 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat to Ignore, What to React: Visually Robust RL Fine-Tuning of VLA Models
May 13, 2026Reinforcement learning (RL) fine-tuning has shown promise for Vision-Language-Action (VLA) models in robotic manipulation, but deployment-time visual shifts pose practical challenges. A key difficulty is that standard task rewards supervise task success, but offer limited guidance on whether a visual change is task-irrelevant or changes the behavior required for manipulation. We propose PAIR-VLA (Paired Action Invariance & Sensitivity for Visually Robust VLA), an RL fine-tuning framework to address this difficulty by adding two auxiliary objectives over paired visual variants during PPO optimization: an invariance term that reduces the discrepancy between action distributions for a task-preserving pair (e.g., different distractors), and a sensitivity objective that encourages separable action distributions for a task-altering pair (e.g., target object in a different pose). Together, these objectives turn visual variants from mere observation diversity into behavior-level guidance on policy responses during RL fine-tuning. We evaluate on ManiSkill3 across two representative VLA architectures, OpenVLA and $π_{0.5}$, under diverse out-of-distribution visual shifts including unseen distractors, texture changes, target object pose variation, viewpoint shifts, and lighting changes. Our method consistently improves over standard PPO, achieving average improvements of 16.62% on $π_{0.5}$ and 9.10% on OpenVLA. Notably, ablations further show generalization across visual shifts: invariance guidance learned from distractor and texture variants transfers to target-pose and lighting shifts, while adding sensitivity guidance on target-pose variants further improves robustness to nuisance shifts, highlighting the broader transferability of behavior-level RL guidance.
CCTVBench: Contrastive Consistency Traffic VideoQA Benchmark for Multimodal LLMs
Apr 22, 2026Safety-critical traffic reasoning requires contrastive consistency: models must detect true hazards when an accident occurs, and reliably reject plausible-but-false hypotheses under near-identical counterfactual scenes. We present CCTVBench, a Contrastive Consistency Traffic VideoQA Benchmark built on paired real accident videos and world-model-generated counterfactual counterparts, together with minimally different, mutually exclusive hypothesis questions. CCTVBench enforces a single structured decision pattern over each video question quadruple and provides actionable diagnostics that decompose failures into positive omission, positive swap, negative hallucination, and mutual-exclusivity violation, while separating video versus question consistency. Experiments across open-source and proprietary video LLMs reveal a large and persistent gap between standard per-instance QA metrics and quadruple-level contrastive consistency, with unreliable none-of-the-above rejection as a key bottleneck. Finally, we introduce C-TCD, a contrastive decoding approach leveraging a semantically exclusive counterpart video as the contrast input at inference time, improving both instance-level QA and contrastive consistency.
LoViF 2026 Challenge on Real-World All-in-One Image Restoration: Methods and Results
Apr 21, 2026This paper presents a review for the LoViF Challenge on Real-World All-in-One Image Restoration. The challenge aimed to advance research on real-world all-in-one image restoration under diverse real-world degradation conditions, including blur, low-light, haze, rain, and snow. It provided a unified benchmark to evaluate the robustness and generalization ability of restoration models across multiple degradation categories within a common framework. The competition attracted 124 registered participants and received 9 valid final submissions with corresponding fact sheets, significantly contributing to the progress of real-world all-in-one image restoration. This report provides a detailed analysis of the submitted methods and corresponding results, emphasizing recent progress in unified real-world image restoration. The analysis highlights effective approaches and establishes a benchmark for future research in real-world low-level vision.
OmniJigsaw: Enhancing Omni-Modal Reasoning via Modality-Orchestrated Reordering
Apr 09, 2026To extend the reinforcement learning post-training paradigm to omni-modal models for concurrently bolstering video-audio understanding and collaborative reasoning, we propose OmniJigsaw, a generic self-supervised framework built upon a temporal reordering proxy task. Centered on the chronological reconstruction of shuffled audio-visual clips, this paradigm strategically orchestrates visual and auditory signals to compel cross-modal integration through three distinct strategies: Joint Modality Integration, Sample-level Modality Selection, and Clip-level Modality Masking. Recognizing that the efficacy of such proxy tasks is fundamentally tied to puzzle quality, we design a two-stage coarse-to-fine data filtering pipeline, which facilitates the efficient adaptation of OmniJigsaw to massive unannotated omni-modal data. Our analysis reveals a ``bi-modal shortcut phenomenon'' in joint modality integration and demonstrates that fine-grained clip-level modality masking mitigates this issue while outperforming sample-level modality selection. Extensive evaluations on 15 benchmarks show substantial gains in video, audio, and collaborative reasoning, validating OmniJigsaw as a scalable paradigm for self-supervised omni-modal learning.
SGTA: Scene-Graph Based Multi-Modal Traffic Agent for Video Understanding
Apr 04, 2026We present Scene-Graph Based Multi-Modal Traffic Agent (SGTA), a modular framework for traffic video understanding that combines structured scene graphs with multi-modal reasoning. It constructs a traffic scene graph from roadside videos using detection, tracking, and lane extraction, followed by tool-based reasoning over both symbolic graph queries and visual inputs. SGTA adopts ReAct to process interleaved reasoning traces from large language models with tool invocations, enabling interpretable decision-making for complex video questions. Experiments on selected TUMTraffic VideoQA dataset sample demonstrate that SGTA achieves competitive accuracy across multiple question types while providing transparent reasoning steps. These results highlight the potential of integrating structured scene representations with multi-modal agents for traffic video understanding.
World Guidance: World Modeling in Condition Space for Action Generation
Feb 25, 2026Leveraging future observation modeling to facilitate action generation presents a promising avenue for enhancing the capabilities of Vision-Language-Action (VLA) models. However, existing approaches struggle to strike a balance between maintaining efficient, predictable future representations and preserving sufficient fine-grained information to guide precise action generation. To address this limitation, we propose WoG (World Guidance), a framework that maps future observations into compact conditions by injecting them into the action inference pipeline. The VLA is then trained to simultaneously predict these compressed conditions alongside future actions, thereby achieving effective world modeling within the condition space for action inference. We demonstrate that modeling and predicting this condition space not only facilitates fine-grained action generation but also exhibits superior generalization capabilities. Moreover, it learns effectively from substantial human manipulation videos. Extensive experiments across both simulation and real-world environments validate that our method significantly outperforms existing methods based on future prediction. Project page is available at: https://selen-suyue.github.io/WoGNet/
VideoAfford: Grounding 3D Affordance from Human-Object-Interaction Videos via Multimodal Large Language Model
Feb 10, 20263D affordance grounding aims to highlight the actionable regions on 3D objects, which is crucial for robotic manipulation. Previous research primarily focused on learning affordance knowledge from static cues such as language and images, which struggle to provide sufficient dynamic interaction context that can reveal temporal and causal cues. To alleviate this predicament, we collect a comprehensive video-based 3D affordance dataset, \textit{VIDA}, which contains 38K human-object-interaction videos covering 16 affordance types, 38 object categories, and 22K point clouds. Based on \textit{VIDA}, we propose a strong baseline: VideoAfford, which activates multimodal large language models with additional affordance segmentation capabilities, enabling both world knowledge reasoning and fine-grained affordance grounding within a unified framework. To enhance action understanding capability, we leverage a latent action encoder to extract dynamic interaction priors from HOI videos. Moreover, we introduce a \textit{spatial-aware} loss function to enable VideoAfford to obtain comprehensive 3D spatial knowledge. Extensive experimental evaluations demonstrate that our model significantly outperforms well-established methods and exhibits strong open-world generalization with affordance reasoning abilities. All datasets and code will be publicly released to advance research in this area.
StaMo: Unsupervised Learning of Generalizable Robot Motion from Compact State Representation
Oct 06, 2025A fundamental challenge in embodied intelligence is developing expressive and compact state representations for efficient world modeling and decision making. However, existing methods often fail to achieve this balance, yielding representations that are either overly redundant or lacking in task-critical information. We propose an unsupervised approach that learns a highly compressed two-token state representation using a lightweight encoder and a pre-trained Diffusion Transformer (DiT) decoder, capitalizing on its strong generative prior. Our representation is efficient, interpretable, and integrates seamlessly into existing VLA-based models, improving performance by 14.3% on LIBERO and 30% in real-world task success with minimal inference overhead. More importantly, we find that the difference between these tokens, obtained via latent interpolation, naturally serves as a highly effective latent action, which can be further decoded into executable robot actions. This emergent capability reveals that our representation captures structured dynamics without explicit supervision. We name our method StaMo for its ability to learn generalizable robotic Motion from compact State representation, which is encoded from static images, challenging the prevalent dependence to learning latent action on complex architectures and video data. The resulting latent actions also enhance policy co-training, outperforming prior methods by 10.4% with improved interpretability. Moreover, our approach scales effectively across diverse data sources, including real-world robot data, simulation, and human egocentric video.
Learning by Imagining: Debiased Feature Augmentation for Compositional Zero-Shot Learning
Sep 16, 2025Compositional Zero-Shot Learning (CZSL) aims to recognize unseen attribute-object compositions by learning prior knowledge of seen primitives, \textit{i.e.}, attributes and objects. Learning generalizable compositional representations in CZSL remains challenging due to the entangled nature of attributes and objects as well as the prevalence of long-tailed distributions in real-world data. Inspired by neuroscientific findings that imagination and perception share similar neural processes, we propose a novel approach called Debiased Feature Augmentation (DeFA) to address these challenges. The proposed DeFA integrates a disentangle-and-reconstruct framework for feature augmentation with a debiasing strategy. DeFA explicitly leverages the prior knowledge of seen attributes and objects by synthesizing high-fidelity composition features to support compositional generalization. Extensive experiments on three widely used datasets demonstrate that DeFA achieves state-of-the-art performance in both \textit{closed-world} and \textit{open-world} settings.
Learning Primitive Embodied World Models: Towards Scalable Robotic Learning
Aug 28, 2025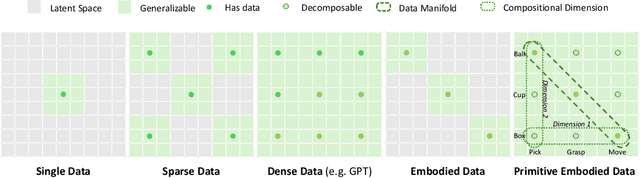



While video-generation-based embodied world models have gained increasing attention, their reliance on large-scale embodied interaction data remains a key bottleneck. The scarcity, difficulty of collection, and high dimensionality of embodied data fundamentally limit the alignment granularity between language and actions and exacerbate the challenge of long-horizon video generation--hindering generative models from achieving a "GPT moment" in the embodied domain. There is a naive observation: the diversity of embodied data far exceeds the relatively small space of possible primitive motions. Based on this insight, we propose a novel paradigm for world modeling--Primitive Embodied World Models (PEWM). By restricting video generation to fixed short horizons, our approach 1) enables fine-grained alignment between linguistic concepts and visual representations of robotic actions, 2) reduces learning complexity, 3) improves data efficiency in embodied data collection, and 4) decreases inference latency. By equipping with a modular Vision-Language Model (VLM) planner and a Start-Goal heatmap Guidance mechanism (SGG), PEWM further enables flexible closed-loop control and supports compositional generalization of primitive-level policies over extended, complex tasks. Our framework leverages the spatiotemporal vision priors in video models and the semantic awareness of VLMs to bridge the gap between fine-grained physical interaction and high-level reasoning, paving the way toward scalable, interpretable, and general-purpose embodied intelligence.