 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGA-Bench: A Unified Benchmark and Multi-Model Framework for Video Aesthetics and Generation Quality Evaluation
Apr 11, 2026The rapid advancement of AIGC-based video generation has underscored the critical need for comprehensive evaluation frameworks that go beyond traditional generation quality metrics to encompass aesthetic appeal. However, existing benchmarks remain largely focused on technical fidelity, leaving a significant gap in holistic assessment-particularly with respect to perceptual and artistic qualities. To address this limitation, we introduce VGA-Bench, a unified benchmark for joint evaluation of video generation quality and aesthetic quality. VGA-Bench is built upon a principled three-tier taxonomy: Aesthetic Quality, Aesthetic Tagging, and Generation Quality, each decomposed into multiple fine-grained sub-dimensions to enable systematic assessment. Guided by this taxonomy, we design 1,016 diverse prompts and generate a large-scale dataset of over 60,000 videos using 12 video generation models, ensuring broad coverage across content, style, and artifacts. To enable scalable and automated evaluation, we annotate a subset of the dataset via human labeling and develop three dedicated multi-task neural assessors: VAQA-Net for aesthetic quality prediction, VTag-Net for automatic aesthetic tagging, and VGQA-Net for generation and basic quality attributes. Extensive experiments demonstrate that our models achieve reliable alignment with human judgments, offering both accuracy and efficiency. We release VGA-Bench as a public benchmark to foster research in AIGC evaluation, with applications in content moderation, model debugging, and generative model optimization.
A Directional-Derivative-Constrained Method for Continuously Steerable Differential Beamformers with Uniform Circular Arrays
Feb 26, 2026Differential microphone arrays offer a promising solution for far-field acoustic signal acquisition due to their high spatial directivity and compact array structure. A key challenge lies in designing differential beamformers that are continuously steerable and capable of enhancing target signals arriving from arbitrary directions. This paper studies the design of differential beamformers for circular arrays and proposes a novel framework that incorporates directional derivative constraints. By constraining the first-order derivatives of the beampattern at the desired steering direction to zero and assigning suitable values to higher-order derivatives, the beamformer is ensured to achieve its maximum response in the target direction and provide sufficient beam steering. This approach not only improves steering flexibility but also enables a more intuitive and robust beampattern design. Simulation results demonstrate that the proposed method produces continuously steerable beampatterns.
TriC-Motion: Tri-Domain Causal Modeling Grounded Text-to-Motion Generation
Feb 09, 2026Text-to-motion generation, a rapidly evolving field in computer vision, aims to produce realistic and text-aligned motion sequences. Current methods primarily focus on spatial-temporal modeling or independent frequency domain analysis, lacking a unified framework for joint optimization across spatial, temporal, and frequency domains. This limitation hinders the model's ability to leverage information from all domains simultaneously, leading to suboptimal generation quality. Additionally, in motion generation frameworks, motion-irrelevant cues caused by noise are often entangled with features that contribute positively to generation, thereby leading to motion distortion. To address these issues, we propose Tri-Domain Causal Text-to-Motion Generation (TriC-Motion), a novel diffusion-based framework integrating spatial-temporal-frequency-domain modeling with causal intervention. TriC-Motion includes three core modeling modules for domain-specific modeling, namely Temporal Motion Encoding, Spatial Topology Modeling, and Hybrid Frequency Analysis. After comprehensive modeling, a Score-guided Tri-domain Fusion module integrates valuable information from the triple domains, simultaneously ensuring temporal consistency, spatial topology, motion trends, and dynamics. Moreover, the Causality-based Counterfactual Motion Disentangler is meticulously designed to expose motion-irrelevant cues to eliminate noise, disentangling the real modeling contributions of each domain for superior generation. Extensive experimental results validate that TriC-Motion achieves superior performance compared to state-of-the-art methods, attaining an outstanding R@1 of 0.612 on the HumanML3D dataset. These results demonstrate its capability to generate high-fidelity, coherent, diverse, and text-aligned motion sequences. Code is available at: https://caoyiyang1105.github.io/TriC-Motion/.
GO-MLVTON: Garment Occlusion-Aware Multi-Layer Virtual Try-On with Diffusion Models
Jan 20, 2026Existing Image-based virtual try-on (VTON) methods primarily focus on single-layer or multi-garment VTON, neglecting multi-layer VTON (ML-VTON), which involves dressing multiple layers of garments onto the human body with realistic deformation and layering to generate visually plausible outcomes. The main challenge lies in accurately modeling occlusion relationships between inner and outer garments to reduce interference from redundant inner garment features. To address this, we propose GO-MLVTON, the first multi-layer VTON method, introducing the Garment Occlusion Learning module to learn occlusion relationships and the StableDiffusion-based Garment Morphing & Fitting module to deform and fit garments onto the human body, producing high-quality multi-layer try-on results. Additionally, we present the MLG dataset for this task and propose a new metric named Layered Appearance Coherence Difference (LACD) for evaluation. Extensive experiments demonstrate the state-of-the-art performance of GO-MLVTON. Project page: https://upyuyang.github.io/go-mlvton/.
Robust Online Overdetermined Independent Vector Analysis Based on Bilinear Decomposition
Jan 18, 2026Online blind source separation is essential for both speech communication and human-machine interaction. Among existing approaches, overdetermined independent vector analysis (OverIVA) delivers strong performance by exploiting the statistical independence of source signals and the orthogonality between source and noise subspaces. However, when applied to large microphone arrays, the number of parameters grows rapidly, which can degrade online estimation accuracy. To overcome this challenge, we propose decomposing each long separation filter into a bilinear form of two shorter filters, thereby reducing the number of parameters. Because the two filters are closely coupled, we design an alternating iterative projection algorithm to update them in turn. Simulation results show that, with far fewer parameters, the proposed method achieves improved performance and robustness.
3SGen: Unified Subject, Style, and Structure-Driven Image Generation with Adaptive Task-specific Memory
Dec 22, 2025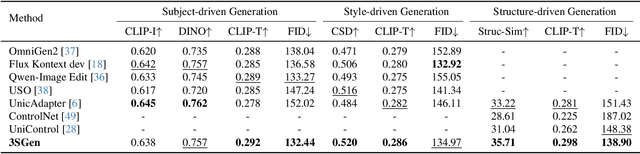
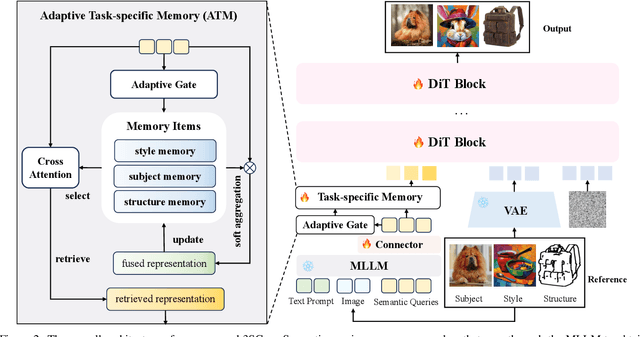
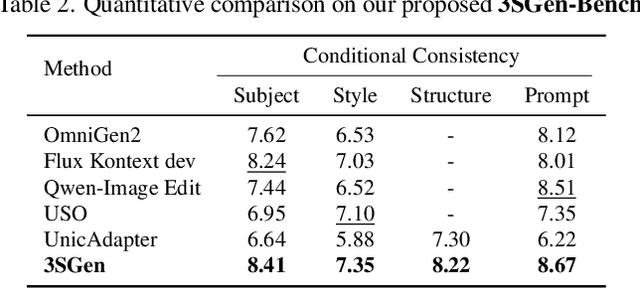
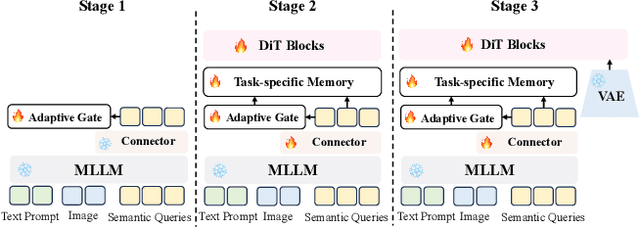
Recent image generation approaches often address subject, style, and structure-driven conditioning in isolation, leading to feature entanglement and limited task transferability. In this paper, we introduce 3SGen, a task-aware unified framework that performs all three conditioning modes within a single model. 3SGen employs an MLLM equipped with learnable semantic queries to align text-image semantics, complemented by a VAE branch that preserves fine-grained visual details. At its core, an Adaptive Task-specific Memory (ATM) module dynamically disentangles, stores, and retrieves condition-specific priors, such as identity for subjects, textures for styles, and spatial layouts for structures, via a lightweight gating mechanism along with several scalable memory items. This design mitigates inter-task interference and naturally scales to compositional inputs. In addition, we propose 3SGen-Bench, a unified image-driven generation benchmark with standardized metrics for evaluating cross-task fidelity and controllability. Extensive experiments on our proposed 3SGen-Bench and other public benchmarks demonstrate our superior performance across diverse image-driven generation tasks.
ARGenSeg: Image Segmentation with Autoregressive Image Generation Model
Oct 23, 2025
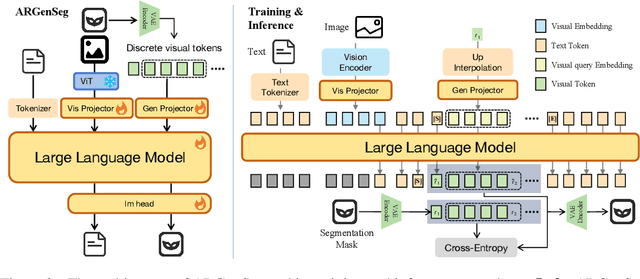
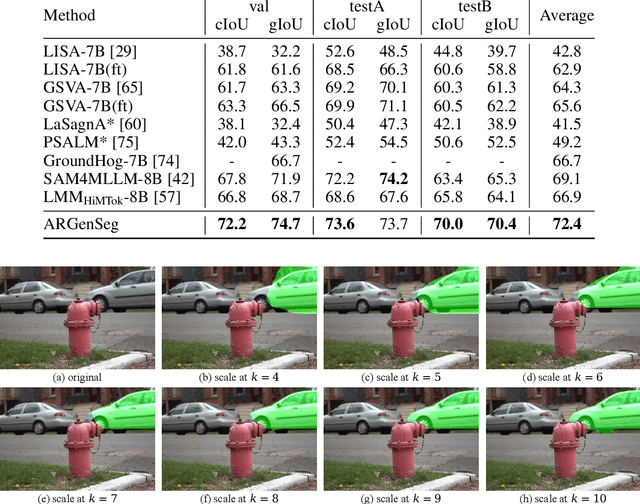

We propose a novel AutoRegressive Generation-based paradigm for image Segmentation (ARGenSeg), achieving multimodal understanding and pixel-level perception within a unified framework. Prior works integrating image segmentation into multimodal large language models (MLLMs) typically employ either boundary points representation or dedicated segmentation heads. These methods rely on discrete representations or semantic prompts fed into task-specific decoders, which limits the ability of the MLLM to capture fine-grained visual details. To address these challenges, we introduce a segmentation framework for MLLM based on image generation, which naturally produces dense masks for target objects. We leverage MLLM to output visual tokens and detokenize them into images using an universal VQ-VAE, making the segmentation fully dependent on the pixel-level understanding of the MLLM. To reduce inference latency, we employ a next-scale-prediction strategy to generate required visual tokens in parallel. Extensive experiments demonstrate that our method surpasses prior state-of-the-art approaches on multiple segmentation datasets with a remarkable boost in inference speed, while maintaining strong understanding capabilities.
PruneHal: Reducing Hallucinations in Multi-modal Large Language Models through Adaptive KV Cache Pruning
Oct 22, 2025While multi-modal large language models (MLLMs) have made significant progress in recent years, the issue of hallucinations remains a major challenge. To mitigate this phenomenon, existing solutions either introduce additional data for further training or incorporate external or internal information during inference. However, these approaches inevitably introduce extra computational costs. In this paper, we observe that hallucinations in MLLMs are strongly associated with insufficient attention allocated to visual tokens. In particular, the presence of redundant visual tokens disperses the model's attention, preventing it from focusing on the most informative ones. As a result, critical visual cues are often under-attended, which in turn exacerbates the occurrence of hallucinations. Building on this observation, we propose \textbf{PruneHal}, a training-free, simple yet effective method that leverages adaptive KV cache pruning to enhance the model's focus on critical visual information, thereby mitigating hallucinations. To the best of our knowledge, we are the first to apply token pruning for hallucination mitigation in MLLMs. Notably, our method don't require additional training and incurs nearly no extra inference cost. Moreover, PruneHal is model-agnostic and can be seamlessly integrated with different decoding strategies, including those specifically designed for hallucination mitigation. We evaluate PruneHal on several widely used hallucination evaluation benchmarks using four mainstream MLLMs, achieving robust and outstanding results that highlight the effectiveness and superiority of our method. Our code will be publicly available.
CasP: Improving Semi-Dense Feature Matching Pipeline Leveraging Cascaded Correspondence Priors for Guidance
Jul 23, 2025Semi-dense feature matching methods have shown strong performance in challenging scenarios. However, the existing pipeline relies on a global search across the entire feature map to establish coarse matches, limiting further improvements in accuracy and efficiency. Motivated by this limitation, we propose a novel pipeline, CasP, which leverages cascaded correspondence priors for guidance. Specifically, the matching stage is decomposed into two progressive phases, bridged by a region-based selective cross-attention mechanism designed to enhance feature discriminability. In the second phase, one-to-one matches are determined by restricting the search range to the one-to-many prior areas identified in the first phase. Additionally, this pipeline benefits from incorporating high-level features, which helps reduce the computational costs of low-level feature extraction. The acceleration gains of CasP increase with higher resolution, and our lite model achieves a speedup of $\sim2.2\times$ at a resolution of 1152 compared to the most efficient method, ELoFTR. Furthermore, extensive experiments demonstrate its superiority in geometric estimation, particularly with impressive cross-domain generalization. These advantages highlight its potential for latency-sensitive and high-robustness applications, such as SLAM and UAV systems. Code is available at https://github.com/pq-chen/CasP.
VideoMAR: Autoregressive Video Generatio with Continuous Tokens
Jun 18, 2025Masked-based autoregressive models have demonstrated promising image generation capability in continuous space. However, their potential for video generation remains under-explored. In this paper, we propose \textbf{VideoMAR}, a concise and efficient decoder-only autoregressive image-to-video model with continuous tokens, composing temporal frame-by-frame and spatial masked generation. We first identify temporal causality and spatial bi-directionality as the first principle of video AR models, and propose the next-frame diffusion loss for the integration of mask and video generation. Besides, the huge cost and difficulty of long sequence autoregressive modeling is a basic but crucial issue. To this end, we propose the temporal short-to-long curriculum learning and spatial progressive resolution training, and employ progressive temperature strategy at inference time to mitigate the accumulation error. Furthermore, VideoMAR replicates several unique capacities of language models to video generation. It inherently bears high efficiency due to simultaneous temporal-wise KV cache and spatial-wise parallel generation, and presents the capacity of spatial and temporal extrapolation via 3D rotary embeddings. On the VBench-I2V benchmark, VideoMAR surpasses the previous state-of-the-art (Cosmos I2V) while requiring significantly fewer parameters ($9.3\%$), training data ($0.5\%$), and GPU resources ($0.2\%$).