 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGenSeg: Image Segmentation with Autoregressive Image Generation Model
Oct 23, 2025
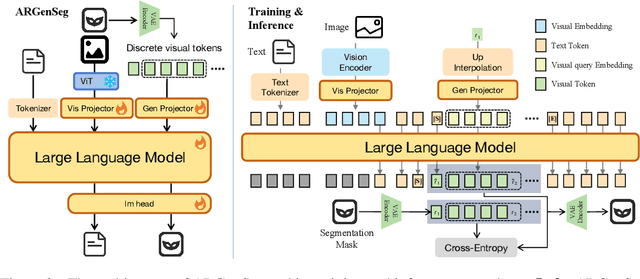
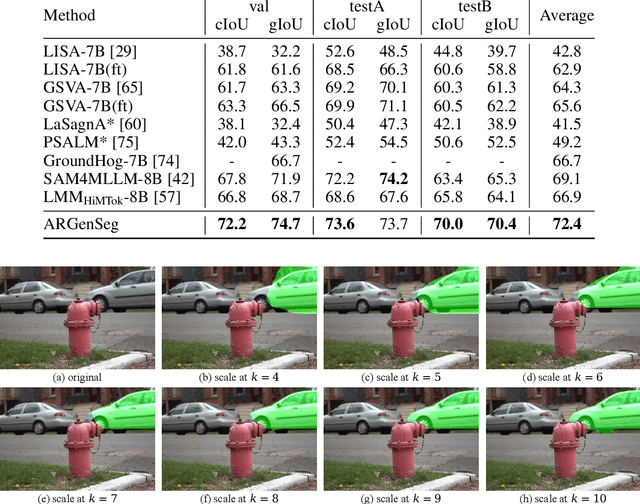

We propose a novel AutoRegressive Generation-based paradigm for image Segmentation (ARGenSeg), achieving multimodal understanding and pixel-level perception within a unified framework. Prior works integrating image segmentation into multimodal large language models (MLLMs) typically employ either boundary points representation or dedicated segmentation heads. These methods rely on discrete representations or semantic prompts fed into task-specific decoders, which limits the ability of the MLLM to capture fine-grained visual details. To address these challenges, we introduce a segmentation framework for MLLM based on image generation, which naturally produces dense masks for target objects. We leverage MLLM to output visual tokens and detokenize them into images using an universal VQ-VAE, making the segmentation fully dependent on the pixel-level understanding of the MLLM. To reduce inference latency, we employ a next-scale-prediction strategy to generate required visual tokens in parallel. Extensive experiments demonstrate that our method surpasses prior state-of-the-art approaches on multiple segmentation datasets with a remarkable boost in inference speed, while maintaining strong understanding capabilities.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025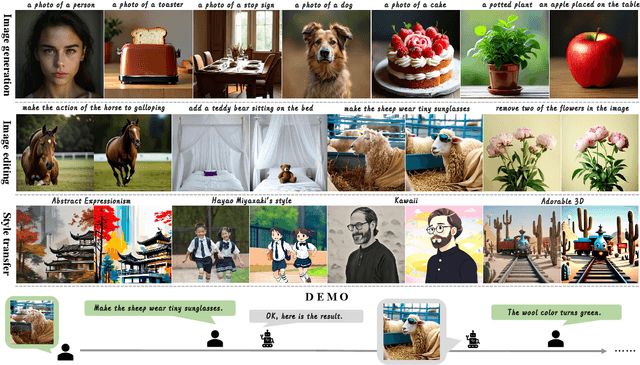

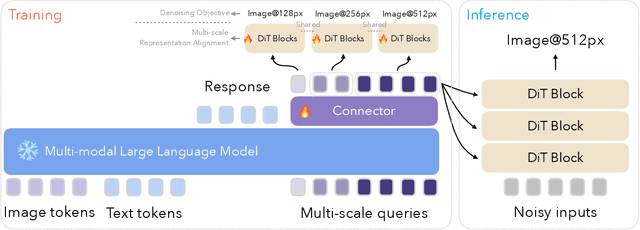
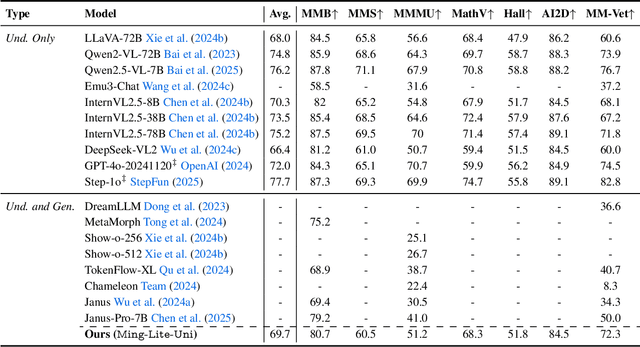
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
Accelerating Pre-training of Multimodal LLMs via Chain-of-Sight
Jul 22, 2024

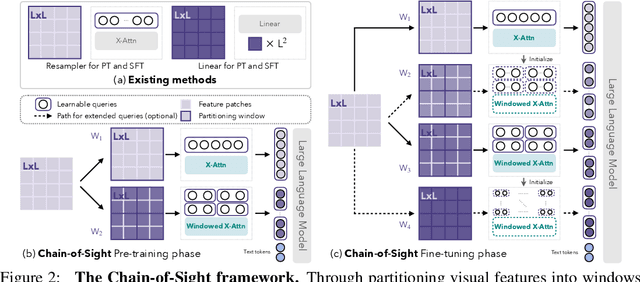

This paper introduces Chain-of-Sight, a vision-language bridge module that accelerates the pre-training of Multimodal Large Language Models (MLLMs). Our approach employs a sequence of visual resamplers that capture visual details at various spacial scales. This architecture not only leverages global and local visual contexts effectively, but also facilitates the flexible extension of visual tokens through a compound token scaling strategy, allowing up to a 16x increase in the token count post pre-training. Consequently, Chain-of-Sight requires significantly fewer visual tokens in the pre-training phase compared to the fine-tuning phase. This intentional reduction of visual tokens during pre-training notably accelerates the pre-training process, cutting down the wall-clock training time by ~73%. Empirical results on a series of vision-language benchmarks reveal that the pre-train acceleration through Chain-of-Sight is achieved without sacrificing performance, matching or surpassing the standard pipeline of utilizing all visual tokens throughout the entire training process. Further scaling up the number of visual tokens for pre-training leads to stronger performances, competitive to existing approaches in a series of benchmarks.
OrchMoE: Efficient Multi-Adapter Learning with Task-Skill Synergy
Jan 19, 2024We advance the field of Parameter-Efficient Fine-Tuning (PEFT) with our novel multi-adapter method, OrchMoE, which capitalizes on modular skill architecture for enhanced forward transfer in neural networks. Unlike prior models that depend on explicit task identification inputs, OrchMoE automatically discerns task categories, streamlining the learning process. This is achieved through an integrated mechanism comprising an Automatic Task Classification module and a Task-Skill Allocation module, which collectively deduce task-specific classifications and tailor skill allocation matrices. Our extensive evaluations on the 'Super Natural Instructions' dataset, featuring 1,600 diverse instructional tasks, indicate that OrchMoE substantially outperforms comparable multi-adapter baselines in terms of both performance and sample utilization efficiency, all while operating within the same parameter constraints. These findings suggest that OrchMoE offers a significant leap forward in multi-task learning efficiency.
Learning Implicit Entity-object Relations by Bidirectional Generative Alignment for Multimodal NER
Aug 03, 2023



The challenge posed by multimodal named entity recognition (MNER) is mainly two-fold: (1) bridging the semantic gap between text and image and (2) matching the entity with its associated object in image. Existing methods fail to capture the implicit entity-object relations, due to the lack of corresponding annotation. In this paper, we propose a bidirectional generative alignment method named BGA-MNER to tackle these issues. Our BGA-MNER consists of \texttt{image2text} and \texttt{text2image} generation with respect to entity-salient content in two modalities. It jointly optimizes the bidirectional reconstruction objectives, leading to aligning the implicit entity-object relations under such direct and powerful constraints. Furthermore, image-text pairs usually contain unmatched components which are noisy for generation. A stage-refined context sampler is proposed to extract the matched cross-modal content for generation. Extensive experiments on two benchmarks demonstrate that our method achieves state-of-the-art performance without image input during inference.