling--Primitive Embodied World Models (PEWM). By restricting video generation to fixed short horizons, our approach 1) enables fine-grained alignment between linguistic concepts and visual representations of robotic actions, 2) reduces learning complexity, 3) improves data efficiency in embodied data collection, and 4) decreases inference latency. By equipping with a modular Vision-Language Model (VLM) planner and a Start-Goal heatmap Guidance mechanism (SGG), PEWM further enables flexible closed-loop control and supports compositional generalization of primitive-level policies over extended, complex tasks. Our framework leverages the spatiotemporal vision priors in video models and the semantic awareness of VLMs to bridge the gap between fine-grained physical interaction and high-level reasoning, paving the way toward scalable, interpretable, and general-purpose embodied intelligence.
$π^3$: Scalable Permutation-Equivariant Visual Geometry Learning
Jul 17, 2025We introduce $\pi^3$, a feed-forward neural network that offers a novel approach to visual geometry reconstruction, breaking the reliance on a conventional fixed reference view. Previous methods often anchor their reconstructions to a designated viewpoint, an inductive bias that can lead to instability and failures if the reference is suboptimal. In contrast, $\pi^3$ employs a fully permutation-equivariant architecture to predict affine-invariant camera poses and scale-invariant local point maps without any reference frames. This design makes our model inherently robust to input ordering and highly scalable. These advantages enable our simple and bias-free approach to achieve state-of-the-art performance on a wide range of tasks, including camera pose estimation, monocular/video depth estimation, and dense point map reconstruction. Code and models are publicly available.
VQ-VLA: Improving Vision-Language-Action Models via Scaling Vector-Quantized Action Tokenizers
Jul 01, 2025In this paper, we introduce an innovative vector quantization based action tokenizer built upon the largest-scale action trajectory dataset to date, leveraging over 100 times more data than previous approaches. This extensive dataset enables our tokenizer to capture rich spatiotemporal dynamics, resulting in a model that not only accelerates inference but also generates smoother and more coherent action outputs. Once trained, the tokenizer can be seamlessly adapted to a wide range of downstream tasks in a zero-shot manner, from short-horizon reactive behaviors to long-horizon planning. A key finding of our work is that the domain gap between synthetic and real action trajectories is marginal, allowing us to effectively utilize a vast amount of synthetic data during training without compromising real-world performance. To validate our approach, we conducted extensive experiments in both simulated environments and on real robotic platforms. The results demonstrate that as the volume of synthetic trajectory data increases, the performance of our tokenizer on downstream tasks improves significantly-most notably, achieving up to a 30% higher success rate on two real-world tasks in long-horizon scenarios. These findings highlight the potential of our action tokenizer as a robust and scalable solution for real-time embodied intelligence systems, paving the way for more efficient and reliable robotic control in diverse application domains.Project website: https://xiaoxiao0406.github.io/vqvla.github.io
CoMo: Learning Continuous Latent Motion from Internet Videos for Scalable Robot Learning
May 22, 2025Learning latent motion from Internet videos is crucial for building generalist robots. However, existing discrete latent action methods suffer from information loss and struggle with complex and fine-grained dynamics. We propose CoMo, which aims to learn more informative continuous motion representations from diverse, internet-scale videos. CoMo employs a early temporal feature difference mechanism to prevent model collapse and suppress static appearance noise, effectively discouraging shortcut learning problem. Furthermore, guided by the information bottleneck principle, we constrain the latent motion embedding dimensionality to achieve a better balance between retaining sufficient action-relevant information and minimizing the inclusion of action-irrelevant appearance noise. Additionally, we also introduce two new metrics for more robustly and affordably evaluating motion and guiding motion learning methods development: (i) the linear probing MSE of action prediction, and (ii) the cosine similarity between past-to-current and future-to-current motion embeddings. Critically, CoMo exhibits strong zero-shot generalization, enabling it to generate continuous pseudo actions for previously unseen video domains. This capability facilitates unified policy joint learning using pseudo actions derived from various action-less video datasets (such as cross-embodiment videos and, notably, human demonstration videos), potentially augmented with limited labeled robot data. Extensive experiments show that policies co-trained with CoMo pseudo actions achieve superior performance with both diffusion and autoregressive architectures in simulated and real-world settings.
Aether: Geometric-Aware Unified World Modeling
Mar 25, 2025The integration of geometric reconstruction and generative modeling remains a critical challenge in developing AI systems capable of human-like spatial reasoning. This paper proposes Aether, a unified framework that enables geometry-aware reasoning in world models by jointly optimizing three core capabilities: (1) 4D dynamic reconstruction, (2) action-conditioned video prediction, and (3) goal-conditioned visual planning. Through task-interleaved feature learning, Aether achieves synergistic knowledge sharing across reconstruction, prediction, and planning objectives. Building upon video generation models, our framework demonstrates unprecedented synthetic-to-real generalization despite never observing real-world data during training. Furthermore, our approach achieves zero-shot generalization in both action following and reconstruction tasks, thanks to its intrinsic geometric modeling. Remarkably, even without real-world data, its reconstruction performance is comparable with or even better than that of domain-specific models. Additionally, Aether employs camera trajectories as geometry-informed action spaces, enabling effective action-conditioned prediction and visual planning. We hope our work inspires the community to explore new frontiers in physically-reasonable world modeling and its applications.
Tra-MoE: Learning Trajectory Prediction Model from Multiple Domains for Adaptive Policy Conditioning
Nov 21, 2024



Learning from multiple domains is a primary factor that influences the generalization of a single unified robot system. In this paper, we aim to learn the trajectory prediction model by using broad out-of-domain data to improve its performance and generalization ability. Trajectory model is designed to predict any-point trajectories in the current frame given an instruction and can provide detailed control guidance for robotic policy learning. To handle the diverse out-of-domain data distribution, we propose a sparsely-gated MoE (\textbf{Top-1} gating strategy) architecture for trajectory model, coined as \textbf{Tra-MoE}. The sparse activation design enables good balance between parameter cooperation and specialization, effectively benefiting from large-scale out-of-domain data while maintaining constant FLOPs per token. In addition, we further introduce an adaptive policy conditioning technique by learning 2D mask representations for predicted trajectories, which is explicitly aligned with image observations to guide action prediction more flexibly. We perform extensive experiments on both simulation and real-world scenarios to verify the effectiveness of Tra-MoE and adaptive policy conditioning technique. We also conduct a comprehensive empirical study to train Tra-MoE, demonstrating that our Tra-MoE consistently exhibits superior performance compared to the dense baseline model, even when the latter is scaled to match Tra-MoE's parameter count.
DATAP-SfM: Dynamic-Aware Tracking Any Point for Robust Structure from Motion in the Wild
Nov 20, 2024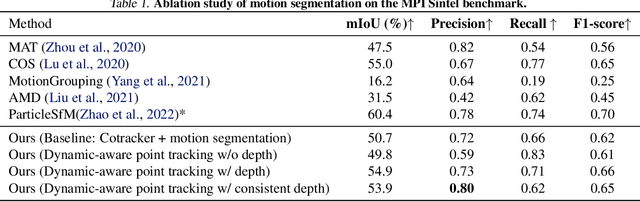
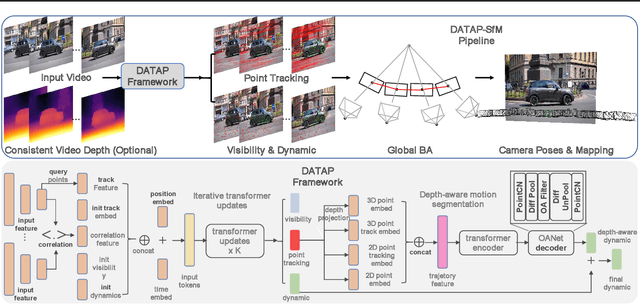
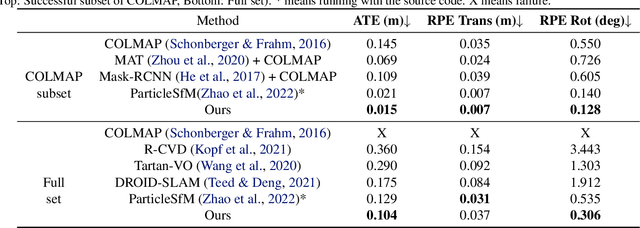

This paper proposes a concise, elegant, and robust pipeline to estimate smooth camera trajectories and obtain dense point clouds for casual videos in the wild. Traditional frameworks, such as ParticleSfM~\cite{zhao2022particlesfm}, address this problem by sequentially computing the optical flow between adjacent frames to obtain point trajectories. They then remove dynamic trajectories through motion segmentation and perform global bundle adjustment. However, the process of estimating optical flow between two adjacent frames and chaining the matches can introduce cumulative errors. Additionally, motion segmentation combined with single-view depth estimation often faces challenges related to scale ambiguity. To tackle these challenges, we propose a dynamic-aware tracking any point (DATAP) method that leverages consistent video depth and point tracking. Specifically, our DATAP addresses these issues by estimating dense point tracking across the video sequence and predicting the visibility and dynamics of each point. By incorporating the consistent video depth prior, the performance of motion segmentation is enhanced. With the integration of DATAP, it becomes possible to estimate and optimize all camera poses simultaneously by performing global bundle adjustments for point tracking classified as static and visible, rather than relying on incremental camera registration. Extensive experiments on dynamic sequences, e.g., Sintel and TUM RGBD dynamic sequences, and on the wild video, e.g., DAVIS, demonstrate that the proposed method achieves state-of-the-art performance in terms of camera pose estimation even in complex dynamic challenge scenes.
SPA: 3D Spatial-Awareness Enables Effective Embodied Representation
Oct 10, 2024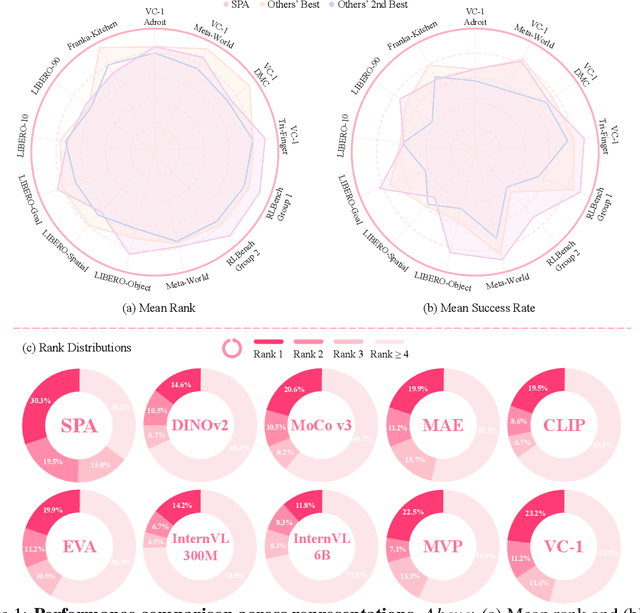
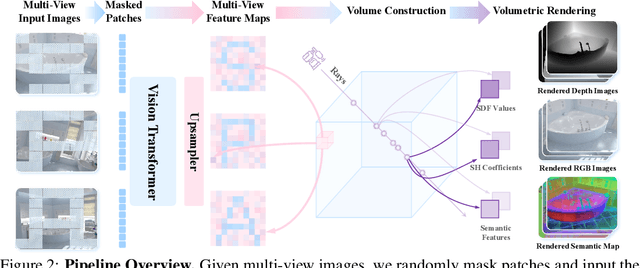

In this paper, we introduce SPA, a novel representation learning framework that emphasizes the importance of 3D spatial awareness in embodied AI. Our approach leverages differentiable neural rendering on multi-view images to endow a vanilla Vision Transformer (ViT) with intrinsic spatial understanding. We present the most comprehensive evaluation of embodied representation learning to date, covering 268 tasks across 8 simulators with diverse policies in both single-task and language-conditioned multi-task scenarios. The results are compelling: SPA consistently outperforms more than 10 state-of-the-art representation methods, including those specifically designed for embodied AI, vision-centric tasks, and multi-modal applications, while using less training data. Furthermore, we conduct a series of real-world experiments to confirm its effectiveness in practical scenarios. These results highlight the critical role of 3D spatial awareness for embodied representation learning. Our strongest model takes more than 6000 GPU hours to train and we are committed to open-sourcing all code and model weights to foster future research in embodied representation learning. Project Page: https://haoyizhu.github.io/spa/.
Point Cloud Matters: Rethinking the Impact of Different Observation Spaces on Robot Learning
Feb 04, 2024



In this study, we explore the influence of different observation spaces on robot learning, focusing on three predominant modalities: RGB, RGB-D, and point cloud. Through extensive experimentation on over 17 varied contact-rich manipulation tasks, conducted across two benchmarks and simulators, we have observed a notable trend: point cloud-based methods, even those with the simplest designs, frequently surpass their RGB and RGB-D counterparts in performance. This remains consistent in both scenarios: training from scratch and utilizing pretraining. Furthermore, our findings indicate that point cloud observations lead to improved policy zero-shot generalization in relation to various geometry and visual clues, including camera viewpoints, lighting conditions, noise levels and background appearance. The outcomes suggest that 3D point cloud is a valuable observation modality for intricate robotic tasks. We will open-source all our codes and checkpoints, hoping that our insights can help design more generalizable and robust robotic models.