 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich-U-Net: A medical image segmentation model for fusing spatial depth features and capturing minute structural details
Mar 31, 2026Medical image segmentation is of great significance in analysis of illness. The use of deep neural networks in medical image segmentation can help doctors extract regions of interest from complex medical images, thereby improving diagnostic accuracy and enabling better assessment of the condition to formulate treatment plans. However, most current medical image segmentation methods underperform in accurately extracting spatial information from medical images and mining potential complex structures and variations. In this article, we introduce the Rich-U-Net model, which effectively integrates both spatial and depth features. This fusion enhances the model's capability to detect fine structures and intricate details within complex medical images. Our multi-level and multi-dimensional feature fusion and optimization strategies enable our model to achieve fine structure localization and accurate segmentation results in medical image segmentation. Experiments on the ISIC2018, BUSI, GLAS, and CVC datasets show that Rich-U-Net surpasses other state-of-the-art models in Dice, IoU, and HD95 metrics.
No Need For Real Anomaly: MLLM Empowered Zero-Shot Video Anomaly Detection
Feb 22, 2026The collection and detection of video anomaly data has long been a challenging problem due to its rare occurrence and spatio-temporal scarcity. Existing video anomaly detection (VAD) methods under perform in open-world scenarios. Key contributing factors include limited dataset diversity, and inadequate understanding of context-dependent anomalous semantics. To address these issues, i) we propose LAVIDA, an end-to-end zero-shot video anomaly detection framework. ii) LAVIDA employs an Anomaly Exposure Sampler that transforms segmented objects into pseudo-anomalies to enhance model adaptability to unseen anomaly categories. It further integrates a Multimodal Large Language Model (MLLM) to bolster semantic comprehension capabilities. Additionally, iii) we design a token compression approach based on reverse attention to handle the spatio-temporal scarcity of anomalous patterns and decrease computational cost. The training process is conducted solely on pseudo anomalies without any VAD data. Evaluations across four benchmark VAD datasets demonstrate that LAVIDA achieves SOTA performance in both frame-level and pixel-level anomaly detection under the zero-shot setting. Our code is available in https://github.com/VitaminCreed/LAVIDA.
A Machine Learning-Based Multimodal Framework for Wearable Sensor-Based Archery Action Recognition and Stress Estimation
Nov 18, 2025In precision sports such as archery, athletes' performance depends on both biomechanical stability and psychological resilience. Traditional motion analysis systems are often expensive and intrusive, limiting their use in natural training environments. To address this limitation, we propose a machine learning-based multimodal framework that integrates wearable sensor data for simultaneous action recognition and stress estimation. Using a self-developed wrist-worn device equipped with an accelerometer and photoplethysmography (PPG) sensor, we collected synchronized motion and physiological data during real archery sessions. For motion recognition, we introduce a novel feature--Smoothed Differential Acceleration (SmoothDiff)--and employ a Long Short-Term Memory (LSTM) model to identify motion phases, achieving 96.8% accuracy and 95.9% F1-score. For stress estimation, we extract heart rate variability (HRV) features from PPG signals and apply a Multi-Layer Perceptron (MLP) classifier, achieving 80% accuracy in distinguishing high- and low-stress levels. The proposed framework demonstrates that integrating motion and physiological sensing can provide meaningful insights into athletes' technical and mental states. This approach offers a foundation for developing intelligent, real-time feedback systems for training optimization in archery and other precision sports.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
BLAST: A Stealthy Backdoor Leverage Attack against Cooperative Multi-Agent Deep Reinforcement Learning based Systems
Jan 03, 2025



Recent studies have shown that cooperative multi-agent deep reinforcement learning (c-MADRL) is under the threat of backdoor attacks. Once a backdoor trigger is observed, it will perform malicious actions leading to failures or malicious goals. However, existing backdoor attacks suffer from several issues, e.g., instant trigger patterns lack stealthiness, the backdoor is trained or activated by an additional network, or all agents are backdoored. To this end, in this paper, we propose a novel backdoor leverage attack against c-MADRL, BLAST, which attacks the entire multi-agent team by embedding the backdoor only in a single agent. Firstly, we introduce adversary spatiotemporal behavior patterns as the backdoor trigger rather than manual-injected fixed visual patterns or instant status and control the period to perform malicious actions. This method can guarantee the stealthiness and practicality of BLAST. Secondly, we hack the original reward function of the backdoor agent via unilateral guidance to inject BLAST, so as to achieve the \textit{leverage attack effect} that can pry open the entire multi-agent system via a single backdoor agent. We evaluate our BLAST against 3 classic c-MADRL algorithms (VDN, QMIX, and MAPPO) in 2 popular c-MADRL environments (SMAC and Pursuit), and 2 existing defense mechanisms. The experimental results demonstrate that BLAST can achieve a high attack success rate while maintaining a low clean performance variance rate.
A Spatiotemporal Stealthy Backdoor Attack against Cooperative Multi-Agent Deep Reinforcement Learning
Sep 12, 2024



Recent studies have shown that cooperative multi-agent deep reinforcement learning (c-MADRL) is under the threat of backdoor attacks. Once a backdoor trigger is observed, it will perform abnormal actions leading to failures or malicious goals. However, existing proposed backdoors suffer from several issues, e.g., fixed visual trigger patterns lack stealthiness, the backdoor is trained or activated by an additional network, or all agents are backdoored. To this end, in this paper, we propose a novel backdoor attack against c-MADRL, which attacks the entire multi-agent team by embedding the backdoor only in a single agent. Firstly, we introduce adversary spatiotemporal behavior patterns as the backdoor trigger rather than manual-injected fixed visual patterns or instant status and control the attack duration. This method can guarantee the stealthiness and practicality of injected backdoors. Secondly, we hack the original reward function of the backdoored agent via reward reverse and unilateral guidance during training to ensure its adverse influence on the entire team. We evaluate our backdoor attacks on two classic c-MADRL algorithms VDN and QMIX, in a popular c-MADRL environment SMAC. The experimental results demonstrate that our backdoor attacks are able to reach a high attack success rate (91.6\%) while maintaining a low clean performance variance rate (3.7\%).
Power Optimization and Deep Learning for Channel Estimation of Active IRS-Aided IoT
Jul 12, 2024



In this paper, channel estimation of an active intelligent reflecting surface (IRS) aided uplink Internet of Things (IoT) network is investigated. Firstly, the least square (LS) estimators for the direct channel and the cascaded channel are presented, respectively. The corresponding mean square errors (MSE) of channel estimators are derived. Subsequently, in order to evaluate the influence of adjusting the transmit power at the IoT devices or the reflected power at the active IRS on Sum-MSE performance, two situations are considered. In the first case, under the total power sum constraint of the IoT devices and active IRS, the closed-form expression of the optimal power allocation factor is derived. In the second case, when the transmit power at the IoT devices is fixed, there exists an optimal reflective power at active IRS. To further improve the estimation performance, the convolutional neural network (CNN)-based direct channel estimation (CDCE) algorithm and the CNN-based cascaded channel estimation (CCCE) algorithm are designed. Finally, simulation results demonstrate the existence of an optimal power allocation strategy that minimizes the Sum-MSE, and further validate the superiority of the proposed CDCE / CCCE algorithms over their respective traditional LS and minimum mean square error (MMSE) baselines.
Large language models in bioinformatics: applications and perspectives
Jan 08, 2024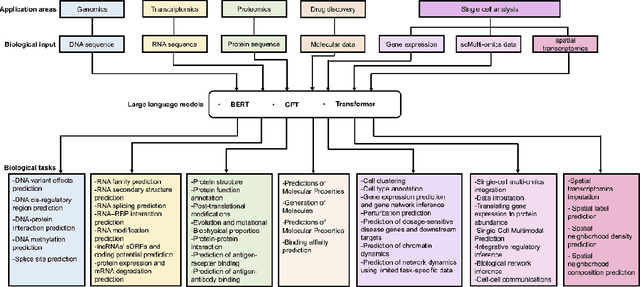
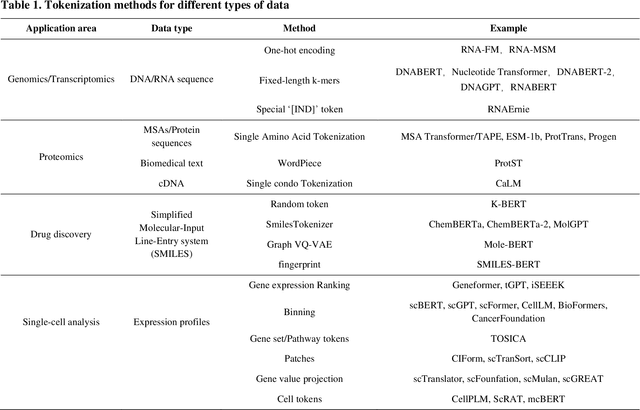
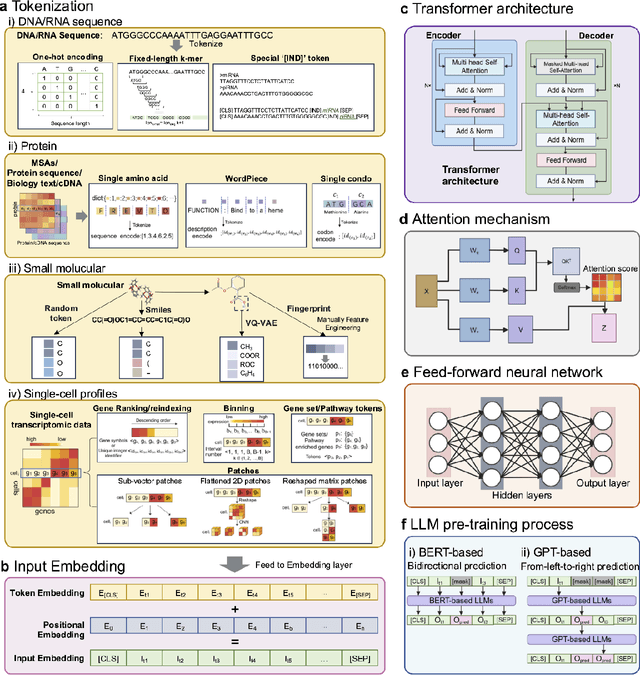
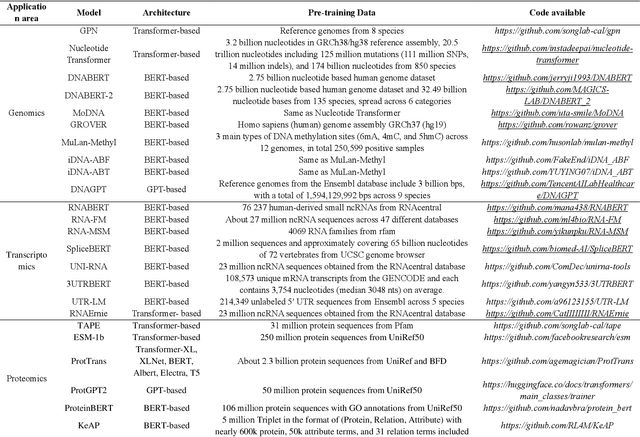
Large language models (LLMs) are a class of artificial intelligence models based on deep learning, which have great performance in various tasks, especially in natural language processing (NLP). Large language models typically consist of artificial neural networks with numerous parameters, trained on large amounts of unlabeled input using self-supervised or semi-supervised learning. However, their potential for solving bioinformatics problems may even exceed their proficiency in modeling human language. In this review, we will present a summary of the prominent large language models used in natural language processing, such as BERT and GPT, and focus on exploring the applications of large language models at different omics levels in bioinformatics, mainly including applications of large language models in genomics, transcriptomics, proteomics, drug discovery and single cell analysis. Finally, this review summarizes the potential and prospects of large language models in solving bioinformatic problems.
Large Multimodal Model Compression via Efficient Pruning and Distillation at AntGroup
Dec 10, 2023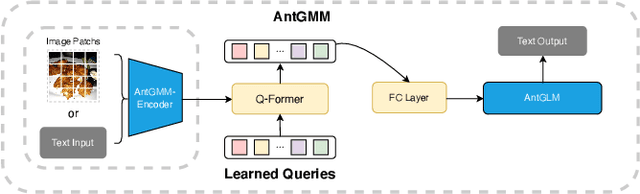

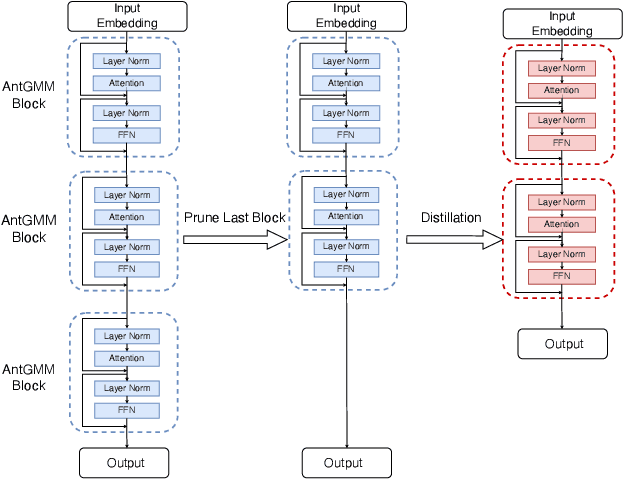

The deployment of Large Multimodal Models (LMMs) within AntGroup has significantly advanced multimodal tasks in payment, security, and advertising, notably enhancing advertisement audition tasks in Alipay. However, the deployment of such sizable models introduces challenges, particularly in increased latency and carbon emissions, which are antithetical to the ideals of Green AI. This paper introduces a novel multi-stage compression strategy for our proprietary LLM, AntGMM. Our methodology pivots on three main aspects: employing small training sample sizes, addressing multi-level redundancy through multi-stage pruning, and introducing an advanced distillation loss design. In our research, we constructed a dataset, the Multimodal Advertisement Audition Dataset (MAAD), from real-world scenarios within Alipay, and conducted experiments to validate the reliability of our proposed strategy. Furthermore, the effectiveness of our strategy is evident in its operational success in Alipay's real-world multimodal advertisement audition for three months from September 2023. Notably, our approach achieved a substantial reduction in latency, decreasing it from 700ms to 90ms, while maintaining online performance with only a slight performance decrease. Moreover, our compressed model is estimated to reduce electricity consumption by approximately 75 million kWh annually compared to the direct deployment of AntGMM, demonstrating our commitment to green AI initiatives. We will publicly release our code and the MAAD dataset after some reviews\footnote{https://github.com/MorinW/AntGMM$\_$Pruning}.
Learning Implicit Entity-object Relations by Bidirectional Generative Alignment for Multimodal NER
Aug 03, 2023



The challenge posed by multimodal named entity recognition (MNER) is mainly two-fold: (1) bridging the semantic gap between text and image and (2) matching the entity with its associated object in image. Existing methods fail to capture the implicit entity-object relations, due to the lack of corresponding annotation. In this paper, we propose a bidirectional generative alignment method named BGA-MNER to tackle these issues. Our BGA-MNER consists of \texttt{image2text} and \texttt{text2image} generation with respect to entity-salient content in two modalities. It jointly optimizes the bidirectional reconstruction objectives, leading to aligning the implicit entity-object relations under such direct and powerful constraints. Furthermore, image-text pairs usually contain unmatched components which are noisy for generation. A stage-refined context sampler is proposed to extract the matched cross-modal content for generation. Extensive experiments on two benchmarks demonstrate that our method achieves state-of-the-art performance without image input during inference.