 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training
Dec 30, 2025General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-Language Models (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation.
StaMo: Unsupervised Learning of Generalizable Robot Motion from Compact State Representation
Oct 06, 2025A fundamental challenge in embodied intelligence is developing expressive and compact state representations for efficient world modeling and decision making. However, existing methods often fail to achieve this balance, yielding representations that are either overly redundant or lacking in task-critical information. We propose an unsupervised approach that learns a highly compressed two-token state representation using a lightweight encoder and a pre-trained Diffusion Transformer (DiT) decoder, capitalizing on its strong generative prior. Our representation is efficient, interpretable, and integrates seamlessly into existing VLA-based models, improving performance by 14.3% on LIBERO and 30% in real-world task success with minimal inference overhead. More importantly, we find that the difference between these tokens, obtained via latent interpolation, naturally serves as a highly effective latent action, which can be further decoded into executable robot actions. This emergent capability reveals that our representation captures structured dynamics without explicit supervision. We name our method StaMo for its ability to learn generalizable robotic Motion from compact State representation, which is encoded from static images, challenging the prevalent dependence to learning latent action on complex architectures and video data. The resulting latent actions also enhance policy co-training, outperforming prior methods by 10.4% with improved interpretability. Moreover, our approach scales effectively across diverse data sources, including real-world robot data, simulation, and human egocentric video.
Learning Primitive Embodied World Models: Towards Scalable Robotic Learning
Aug 28, 2025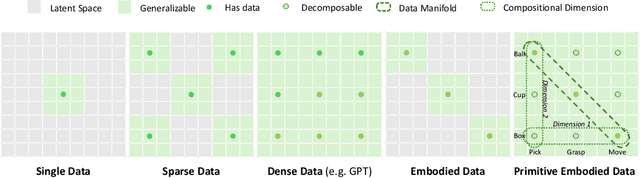



While video-generation-based embodied world models have gained increasing attention, their reliance on large-scale embodied interaction data remains a key bottleneck. The scarcity, difficulty of collection, and high dimensionality of embodied data fundamentally limit the alignment granularity between language and actions and exacerbate the challenge of long-horizon video generation--hindering generative models from achieving a "GPT moment" in the embodied domain. There is a naive observation: the diversity of embodied data far exceeds the relatively small space of possible primitive motions. Based on this insight, we propose a novel paradigm for world modeling--Primitive Embodied World Models (PEWM). By restricting video generation to fixed short horizons, our approach 1) enables fine-grained alignment between linguistic concepts and visual representations of robotic actions, 2) reduces learning complexity, 3) improves data efficiency in embodied data collection, and 4) decreases inference latency. By equipping with a modular Vision-Language Model (VLM) planner and a Start-Goal heatmap Guidance mechanism (SGG), PEWM further enables flexible closed-loop control and supports compositional generalization of primitive-level policies over extended, complex tasks. Our framework leverages the spatiotemporal vision priors in video models and the semantic awareness of VLMs to bridge the gap between fine-grained physical interaction and high-level reasoning, paving the way toward scalable, interpretable, and general-purpose embodied intelligence.
VQ-VLA: Improving Vision-Language-Action Models via Scaling Vector-Quantized Action Tokenizers
Jul 01, 2025In this paper, we introduce an innovative vector quantization based action tokenizer built upon the largest-scale action trajectory dataset to date, leveraging over 100 times more data than previous approaches. This extensive dataset enables our tokenizer to capture rich spatiotemporal dynamics, resulting in a model that not only accelerates inference but also generates smoother and more coherent action outputs. Once trained, the tokenizer can be seamlessly adapted to a wide range of downstream tasks in a zero-shot manner, from short-horizon reactive behaviors to long-horizon planning. A key finding of our work is that the domain gap between synthetic and real action trajectories is marginal, allowing us to effectively utilize a vast amount of synthetic data during training without compromising real-world performance. To validate our approach, we conducted extensive experiments in both simulated environments and on real robotic platforms. The results demonstrate that as the volume of synthetic trajectory data increases, the performance of our tokenizer on downstream tasks improves significantly-most notably, achieving up to a 30% higher success rate on two real-world tasks in long-horizon scenarios. These findings highlight the potential of our action tokenizer as a robust and scalable solution for real-time embodied intelligence systems, paving the way for more efficient and reliable robotic control in diverse application domains.Project website: https://xiaoxiao0406.github.io/vqvla.github.io
CoMo: Learning Continuous Latent Motion from Internet Videos for Scalable Robot Learning
May 22, 2025Learning latent motion from Internet videos is crucial for building generalist robots. However, existing discrete latent action methods suffer from information loss and struggle with complex and fine-grained dynamics. We propose CoMo, which aims to learn more informative continuous motion representations from diverse, internet-scale videos. CoMo employs a early temporal feature difference mechanism to prevent model collapse and suppress static appearance noise, effectively discouraging shortcut learning problem. Furthermore, guided by the information bottleneck principle, we constrain the latent motion embedding dimensionality to achieve a better balance between retaining sufficient action-relevant information and minimizing the inclusion of action-irrelevant appearance noise. Additionally, we also introduce two new metrics for more robustly and affordably evaluating motion and guiding motion learning methods development: (i) the linear probing MSE of action prediction, and (ii) the cosine similarity between past-to-current and future-to-current motion embeddings. Critically, CoMo exhibits strong zero-shot generalization, enabling it to generate continuous pseudo actions for previously unseen video domains. This capability facilitates unified policy joint learning using pseudo actions derived from various action-less video datasets (such as cross-embodiment videos and, notably, human demonstration videos), potentially augmented with limited labeled robot data. Extensive experiments show that policies co-trained with CoMo pseudo actions achieve superior performance with both diffusion and autoregressive architectures in simulated and real-world settings.
Tra-MoE: Learning Trajectory Prediction Model from Multiple Domains for Adaptive Policy Conditioning
Nov 21, 2024



Learning from multiple domains is a primary factor that influences the generalization of a single unified robot system. In this paper, we aim to learn the trajectory prediction model by using broad out-of-domain data to improve its performance and generalization ability. Trajectory model is designed to predict any-point trajectories in the current frame given an instruction and can provide detailed control guidance for robotic policy learning. To handle the diverse out-of-domain data distribution, we propose a sparsely-gated MoE (\textbf{Top-1} gating strategy) architecture for trajectory model, coined as \textbf{Tra-MoE}. The sparse activation design enables good balance between parameter cooperation and specialization, effectively benefiting from large-scale out-of-domain data while maintaining constant FLOPs per token. In addition, we further introduce an adaptive policy conditioning technique by learning 2D mask representations for predicted trajectories, which is explicitly aligned with image observations to guide action prediction more flexibly. We perform extensive experiments on both simulation and real-world scenarios to verify the effectiveness of Tra-MoE and adaptive policy conditioning technique. We also conduct a comprehensive empirical study to train Tra-MoE, demonstrating that our Tra-MoE consistently exhibits superior performance compared to the dense baseline model, even when the latter is scaled to match Tra-MoE's parameter count.
SPA: 3D Spatial-Awareness Enables Effective Embodied Representation
Oct 10, 2024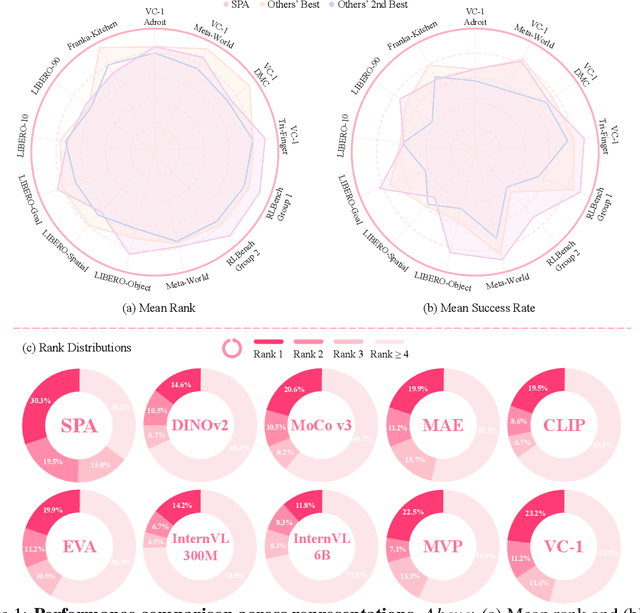
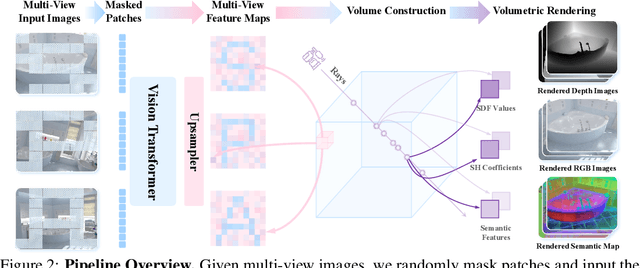

In this paper, we introduce SPA, a novel representation learning framework that emphasizes the importance of 3D spatial awareness in embodied AI. Our approach leverages differentiable neural rendering on multi-view images to endow a vanilla Vision Transformer (ViT) with intrinsic spatial understanding. We present the most comprehensive evaluation of embodied representation learning to date, covering 268 tasks across 8 simulators with diverse policies in both single-task and language-conditioned multi-task scenarios. The results are compelling: SPA consistently outperforms more than 10 state-of-the-art representation methods, including those specifically designed for embodied AI, vision-centric tasks, and multi-modal applications, while using less training data. Furthermore, we conduct a series of real-world experiments to confirm its effectiveness in practical scenarios. These results highlight the critical role of 3D spatial awareness for embodied representation learning. Our strongest model takes more than 6000 GPU hours to train and we are committed to open-sourcing all code and model weights to foster future research in embodied representation learning. Project Page: https://haoyizhu.github.io/spa/.
Spatiotemporal Predictive Pre-training for Robotic Motor Control
Mar 14, 2024Robotic motor control necessitates the ability to predict the dynamics of environments and interaction objects. However, advanced self-supervised pre-trained visual representations (PVRs) in robotic motor control, leveraging large-scale egocentric videos, often focus solely on learning the static content features of sampled image frames. This neglects the crucial temporal motion clues in human video data, which implicitly contain key knowledge about sequential interacting and manipulating with the environments and objects. In this paper, we present a simple yet effective robotic motor control visual pre-training framework that jointly performs spatiotemporal predictive learning utilizing large-scale video data, termed as STP. Our STP samples paired frames from video clips. It adheres to two key designs in a multi-task learning manner. First, we perform spatial prediction on the masked current frame for learning content features. Second, we utilize the future frame with an extremely high masking ratio as a condition, based on the masked current frame, to conduct temporal prediction of future frame for capturing motion features. These efficient designs ensure that our representation focusing on motion information while capturing spatial details. We carry out the largest-scale evaluation of PVRs for robotic motor control to date, which encompasses 21 tasks within a real-world Franka robot arm and 5 simulated environments. Extensive experiments demonstrate the effectiveness of STP as well as unleash its generality and data efficiency by further post-pre-training and hybrid pre-training.
Pave the Way to Grasp Anything: Transferring Foundation Models for Universal Pick-Place Robots
Jun 25, 2023Improving the generalization capabilities of general-purpose robotic agents has long been a significant challenge actively pursued by research communities. Existing approaches often rely on collecting large-scale real-world robotic data, such as the RT-1 dataset. However, these approaches typically suffer from low efficiency, limiting their capability in open-domain scenarios with new objects, and diverse backgrounds. In this paper, we propose a novel paradigm that effectively leverages language-grounded segmentation masks generated by state-of-the-art foundation models, to address a wide range of pick-and-place robot manipulation tasks in everyday scenarios. By integrating precise semantics and geometries conveyed from masks into our multi-view policy model, our approach can perceive accurate object poses and enable sample-efficient learning. Besides, such design facilitates effective generalization for grasping new objects with similar shapes observed during training. Our approach consists of two distinct steps. First, we introduce a series of foundation models to accurately ground natural language demands across multiple tasks. Second, we develop a Multi-modal Multi-view Policy Model that incorporates inputs such as RGB images, semantic masks, and robot proprioception states to jointly predict precise and executable robot actions. Extensive real-world experiments conducted on a Franka Emika robot arm validate the effectiveness of our proposed paradigm. Real-world demos are shown in YouTube (https://www.youtube.com/watch?v=1m9wNzfp_4E ) and Bilibili (https://www.bilibili.com/video/BV178411Z7H2/ ).
AlphaBlock: Embodied Finetuning for Vision-Language Reasoning in Robot Manipulation
May 30, 2023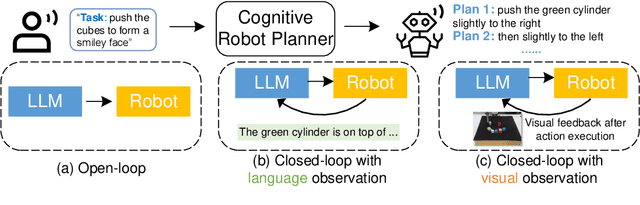

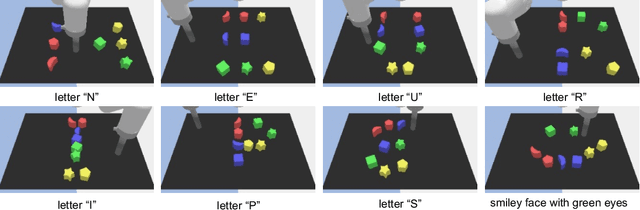

We propose a novel framework for learning high-level cognitive capabilities in robot manipulation tasks, such as making a smiley face using building blocks. These tasks often involve complex multi-step reasoning, presenting significant challenges due to the limited paired data connecting human instructions (e.g., making a smiley face) and robot actions (e.g., end-effector movement). Existing approaches relieve this challenge by adopting an open-loop paradigm decomposing high-level instructions into simple sub-task plans, and executing them step-by-step using low-level control models. However, these approaches are short of instant observations in multi-step reasoning, leading to sub-optimal results. To address this issue, we propose to automatically collect a cognitive robot dataset by Large Language Models (LLMs). The resulting dataset AlphaBlock consists of 35 comprehensive high-level tasks of multi-step text plans and paired observation sequences. To enable efficient data acquisition, we employ elaborated multi-round prompt designs that effectively reduce the burden of extensive human involvement. We further propose a closed-loop multi-modal embodied planning model that autoregressively generates plans by taking image observations as input. To facilitate effective learning, we leverage MiniGPT-4 with a frozen visual encoder and LLM, and finetune additional vision adapter and Q-former to enable fine-grained spatial perception for manipulation tasks. We conduct experiments to verify the superiority over existing open and closed-loop methods, and achieve a significant increase in success rate by 21.4% and 14.5% over ChatGPT and GPT-4 based robot tasks. Real-world demos are shown in https://www.youtube.com/watch?v=ayAzID1_qQk .