 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboPaint: From Human Demonstration to Any Robot and Any View
Feb 05, 2026Acquiring large-scale, high-fidelity robot demonstration data remains a critical bottleneck for scaling Vision-Language-Action (VLA) models in dexterous manipulation. We propose a Real-Sim-Real data collection and data editing pipeline that transforms human demonstrations into robot-executable, environment-specific training data without direct robot teleoperation. Standardized data collection rooms are built to capture multimodal human demonstrations (synchronized 3 RGB-D videos, 11 RGB videos, 29-DoF glove joint angles, and 14-channel tactile signals). Based on these human demonstrations, we introduce a tactile-aware retargeting method that maps human hand states to robot dex-hand states via geometry and force-guided optimization. Then the retargeted robot trajectories are rendered in a photorealistic Isaac Sim environment to build robot training data. Real world experiments have demonstrated: (1) The retargeted dex-hand trajectories achieve an 84\% success rate across 10 diverse object manipulation tasks. (2) VLA policies (Pi0.5) trained exclusively on our generated data achieve 80\% average success rate on three representative tasks, i.e., pick-and-place, pushing and pouring. To conclude, robot training data can be efficiently "painted" from human demonstrations using our real-sim-real data pipeline. We offer a scalable, cost-effective alternative to teleoperation with minimal performance loss for complex dexterous manipulation.
Tinker: Diffusion's Gift to 3D--Multi-View Consistent Editing From Sparse Inputs without Per-Scene Optimization
Aug 20, 2025



We introduce Tinker, a versatile framework for high-fidelity 3D editing that operates in both one-shot and few-shot regimes without any per-scene finetuning. Unlike prior techniques that demand extensive per-scene optimization to ensure multi-view consistency or to produce dozens of consistent edited input views, Tinker delivers robust, multi-view consistent edits from as few as one or two images. This capability stems from repurposing pretrained diffusion models, which unlocks their latent 3D awareness. To drive research in this space, we curate the first large-scale multi-view editing dataset and data pipeline, spanning diverse scenes and styles. Building on this dataset, we develop our framework capable of generating multi-view consistent edited views without per-scene training, which consists of two novel components: (1) Referring multi-view editor: Enables precise, reference-driven edits that remain coherent across all viewpoints. (2) Any-view-to-video synthesizer: Leverages spatial-temporal priors from video diffusion to perform high-quality scene completion and novel-view generation even from sparse inputs. Through extensive experiments, Tinker significantly reduces the barrier to generalizable 3D content creation, achieving state-of-the-art performance on editing, novel-view synthesis, and rendering enhancement tasks. We believe that Tinker represents a key step towards truly scalable, zero-shot 3D editing. Project webpage: https://aim-uofa.github.io/Tinker
DICEPTION: A Generalist Diffusion Model for Visual Perceptual Tasks
Feb 25, 2025Our primary goal here is to create a good, generalist perception model that can tackle multiple tasks, within limits on computational resources and training data. To achieve this, we resort to text-to-image diffusion models pre-trained on billions of images. Our exhaustive evaluation metrics demonstrate that DICEPTION effectively tackles multiple perception tasks, achieving performance on par with state-of-the-art models. We achieve results on par with SAM-vit-h using only 0.06% of their data (e.g., 600K vs. 1B pixel-level annotated images). Inspired by Wang et al., DICEPTION formulates the outputs of various perception tasks using color encoding; and we show that the strategy of assigning random colors to different instances is highly effective in both entity segmentation and semantic segmentation. Unifying various perception tasks as conditional image generation enables us to fully leverage pre-trained text-to-image models. Thus, DICEPTION can be efficiently trained at a cost of orders of magnitude lower, compared to conventional models that were trained from scratch. When adapting our model to other tasks, it only requires fine-tuning on as few as 50 images and 1% of its parameters. DICEPTION provides valuable insights and a more promising solution for visual generalist models. Homepage: https://aim-uofa.github.io/Diception, Huggingface Demo: https://huggingface.co/spaces/Canyu/Diception-Demo.
GeoBench: Benchmarking and Analyzing Monocular Geometry Estimation Models
Jun 18, 2024



Recent advances in discriminative and generative pretraining have yielded geometry estimation models with strong generalization capabilities. While discriminative monocular geometry estimation methods rely on large-scale fine-tuning data to achieve zero-shot generalization, several generative-based paradigms show the potential of achieving impressive generalization performance on unseen scenes by leveraging pre-trained diffusion models and fine-tuning on even a small scale of synthetic training data. Frustratingly, these models are trained with different recipes on different datasets, making it hard to find out the critical factors that determine the evaluation performance. Besides, current geometry evaluation benchmarks have two main drawbacks that may prevent the development of the field, i.e., limited scene diversity and unfavorable label quality. To resolve the above issues, (1) we build fair and strong baselines in a unified codebase for evaluating and analyzing the geometry estimation models; (2) we evaluate monocular geometry estimators on more challenging benchmarks for geometry estimation task with diverse scenes and high-quality annotations. Our results reveal that pre-trained using large data, discriminative models such as DINOv2, can outperform generative counterparts with a small amount of high-quality synthetic data under the same training configuration, which suggests that fine-tuning data quality is a more important factor than the data scale and model architecture. Our observation also raises a question: if simply fine-tuning a general vision model such as DINOv2 using a small amount of synthetic depth data produces SOTA results, do we really need complex generative models for depth estimation? We believe this work can propel advancements in geometry estimation tasks as well as a wide range of downstream applications.
Diffusion Models Trained with Large Data Are Transferable Visual Models
Mar 15, 2024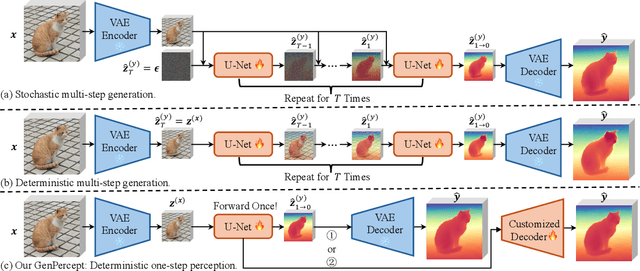


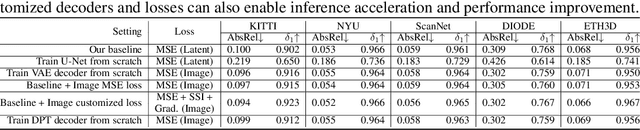
We show that, simply initializing image understanding models using a pre-trained UNet (or transformer) of diffusion models, it is possible to achieve remarkable transferable performance on fundamental vision perception tasks using a moderate amount of target data (even synthetic data only), including monocular depth, surface normal, image segmentation, matting, human pose estimation, among virtually many others. Previous works have adapted diffusion models for various perception tasks, often reformulating these tasks as generation processes to align with the diffusion process. In sharp contrast, we demonstrate that fine-tuning these models with minimal adjustments can be a more effective alternative, offering the advantages of being embarrassingly simple and significantly faster. As the backbone network of Stable Diffusion models is trained on giant datasets comprising billions of images, we observe very robust generalization capabilities of the diffusion backbone. Experimental results showcase the remarkable transferability of the backbone of diffusion models across diverse tasks and real-world datasets.