 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Active-O3: Empowering Multimodal Large Language Models with Active Perception via GRPO
May 27, 2025Active vision, also known as active perception, refers to the process of actively selecting where and how to look in order to gather task-relevant information. It is a critical component of efficient perception and decision-making in humans and advanced embodied agents. Recently, the use of Multimodal Large Language Models (MLLMs) as central planning and decision-making modules in robotic systems has gained extensive attention. However, despite the importance of active perception in embodied intelligence, there is little to no exploration of how MLLMs can be equipped with or learn active perception capabilities. In this paper, we first provide a systematic definition of MLLM-based active perception tasks. We point out that the recently proposed GPT-o3 model's zoom-in search strategy can be regarded as a special case of active perception; however, it still suffers from low search efficiency and inaccurate region selection. To address these issues, we propose ACTIVE-O3, a purely reinforcement learning based training framework built on top of GRPO, designed to equip MLLMs with active perception capabilities. We further establish a comprehensive benchmark suite to evaluate ACTIVE-O3 across both general open-world tasks, such as small-object and dense object grounding, and domain-specific scenarios, including small object detection in remote sensing and autonomous driving, as well as fine-grained interactive segmentation. In addition, ACTIVE-O3 also demonstrates strong zero-shot reasoning abilities on the V* Benchmark, without relying on any explicit reasoning data. We hope that our work can provide a simple codebase and evaluation protocol to facilitate future research on active perception in MLLMs.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025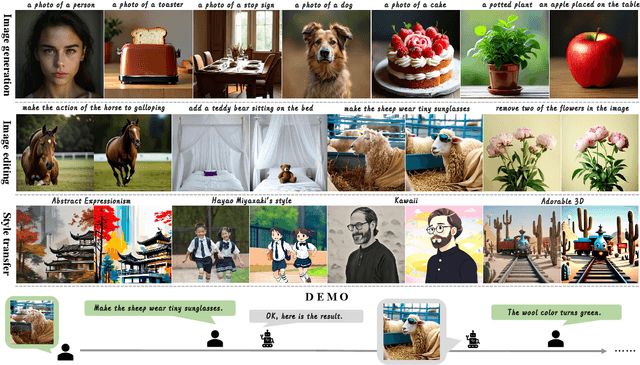

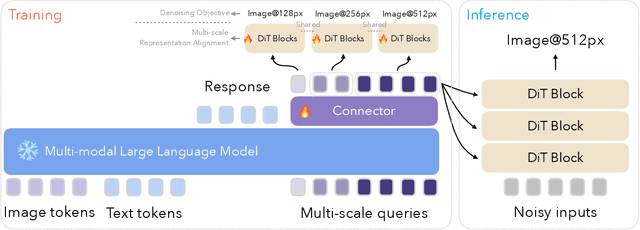
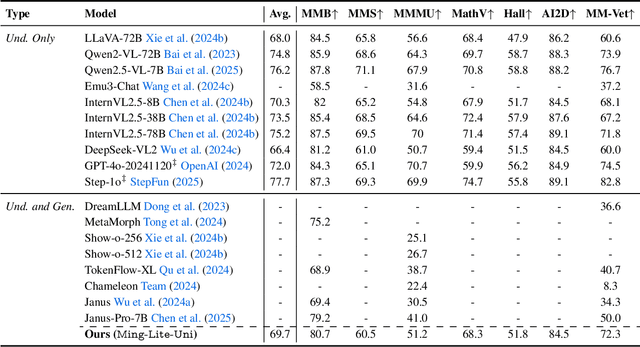
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
Try-On-Adapter: A Simple and Flexible Try-On Paradigm
Nov 15, 2024
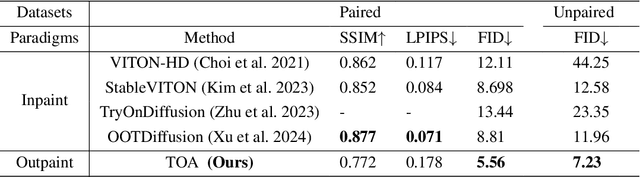
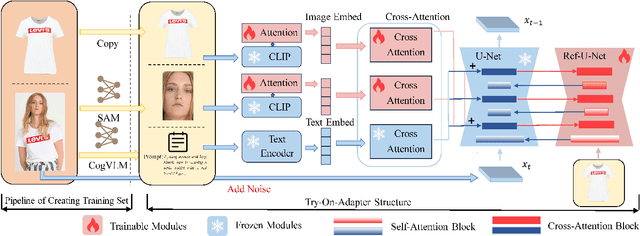

Image-based virtual try-on, widely used in online shopping, aims to generate images of a naturally dressed person conditioned on certain garments, providing significant research and commercial potential. A key challenge of try-on is to generate realistic images of the model wearing the garments while preserving the details of the garments. Previous methods focus on masking certain parts of the original model's standing image, and then inpainting on masked areas to generate realistic images of the model wearing corresponding reference garments, which treat the try-on task as an inpainting task. However, such implements require the user to provide a complete, high-quality standing image, which is user-unfriendly in practical applications. In this paper, we propose Try-On-Adapter (TOA), an outpainting paradigm that differs from the existing inpainting paradigm. Our TOA can preserve the given face and garment, naturally imagine the rest parts of the image, and provide flexible control ability with various conditions, e.g., garment properties and human pose. In the experiments, TOA shows excellent performance on the virtual try-on task even given relatively low-quality face and garment images in qualitative comparisons. Additionally, TOA achieves the state-of-the-art performance of FID scores 5.56 and 7.23 for paired and unpaired on the VITON-HD dataset in quantitative comparisons.
StyleTokenizer: Defining Image Style by a Single Instance for Controlling Diffusion Models
Sep 04, 2024



Despite the burst of innovative methods for controlling the diffusion process, effectively controlling image styles in text-to-image generation remains a challenging task. Many adapter-based methods impose image representation conditions on the denoising process to accomplish image control. However these conditions are not aligned with the word embedding space, leading to interference between image and text control conditions and the potential loss of semantic information from the text prompt. Addressing this issue involves two key challenges. Firstly, how to inject the style representation without compromising the effectiveness of text representation in control. Secondly, how to obtain the accurate style representation from a single reference image. To tackle these challenges, we introduce StyleTokenizer, a zero-shot style control image generation method that aligns style representation with text representation using a style tokenizer. This alignment effectively minimizes the impact on the effectiveness of text prompts. Furthermore, we collect a well-labeled style dataset named Style30k to train a style feature extractor capable of accurately representing style while excluding other content information. Experimental results demonstrate that our method fully grasps the style characteristics of the reference image, generating appealing images that are consistent with both the target image style and text prompt. The code and dataset are available at https://github.com/alipay/style-tokenizer.
Zippo: Zipping Color and Transparency Distributions into a Single Diffusion Model
Mar 19, 2024



Beyond the superiority of the text-to-image diffusion model in generating high-quality images, recent studies have attempted to uncover its potential for adapting the learned semantic knowledge to visual perception tasks. In this work, instead of translating a generative diffusion model into a visual perception model, we explore to retain the generative ability with the perceptive adaptation. To accomplish this, we present Zippo, a unified framework for zipping the color and transparency distributions into a single diffusion model by expanding the diffusion latent into a joint representation of RGB images and alpha mattes. By alternatively selecting one modality as the condition and then applying the diffusion process to the counterpart modality, Zippo is capable of generating RGB images from alpha mattes and predicting transparency from input images. In addition to single-modality prediction, we propose a modality-aware noise reassignment strategy to further empower Zippo with jointly generating RGB images and its corresponding alpha mattes under the text guidance. Our experiments showcase Zippo's ability of efficient text-conditioned transparent image generation and present plausible results of Matte-to-RGB and RGB-to-Matte translation.
DC-Former: Diverse and Compact Transformer for Person Re-Identification
Feb 28, 2023In person re-identification (re-ID) task, it is still challenging to learn discriminative representation by deep learning, due to limited data. Generally speaking, the model will get better performance when increasing the amount of data. The addition of similar classes strengthens the ability of the classifier to identify similar identities, thereby improving the discrimination of representation. In this paper, we propose a Diverse and Compact Transformer (DC-Former) that can achieve a similar effect by splitting embedding space into multiple diverse and compact subspaces. Compact embedding subspace helps model learn more robust and discriminative embedding to identify similar classes. And the fusion of these diverse embeddings containing more fine-grained information can further improve the effect of re-ID. Specifically, multiple class tokens are used in vision transformer to represent multiple embedding spaces. Then, a self-diverse constraint (SDC) is applied to these spaces to push them away from each other, which makes each embedding space diverse and compact. Further, a dynamic weight controller(DWC) is further designed for balancing the relative importance among them during training. The experimental results of our method are promising, which surpass previous state-of-the-art methods on several commonly used person re-ID benchmarks.
Solutions for Fine-grained and Long-tailed Snake Species Recognition in SnakeCLEF 2022
Jul 04, 2022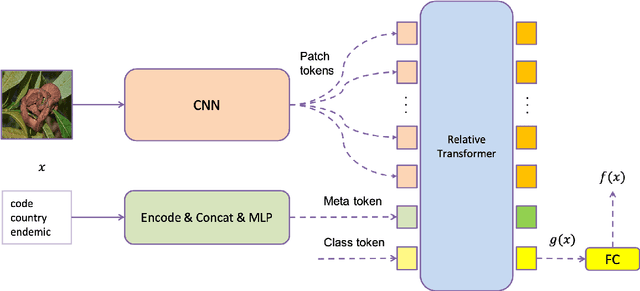
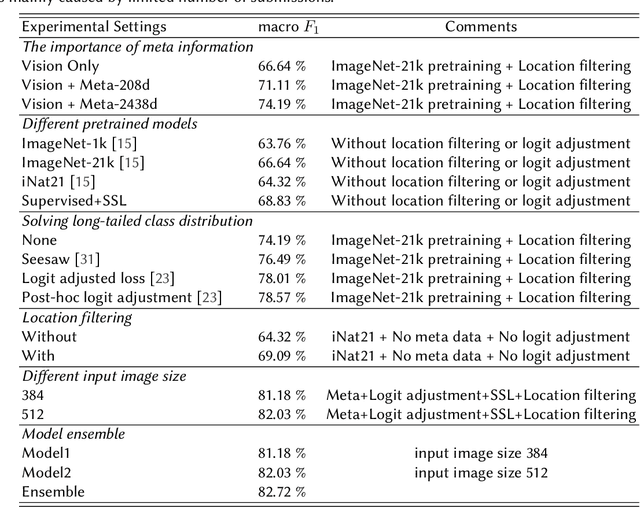

Automatic snake species recognition is important because it has vast potential to help lower deaths and disabilities caused by snakebites. We introduce our solution in SnakeCLEF 2022 for fine-grained snake species recognition on a heavy long-tailed class distribution. First, a network architecture is designed to extract and fuse features from multiple modalities, i.e. photograph from visual modality and geographic locality information from language modality. Then, logit adjustment based methods are studied to relieve the impact caused by the severe class imbalance. Next, a combination of supervised and self-supervised learning method is proposed to make full use of the dataset, including both labeled training data and unlabeled testing data. Finally, post processing strategies, such as multi-scale and multi-crop test-time-augmentation, location filtering and model ensemble, are employed for better performance. With an ensemble of several different models, a private score 82.65%, ranking the 3rd, is achieved on the final leaderboard.
Improving Human-Object Interaction Detection via Phrase Learning and Label Composition
Dec 14, 2021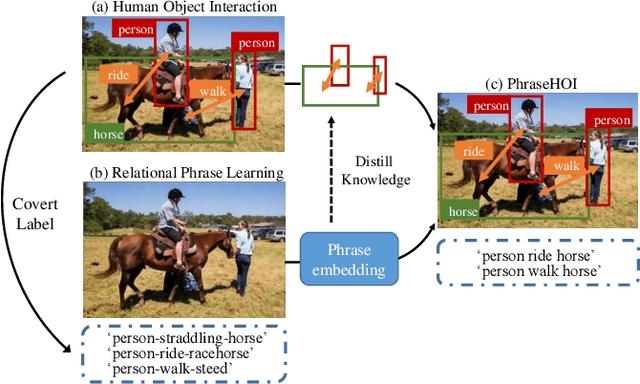

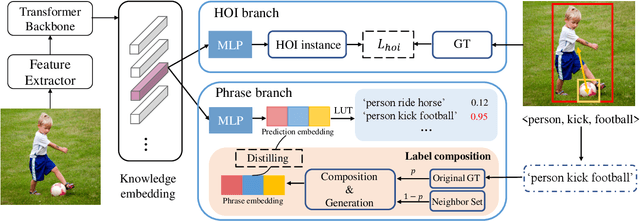

Human-Object Interaction (HOI) detection is a fundamental task in high-level human-centric scene understanding. We propose PhraseHOI, containing a HOI branch and a novel phrase branch, to leverage language prior and improve relation expression. Specifically, the phrase branch is supervised by semantic embeddings, whose ground truths are automatically converted from the original HOI annotations without extra human efforts. Meanwhile, a novel label composition method is proposed to deal with the long-tailed problem in HOI, which composites novel phrase labels by semantic neighbors. Further, to optimize the phrase branch, a loss composed of a distilling loss and a balanced triplet loss is proposed. Extensive experiments are conducted to prove the effectiveness of the proposed PhraseHOI, which achieves significant improvement over the baseline and surpasses previous state-of-the-art methods on Full and NonRare on the challenging HICO-DET benchmark.
HBReID: Harder Batch for Re-identification
Dec 09, 2021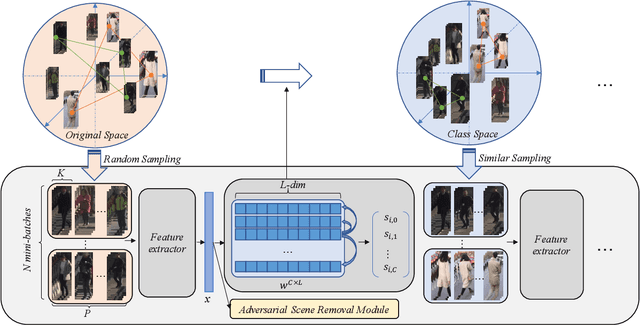
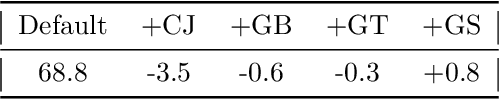

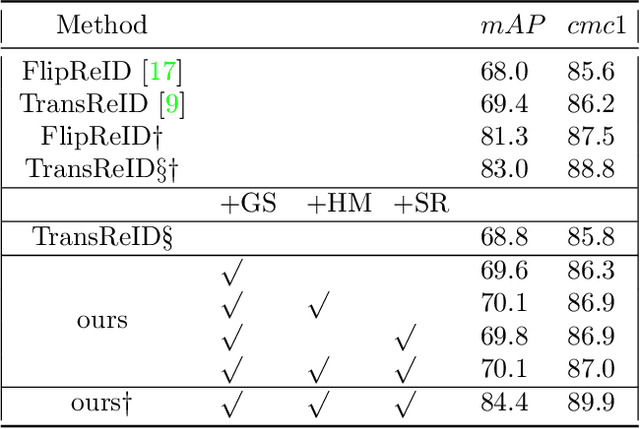
Triplet loss is a widely adopted loss function in ReID task which pulls the hardest positive pairs close and pushes the hardest negative pairs far away. However, the selected samples are not the hardest globally, but the hardest only in a mini-batch, which will affect the performance. In this report, a hard batch mining method is proposed to mine the hardest samples globally to make triplet harder. More specifically, the most similar classes are selected into a same mini-batch so that the similar classes could be pushed further away. Besides, an adversarial scene removal module composed of a scene classifier and an adversarial loss is used to learn scene invariant feature representations. Experiments are conducted on dataset MSMT17 to prove the effectiveness, and our method surpasses all of the previous methods and sets state-of-the-art result.