 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Language Model Inference with Monte Carlo Tree Search
Dec 13, 2025Diffusion language models (DLMs) have recently emerged as a compelling alternative to autoregressive generation, offering parallel generation and improved global coherence. During inference, DLMs generate text by iteratively denoising masked sequences in parallel; however, determining which positions to unmask and which tokens to commit forms a large combinatorial search problem. Existing inference methods approximate this search using heuristics, which often yield suboptimal decoding paths; other approaches instead rely on additional training to guide token selection. To introduce a principled search mechanism for DLMs inference, we introduce MEDAL, a framework that integrates Monte Carlo Tree SEarch initialization for Diffusion LAnguage Model inference. We employ Monte Carlo Tree Search at the initialization stage to explore promising unmasking trajectories, providing a robust starting point for subsequent refinement. This integration is enabled by restricting the search space to high-confidence actions and prioritizing token choices that improve model confidence over remaining masked positions. Across multiple benchmarks, MEDAL achieves up to 22.0% improvement over existing inference strategies, establishing a new paradigm for search-based inference in diffusion language models.
TopoLiDM: Topology-Aware LiDAR Diffusion Models for Interpretable and Realistic LiDAR Point Cloud Generation
Jul 30, 2025LiDAR scene generation is critical for mitigating real-world LiDAR data collection costs and enhancing the robustness of downstream perception tasks in autonomous driving. However, existing methods commonly struggle to capture geometric realism and global topological consistency. Recent LiDAR Diffusion Models (LiDMs) predominantly embed LiDAR points into the latent space for improved generation efficiency, which limits their interpretable ability to model detailed geometric structures and preserve global topological consistency. To address these challenges, we propose TopoLiDM, a novel framework that integrates graph neural networks (GNNs) with diffusion models under topological regularization for high-fidelity LiDAR generation. Our approach first trains a topological-preserving VAE to extract latent graph representations by graph construction and multiple graph convolutional layers. Then we freeze the VAE and generate novel latent topological graphs through the latent diffusion models. We also introduce 0-dimensional persistent homology (PH) constraints, ensuring the generated LiDAR scenes adhere to real-world global topological structures. Extensive experiments on the KITTI-360 dataset demonstrate TopoLiDM's superiority over state-of-the-art methods, achieving improvements of 22.6% lower Frechet Range Image Distance (FRID) and 9.2% lower Minimum Matching Distance (MMD). Notably, our model also enables fast generation speed with an average inference time of 1.68 samples/s, showcasing its scalability for real-world applications. We will release the related codes at https://github.com/IRMVLab/TopoLiDM.
Active-O3: Empowering Multimodal Large Language Models with Active Perception via GRPO
May 27, 2025Active vision, also known as active perception, refers to the process of actively selecting where and how to look in order to gather task-relevant information. It is a critical component of efficient perception and decision-making in humans and advanced embodied agents. Recently, the use of Multimodal Large Language Models (MLLMs) as central planning and decision-making modules in robotic systems has gained extensive attention. However, despite the importance of active perception in embodied intelligence, there is little to no exploration of how MLLMs can be equipped with or learn active perception capabilities. In this paper, we first provide a systematic definition of MLLM-based active perception tasks. We point out that the recently proposed GPT-o3 model's zoom-in search strategy can be regarded as a special case of active perception; however, it still suffers from low search efficiency and inaccurate region selection. To address these issues, we propose ACTIVE-O3, a purely reinforcement learning based training framework built on top of GRPO, designed to equip MLLMs with active perception capabilities. We further establish a comprehensive benchmark suite to evaluate ACTIVE-O3 across both general open-world tasks, such as small-object and dense object grounding, and domain-specific scenarios, including small object detection in remote sensing and autonomous driving, as well as fine-grained interactive segmentation. In addition, ACTIVE-O3 also demonstrates strong zero-shot reasoning abilities on the V* Benchmark, without relying on any explicit reasoning data. We hope that our work can provide a simple codebase and evaluation protocol to facilitate future research on active perception in MLLMs.
Omni-R1: Reinforcement Learning for Omnimodal Reasoning via Two-System Collaboration
May 26, 2025Long-horizon video-audio reasoning and fine-grained pixel understanding impose conflicting requirements on omnimodal models: dense temporal coverage demands many low-resolution frames, whereas precise grounding calls for high-resolution inputs. We tackle this trade-off with a two-system architecture: a Global Reasoning System selects informative keyframes and rewrites the task at low spatial cost, while a Detail Understanding System performs pixel-level grounding on the selected high-resolution snippets. Because ``optimal'' keyframe selection and reformulation are ambiguous and hard to supervise, we formulate them as a reinforcement learning (RL) problem and present Omni-R1, an end-to-end RL framework built on Group Relative Policy Optimization. Omni-R1 trains the Global Reasoning System through hierarchical rewards obtained via online collaboration with the Detail Understanding System, requiring only one epoch of RL on small task splits. Experiments on two challenging benchmarks, namely Referring Audio-Visual Segmentation (RefAVS) and Reasoning Video Object Segmentation (REVOS), show that Omni-R1 not only surpasses strong supervised baselines but also outperforms specialized state-of-the-art models, while substantially improving out-of-domain generalization and mitigating multimodal hallucination. Our results demonstrate the first successful application of RL to large-scale omnimodal reasoning and highlight a scalable path toward universally foundation models.
"I know myself better, but not really greatly": Using LLMs to Detect and Explain LLM-Generated Texts
Feb 18, 2025Large language models (LLMs) have demonstrated impressive capabilities in generating human-like texts, but the potential misuse of such LLM-generated texts raises the need to distinguish between human-generated and LLM-generated content. This paper explores the detection and explanation capabilities of LLM-based detectors of LLM-generated texts, in the context of a binary classification task (human-generated texts vs LLM-generated texts) and a ternary classification task (human-generated texts, LLM-generated texts, and undecided). By evaluating on six close/open-source LLMs with different sizes, our findings reveal that while self-detection consistently outperforms cross-detection, i.e., LLMs can detect texts generated by themselves more accurately than those generated by other LLMs, the performance of self-detection is still far from ideal, indicating that further improvements are needed. We also show that extending the binary to the ternary classification task with a new class "Undecided" can enhance both detection accuracy and explanation quality, with improvements being statistically significant and consistent across all LLMs. We finally conducted comprehensive qualitative and quantitative analyses on the explanation errors, which are categorized into three types: reliance on inaccurate features (the most frequent error), hallucinations, and incorrect reasoning. These findings with our human-annotated dataset emphasize the need for further research into improving both self-detection and self-explanation, particularly to address overfitting issues that may hinder generalization.
Interpreting Object-level Foundation Models via Visual Precision Search
Nov 25, 2024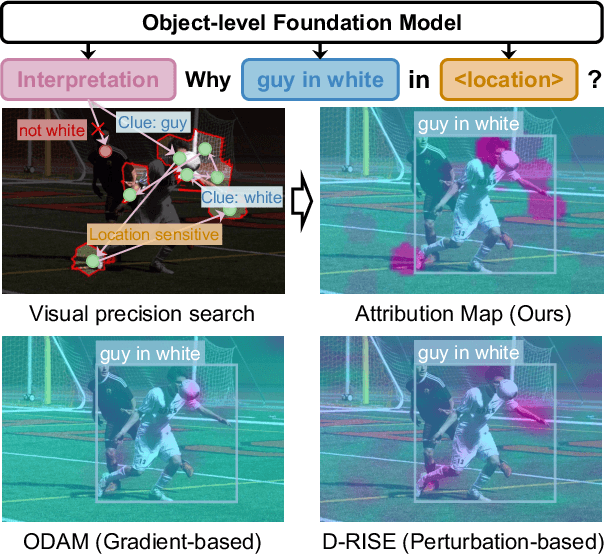
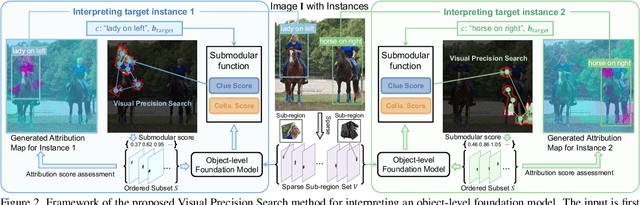
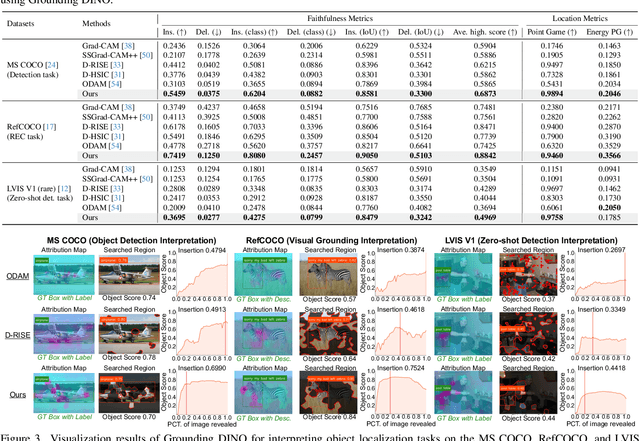
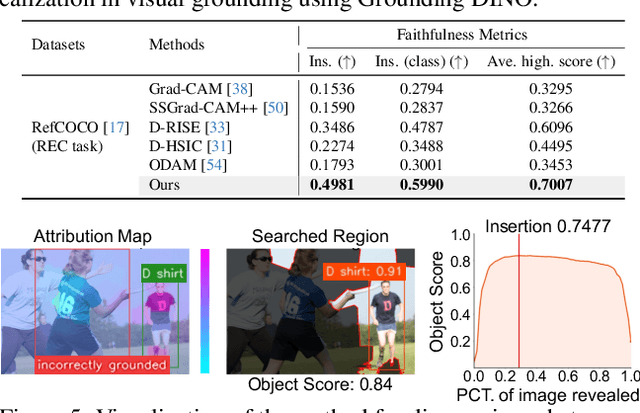
Advances in multimodal pre-training have propelled object-level foundation models, such as Grounding DINO and Florence-2, in tasks like visual grounding and object detection. However, interpreting these models\' decisions has grown increasingly challenging. Existing interpretable attribution methods for object-level task interpretation have notable limitations: (1) gradient-based methods lack precise localization due to visual-textual fusion in foundation models, and (2) perturbation-based methods produce noisy saliency maps, limiting fine-grained interpretability. To address these, we propose a Visual Precision Search method that generates accurate attribution maps with fewer regions. Our method bypasses internal model parameters to overcome attribution issues from multimodal fusion, dividing inputs into sparse sub-regions and using consistency and collaboration scores to accurately identify critical decision-making regions. We also conducted a theoretical analysis of the boundary guarantees and scope of applicability of our method. Experiments on RefCOCO, MS COCO, and LVIS show our approach enhances object-level task interpretability over SOTA for Grounding DINO and Florence-2 across various evaluation metrics, with faithfulness gains of 23.7\%, 31.6\%, and 20.1\% on MS COCO, LVIS, and RefCOCO for Grounding DINO, and 102.9\% and 66.9\% on MS COCO and RefCOCO for Florence-2. Additionally, our method can interpret failures in visual grounding and object detection tasks, surpassing existing methods across multiple evaluation metrics. The code will be released at \url{https://github.com/RuoyuChen10/VPS}.
Detecting Machine-Generated Texts: Not Just "AI vs Humans" and Explainability is Complicated
Jun 26, 2024



As LLMs rapidly advance, increasing concerns arise regarding risks about actual authorship of texts we see online and in real world. The task of distinguishing LLM-authored texts is complicated by the nuanced and overlapping behaviors of both machines and humans. In this paper, we challenge the current practice of considering LLM-generated text detection a binary classification task of differentiating human from AI. Instead, we introduce a novel ternary text classification scheme, adding an "undecided" category for texts that could be attributed to either source, and we show that this new category is crucial to understand how to make the detection result more explainable to lay users. This research shifts the paradigm from merely classifying to explaining machine-generated texts, emphasizing need for detectors to provide clear and understandable explanations to users. Our study involves creating four new datasets comprised of texts from various LLMs and human authors. Based on new datasets, we performed binary classification tests to ascertain the most effective SOTA detection methods and identified SOTA LLMs capable of producing harder-to-detect texts. We constructed a new dataset of texts generated by two top-performing LLMs and human authors, and asked three human annotators to produce ternary labels with explanation notes. This dataset was used to investigate how three top-performing SOTA detectors behave in new ternary classification context. Our results highlight why "undecided" category is much needed from the viewpoint of explainability. Additionally, we conducted an analysis of explainability of the three best-performing detectors and the explanation notes of the human annotators, revealing insights about the complexity of explainable detection of machine-generated texts. Finally, we propose guidelines for developing future detection systems with improved explanatory power.
GeoBench: Benchmarking and Analyzing Monocular Geometry Estimation Models
Jun 18, 2024



Recent advances in discriminative and generative pretraining have yielded geometry estimation models with strong generalization capabilities. While discriminative monocular geometry estimation methods rely on large-scale fine-tuning data to achieve zero-shot generalization, several generative-based paradigms show the potential of achieving impressive generalization performance on unseen scenes by leveraging pre-trained diffusion models and fine-tuning on even a small scale of synthetic training data. Frustratingly, these models are trained with different recipes on different datasets, making it hard to find out the critical factors that determine the evaluation performance. Besides, current geometry evaluation benchmarks have two main drawbacks that may prevent the development of the field, i.e., limited scene diversity and unfavorable label quality. To resolve the above issues, (1) we build fair and strong baselines in a unified codebase for evaluating and analyzing the geometry estimation models; (2) we evaluate monocular geometry estimators on more challenging benchmarks for geometry estimation task with diverse scenes and high-quality annotations. Our results reveal that pre-trained using large data, discriminative models such as DINOv2, can outperform generative counterparts with a small amount of high-quality synthetic data under the same training configuration, which suggests that fine-tuning data quality is a more important factor than the data scale and model architecture. Our observation also raises a question: if simply fine-tuning a general vision model such as DINOv2 using a small amount of synthetic depth data produces SOTA results, do we really need complex generative models for depth estimation? We believe this work can propel advancements in geometry estimation tasks as well as a wide range of downstream applications.
Enhancing Size Generalization in Graph Neural Networks through Disentangled Representation Learning
Jun 07, 2024



Although most graph neural networks (GNNs) can operate on graphs of any size, their classification performance often declines on graphs larger than those encountered during training. Existing methods insufficiently address the removal of size information from graph representations, resulting in sub-optimal performance and reliance on backbone models. In response, we propose DISGEN, a novel and model-agnostic framework designed to disentangle size factors from graph representations. DISGEN employs size- and task-invariant augmentations and introduces a decoupling loss that minimizes shared information in hidden representations, with theoretical guarantees for its effectiveness. Our empirical results show that DISGEN outperforms the state-of-the-art models by up to 6% on real-world datasets, underscoring its effectiveness in enhancing the size generalizability of GNNs. Our codes are available at: https://github.com/GraphmindDartmouth/DISGEN.
Support or Refute: Analyzing the Stance of Evidence to Detect Out-of-Context Mis- and Disinformation
Nov 16, 2023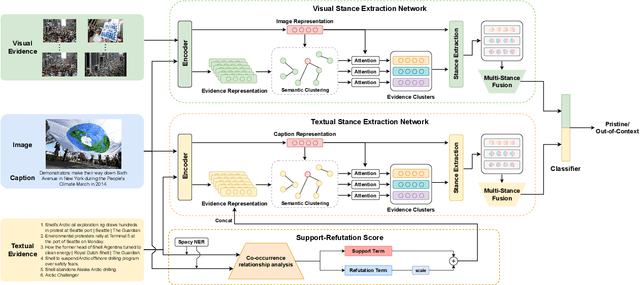
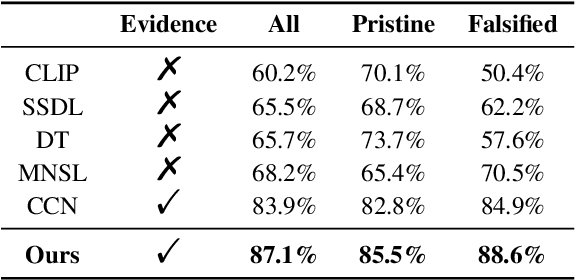
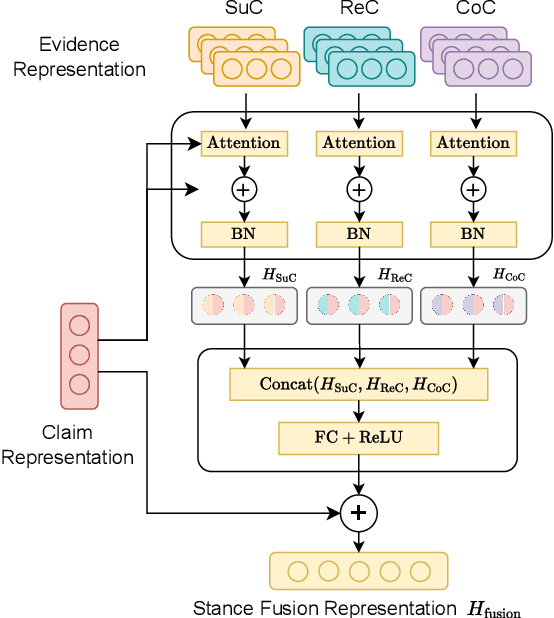
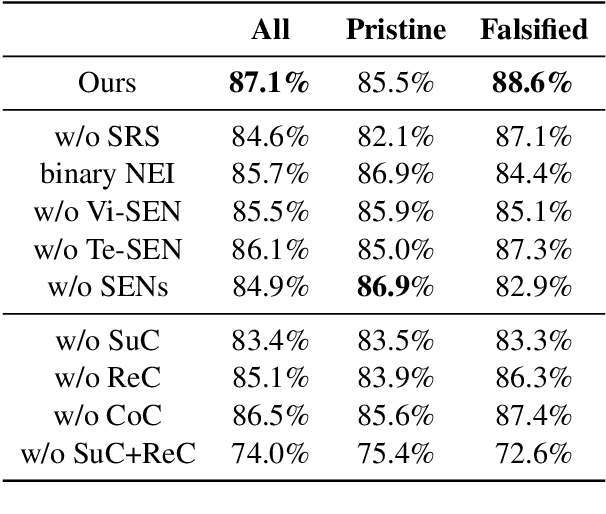
Mis- and disinformation online have become a major societal problem as major sources of online harms of different kinds. One common form of mis- and disinformation is out-of-context (OOC) information, where different pieces of information are falsely associated, e.g., a real image combined with a false textual caption or a misleading textual description. Although some past studies have attempted to defend against OOC mis- and disinformation through external evidence, they tend to disregard the role of different pieces of evidence with different stances. Motivated by the intuition that the stance of evidence represents a bias towards different detection results, we propose a stance extraction network (SEN) that can extract the stances of different pieces of multi-modal evidence in a unified framework. Moreover, we introduce a support-refutation score calculated based on the co-occurrence relations of named entities into the textual SEN. Extensive experiments on a public large-scale dataset demonstrated that our proposed method outperformed the state-of-the-art baselines, with the best model achieving a performance gain of 3.2% in accuracy.